JAVA内存泄漏和内存溢出
1 内存泄漏(memory leak)
内存泄漏是指你向系统申请分配内存进行使用(allocate),可是使用完了以后却不归还(delete),结果你申请到的那块内存你自己也不能再访问(也许你把它的地址给弄丢了),而系统也不能再次将它分配给需要的程序。
内存泄漏有两个前提,才能被称为内存泄漏:
- 这个对象或者这块内存,逻辑上已经不再使用了,或者说我们认为它本应该被清理回收掉。
- 但因为还有引用指向它,导致无法被gc回收。
如果同时这个对象或者内存比较大,那就是比较明显的内存泄漏的,影响会大很多。
一次内存泄漏似乎不会有大的影响,但内存泄漏堆积后的后果就是内存溢出。
1.1 内存泄漏的分类
以发生的方式来分类,内存泄漏可以分为4类:
- 常发性内存泄漏。发生内存泄漏的代码会被多次执行到,每次被执行的时候都会导致一块内存泄漏。
- 偶发性内存泄漏。发生内存泄漏的代码只有在某些特定环境或操作过程下才会发生。常发性和偶发性是相对的。对于特定的环境,偶发性的也许就变成了常发性的。所以测试环境和测试方法对检测内存泄漏至关重要。
- 一次性内存泄漏。发生内存泄漏的代码只会被执行一次,或者由于算法上的缺陷,导致总会有一块仅且一块内存发生泄漏。比如,在类的构造函数中分配内存,在析构函数中却没有释放该内存,所以内存泄漏只会发生一次。
- 隐式内存泄漏。程序在运行过程中不停的分配内存,但是直到结束的时候才释放内存。严格的说这里并没有发生内存泄漏,因为最终程序释放了所有申请的内存。但是对于一个服务器程序,需要运行几天,几周甚至几个月,不及时释放内存也可能导致最终耗尽系统的所有内存。所以,我们称这类内存泄漏为隐式内存泄漏。
从用户使用程序的角度来看,内存泄漏本身不会产生什么危害,作为一般的用户,根本感觉不到内存泄漏的存在。真正有危害的是内存泄漏的堆积,这会最终消耗尽系统所有的内存。从这个角度来说,一次性内存泄漏并没有什么危害,因为它不会堆积,而隐式内存泄漏危害性则非常大,因为较之于常发性和偶发性内存泄漏它更难被检测到。
1.2 内存泄漏的原因
内存泄漏可能至少有如下这些原因:
- static关键字:
- static关键字使一个变量变为只和这个类相关的类变量。他的生命周期很长,贯穿jvm的启动到关闭。如果在逻辑上该字段修饰的数据已经被弃用了,但因为它被static修饰,那就发生了内存泄漏,尤其是当static修饰的引用指向一个大对象的时候。
- 内部类:
- 内部类有个特性,是他会持有一个外部类的引用。如果内部类的实例一直存活,那么外部类的实例也就一直存在,此时如果外部类持有大对象,那么也就发生了内存泄漏。
- 第三方库:
- 我们平时会用到很多第三方库,比如ButterKnife、EventBus、RxJava等等,在使用的时候,都有一个先registerd或者bind的操作,如果注册或者绑定的是一个大对象,并且结束时没有unregister或者unbind,就会容易造成内存泄漏。
- 集合类:
- 我们平常使用的list/map等集合类,里面的元素如果不remove(),就会一直被集合类对象引用,而如果此时集合类对象如果又恰好是static的或者长期被引用的,那么集合类中的元素就会一直存在,即便我们早就不使用它们了。
1.3 内存泄漏的检测工具
- Compuware DevPartner Java Edition-包含Java内存检测,代码覆盖率测试,代码性能测试,线程死锁,分布式应用等几大功能模块。
- Quest JProbe-分析Java的内存泄漏。
- ej-technologies JProfiler-一个全功能的Java剖析工具,专用于分析J2SE和J2EE应用程序。它把CPU、执行绪和内存的剖析组合在一个强大的应用中。
- BEA JRockit-用来诊断Java内存泄漏并指出根本原因,专门针对Intel平台并得到优化,能在Intel硬件上获得最高的性能。
2 内存溢出(out of memory)
指程序申请内存时,没有足够的内存供申请者使用,或者说,你需要一块存储long类型的数据的存储空间,但是却给了你一块存储int类型数据的空间,那么结果就是内存不够用,此时就会报错OutOfMemoryError(简称OOM),即所谓的内存溢出。
严重的内存泄漏,或者内存泄漏的堆积,可能会造成OOM的发生,但我们需要注意的是:
- 并非所有OOM都意味着由内存泄漏引起,它可能只是单纯的由于生成大量局部变量或其他此类事件导致。
- 另一方面,并非所有内存泄漏都必然表现为OOM。
1.2 内存溢出的原因
引起内存溢出的原因有至少以下几种:
- 内存中加载的数据量过于庞大,如一次从数据库取出过多数据;超出了系统可以提供的存储空间。
- 内存泄漏的堆积;
- 代码中存在死循环或循环产生过多重复的对象实体;
- 代码中存在不断的递归,大量的栈空间消耗了剩下的内存;
- 使用的第三方软件中的BUG;
- 启动参数内存值设定的过小;
注意,递归时如果报StackOverFlowError,是表示调用栈深度超过限制。如果报OOM,则是栈深度还为超限,但JVM试图去扩展栈空间的的时候失败。
1.3 内存溢出的类型
OOM是内存溢出的常见指示,当没有足够的空间来分配新对象时,会抛出错误。当垃圾收集器找不到必要的空间,并且堆不能进一步扩展,会多次尝试。因此,会出现错误以及堆栈跟踪。
诊断OOM的第一步是确定错误的实际含义。这听起来很清晰,但答案并不总是那么清晰。例如:OOM是否是因为Java堆已满而出现,还是因为本机堆已满?为了帮助您回答这个问题,让我们分析一些可能的错误消息:
- java.lang.OutOfMemoryError: Java heap space
- java.lang.OutOfMemoryError: PermGen space(jdk 1.8前)
- java.lang.OutOfMemoryError: Metaspace
- java.lang.OutOfMemoryError: Requested array size exceeds VM limit
- java.lang.OutOfMemoryError: request bytes for . Out of swap space?
- java.lang.OutOfMemoryError: (Native method)
- java.lang.OutOfMemoryError: Direct buffer memory
- java.lang.OutOfMemoryError: Kill process or sacrifice child
1.3.1 Java heap space
当出现java.lang.OutOfMemoryError:Java heap space异常时,就是堆内存溢出了。
堆内存溢出的原因可能有如下几点:
- 大的对象的申请
- 大文件上传
- 大批量从数据库中获取数据
- 从JDK8开始,String常量池放入了堆,如果不同的String数量太多,也会发生堆内存溢出。
首先,如果代码没有什么问题的情况下,可以适当调整-Xms和-Xmx两个jvm参数,使用压力测试来调整这两个参数达到最优值。
其次,尽量避免大的对象的申请,像文件上传,大批量从数据库中获取,这是需要避免的,尽量分块或者分批处理,有助于系统的正常稳定的执行。
最后,尽量提高一次请求的执行速度,垃圾回收越早越好,否则,大量的并发来了的时候,再来新的请求就无法分配内存了,就容易造成系统的雪崩。
1.3.2 PermGen space
当出现java.lang.OutOfMemoryError: PermGen space异常时,这里的PermGen space其实指的是方法区。
方法区是VM的规范,所有虚拟机必须遵守的。常见的JVM虚拟机Hotspot、JRockit(Oracle)、J9(IBM)都要实现自己的方法区。
PermGen space永久代则是HotSpot虚拟机基于JVM规范对方法区的一个落地实现,并且只有HotSpot才有PermGen space。不过在JDK8及以后,Metaspace元空间成为了HotSpot虚拟机对方法区的新的实现,替换了PermGen space。
不过元空间与永久代之间最大的区别在于:元空间并不在虚拟机中,而是使用本地内存。
由于永久代是存储类和方法对象的区域,那么永久代OOM的原因可能是:
- 系统的代码非常多,要存储的类的相关信息太多,导致内存溢出。
- 引用的第三方包非常多,要存储的类的相关信息太多,导致内存溢出。
- 通过动态代码生成类加载等方法(如生成jsp页面),导致永久代的内存占用很大。
- 生成的String太多,导致字符串常量池膨胀。
如果代码没有什么问题的情况下,可以适当调整-MaxPermGenjvm参数。
值得注意的是,移除PermGen的工作从JDK7就开始了,永久代的部分数据在JDK7就已经转移到了Java Heap或者是Native Heap。
- 字面量(interned strings),转移到Java heap;
- 类的静态变量(class statics)转移到Java heap;
- 符号引用(Symbols)转移到Native heap;
- 运行时常量池,比如String常量池等,转移到Java heap;
所以如果是JDK7版本中报错OOM:PermGen space,那么至少可以排除上述几项数据发生溢出的可能。
1.3.3 Metaspace
当出现java.lang.OutOfMemoryError:Metaspace异常时,就是元空间溢出了。
前文我们说过,在JDK8及以后,Metaspace元空间成为了HotSpot虚拟机对方法区的新的实现,替换了PermGen space。元空间并不在虚拟机中,而是使用本地内存。
由于Metaspace元空间是存储类和方法对象的区域,那么元空间OOM的原因可能是:
- 系统的代码非常多,要存储的类的相关信息太多,导致内存溢出。
- 引用的第三方包非常多,要存储的类的相关信息太多,导致内存溢出。
- 通过动态代码生成类加载等方法(如生成jsp页面),导致元空间的内存占用很大。
我们可以优化参数配置来解决元空间溢出的问题,默认情况下,元空间的大小仅受本地内存限制。但是为了整机的性能,尽量还是要对该项进行设置,以免造成整机的服务停机。
-XX:MetaspaceSize,设置初始空间大小,达到该值就会触发垃圾收集进行类型卸载,同时GC会对该值进行调整:如果释放了大量的空间,就适当降低该值;如果释放了很少的空间,那么在不超过MaxMetaspaceSize时,适当提高该值。-XX:MaxMetaspaceSize,设置最大空间,默认是没有限制的。
除了上面两个指定大小的选项以外,还有两个与GC相关的属性:
-XX:MinMetaspaceFreeRatio,在GC之后,最小的Metaspace剩余空间容量的百分比,减少为分配空间所导致的垃圾收集。-XX:MaxMetaspaceFreeRatio,在GC之后,最大的Metaspace剩余空间容量的百分比,减少为释放空间所导致的垃圾收集。
除此之外,慎重引用第三方包,以及关注动态生成类的框架,也是有效的解决方法。
1.3.3 Requested array size exceeds VM limit
有的时候会碰到这种内存溢出的描述Requested array size exceeds VM limit,一般来说java对应用程序所能分配数组最大大小是有限制的,只不过不同的平台限制有所不同,但通常在1到21亿个元素之间。
当Requested array size exceeds VM limit错误出现时,意味着应用程序试图分配大于Java虚拟机可以支持的数组。JVM在为数组分配内存之前,会执行特定平台的检查:分配的数据结构是否在此平台是可寻址的。
因此数组长度要在平台允许的长度范围之内。不过这个错误一般少见的,主要是由于Java数组的索引是int类型。Java中的最大正整数为2 ^ 31 - 1 = 2,147,483,647,而平台特定的限制非常接近这个数字。
1.3.4 Request bytes for . Out of swap space
此消息似乎是一个OOM,当本地堆的分配失败并且本地堆可能将被耗尽时,HotSpot VM会抛出此异常。消息中包括失败请求的大小(以字节为单位)以及内存请求的原因。在大多数情况下,是报告分配失败的源模块的名称。
如果抛出此类型的OOM,则可能需要在操作系统上使用故障排除实用程序来进一步诊断问题。在某些情况下,问题甚至可能与应用程序无关。例如,您可能会在以下情况下看到此错误:
- 操作系统配置的交换空间不足。
- 系统上的另一个进程消耗了所有可用的内存资源。
- 由于本机泄漏,应用程序也可能失败(例如,如果某些应用程序或库代码不断分配内存但无法将其释放到操作系统)。
1.3.5 Native method
java.lang.OutOfMemoryError: (Native method)
如果您看到此错误消息并且堆栈跟踪的顶部框架是本地方法,则该本地方法遇到分配失败。此消息与上一个消息之间的区别在于,在JNI或本地方法中检测到Java内存分配失败,而不是在Java VM代码中检测到。
如果抛出此类型的OOM,您可能需要在操作系统上使用实用程序来进一步诊断问题。
1.3.6 Direct buffer memory
在使用ByteBuffer中的allocateDirect()这类申请直接内存空间的时候可能会遇到,这类申请直接内存空间的方法在java NIO(像netty)等框架中被经常使用,出现该问题时会抛出java.lang.OutOfMemoryError: Direct buffer memory异常。
如果你在直接或间接使用了ByteBuffer中的allocateDirect方法,却没有clear的时候就会出现类似的问题。
如果经常有类似的操作,可以考虑设置参数:-XX:MaxDirectMemorySize,并及时clear内存。
1.3.7 Kill process or sacrifice child
在描述该问题之前,先熟悉一点操作系统的知识:操作系统是建立在进程的概念之上,这些进程在内核中作业,其中有一个非常特殊的进程,称为内存杀手(Out of memory killer)。当内核检测到系统内存不足时,OOM killer被激活,检查当前谁占用内存最多然后将该进程杀掉。
一般Out of memory:Kill process or sacrifice child报错会出现在可用虚拟内存(包括交换空间)消耗到让整个操作系统面临风险时。在这种情况下,OOM Killer会选择流氓进程并杀死它。
Spring的循环依赖和三级缓存
1. 循环依赖
循环依赖其实就是循环引用,也就是两个或则两个以上的bean互相持有对方,最终形成闭环。比如A依赖于B,B依赖于C,C又依赖于A。如下图:
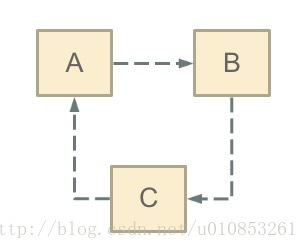
注意,这里不是函数的循环调用,是对象的相互依赖关系。循环调用其实就是一个死循环,除非有终结条件。
循环依赖就是N个类中循环嵌套引用,如果在日常开发中我们用new 对象的方式发生这种循环依赖的话程序会在运行时一直循环调用,直至内存溢出报错。
2. Spring循环依赖的场景
常规Java的循环依赖有两个场景:
- 构造器的循环依赖。
- field属性的循环依赖。
如果是Spring的依赖注入场景的话,field属性的循环依赖还可以分为
- 单例bean的循环依赖(scope=singleton)
- 非单例bean的循环依赖(scope=prototype)。
2.1 构造器的循环依赖
构造器的循环依赖代码如下:
1 |
|
我们如果启动Spring的初始化流程,最后执行得到的报错是:
1 | Caused by: org.springframework.beans.factory.BeanCurrentlyInCreationException: |
2.2 属性的循环依赖
属性的依赖,我们都知道是Spring利用反射,调用了对应属性的setter方式进行注入的。
2.2.1 单例属性的循环依赖
我们知道,Spring中@Service和@Autowired注解都是默认的单例模式,即scope=singleton。
1 |
|
结果:项目启动成功。
2.2.1 原型属性的循环依赖
ok,单例属性的循环依赖是被允许的,那么原型模式呢?我们添加一个scope=prototype的注解:
1 |
|
结果:项目启动失败,发现了一个cycle:
1 | Caused by: org.springframework.beans.factory.BeanCurrentlyInCreationException: |
3 原因分析
3.1 bean的初始化
在Spring中,同样对于循环依赖的场景,构造器注入和prototype类型的属性注入都会初始化Bean失败。只有单例的属性注入是可以成功的,这是为什么呢?
原因就藏在Spring IOC的源码中。
我们知道Bean的初始化流程如下图所示:
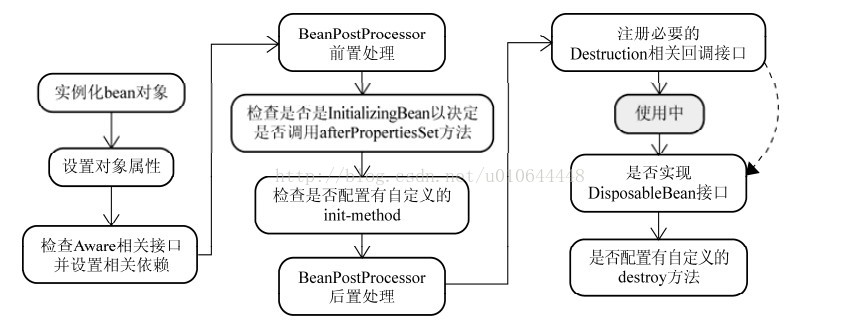
这里面最重要的是如下三步:
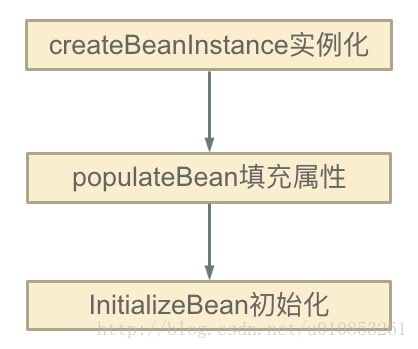
分别对应Spring源码中的这三个方法:
createBeanInstance()方法:实例化,其实也就是调用对象的构造方法实例化对象,或者说Spring利用反射,new了一个对象。
populateBean()方法:填充属性,这一步主要是多bean的依赖属性进行填充。
initializeBean()方法:调用spring xml中的init方法,不过这个和循环依赖无关,我们不多解释。
可以看到,Spring是先将Bean对象实例化之后再设置对象属性的。
3.2 三级缓存
我们知道了在Spring中对象实例化和对象属性填充是分成两步来操作的,为了解决循环依赖,Spring内部维护了三个Map,也就是我们通常说的三级缓存。
笔者翻阅Spring文档倒是没有找到三级缓存的概念,可能也是本土为了方便理解的词汇。
三级缓存在DefaultListableBeanFactory类中(继承自其父类DefaultSingletonBeanRegistry):
1 | /** Cache of singleton objects: bean name --> bean instance(缓存单例实例化对象的Map集合) 一级缓存*/ |
因为在Spring中,对象实例化和对象属性填充是分成两步来操作的,那么很显然,一个bean可以被分成两个阶段,名字是我自己取的:
- 胚胎阶段:即已经new出了一个对象,但是还没完成populateBean()方法,依赖的属性还未填充完毕的阶段。
- 成熟阶段:即完成populateBean()方法,依赖的属性已经填充完毕的阶段,此时对象就已经是一个成熟的对象了。
所以对应的,不同阶段的bean,会被存放在不同级别的缓存中,三级缓存因此而来:
- singletonFactories:三级缓存,保存胚胎阶段对象的工厂类。
- earlySingletonObjects:二级缓存,保存胚胎阶段的对象。
- singletonObjects:一级缓存,俗称单例池或者容器。构造完成的成熟阶段的单例对象都在里面。
这三个缓存中,三级缓存和循环依赖息息相关,那么Spring如何利用三级缓存来解决循环依赖呢?我们来理一下整个初始化bean的全过程。
Spring初始化容器对象的代码在org.springframework.context.support.AbstractApplicationContext#refresh()中方法,它调用finishBeanFactoryInitialization(beanFactory)方法,进而调用了org.springframework.beans.factory.support.DefaultListableBeanFactory#preInstantiateSingletons()方法,该方法顾名思义,负责遍历注册的beanName,依次初始化所有非懒加载的单例bean。
1 | public void preInstantiateSingletons() throws BeansException { |
AbstractBeanFactory.getBean(beanName)是核心方法,它调用的是AbstractBeanFactory.doGetBean(beanName)方法,初始化bean的逻辑就在其中。
1 | ("unchecked") |
其中,重点的方法DefaultSingletonBeanRegistry.getSingleton(beanName),我们可以看下逻辑:
1 | protected Object getSingleton(String beanName, boolean allowEarlyReference) { |
doGetBean()方法里面逻辑很多,我们简单描述其调用堆栈(只列出和循环依赖相关的堆栈):
- 1 DefaultSingletonBeanRegistry.getSingleton(beanName)
- 1.1【尝试从一级缓存取中bean,如果取到就返回】
- 1.2【如果取不到,就加锁,从二级缓存取,如果取到就返回】
- 1.3【如果取不到,再从三级缓存中取到ObjectFactory对象,如果取到了】
- 1.3.1 ObjectFactory.getObject() // 通过factory类获取bean对象
- 1.3.2【从三级缓存中删除该bean的工厂类,并将得到的bean对象加入二级缓存】
- 1.4【如果取不到ObjectFactory对象,返回null】
- 2 【如果getSingleton(beanName)返回的null】
- 【如果该bean是单例】
- DefaultSingletonBeanRegistry.getSingleton(beanName,factory) // 该方法负责实例化bean。factory的getObject()调用createBean
- ①【将当前bean放入singletonsCurrentlyInCreation这个Set中,表示该bean正在创建】
- ② ObjectFactory.getObject() // 调用工厂方法,获取bean对象
- AbstractAutowireCapableBeanFactory.createBean() // 创建对象
- AbstractAutowireCapableBeanFactory.doCreateBean() // 实际方法
- ⑴ AbstractAutowireCapableBeanFactory.createBeanInstance()
- AbstractAutowireCapableBeanFactory.instantiateBean() // 实例化bean
- ⑵ 【如果当前bean是创建中的(当前bean是否在singletonsCurrentlyInCreation中来判断)单例bean,且Spring配置支持循环依赖】
- DefaultSingletonBeanRegistry.addSingletonFactory() // 将bean加入三级缓存。factory的getObject()调用getEarlyBeanReference
- ⑶ AbstractAutowireCapableBeanFactory.populateBean() // 填充依赖的属性
- AutowiredAnnotationBeanPostProcessor.postProcessPropertyValues() // 对属性进行赋值
- AutowiredAnnotationBeanPostProcessor.AutowiredFieldElement.inject() // 依赖注入
- AbstractBeanFactory.getBean(B)
- …
- …
- …
- AbstractBeanFactory.getBean(B)
- AutowiredAnnotationBeanPostProcessor.AutowiredFieldElement.inject() // 依赖注入
- AutowiredAnnotationBeanPostProcessor.postProcessPropertyValues() // 对属性进行赋值
- ⑴ AbstractAutowireCapableBeanFactory.createBeanInstance()
- AbstractAutowireCapableBeanFactory.doCreateBean() // 实际方法
- AbstractAutowireCapableBeanFactory.createBean() // 创建对象
- ③【将当前bean从singletonsCurrentlyInCreation这个Set中删除,表示该bean完成创建】
- ④【将当前bean加入一级缓存中,并且在二级三级缓存中删除该bean】
- DefaultSingletonBeanRegistry.getSingleton(beanName,factory) // 该方法负责实例化bean。factory的getObject()调用createBean
- 【如果该bean是单例】
如果populateBean()方法中A bean依赖了B bean,那么就会进入AbstractBeanFactory.getBean(B)的逻辑,于是,整个流程如下图:

3.3 三种循环依赖的总结
所以我们可以看到,单例的属性注入流程中有两个重点,就是这两个点,解决了循环依赖:
提前曝光,如果用c语言的说法就是将指针曝光出去,用java就是将引用对象曝光出去。也就是说即便a对象还未创建完成,但是在实例化过程中new A()动作完成后,A bean就已经被放进了缓存之中,接下来B bean就可以引用的到。
已经了解了提前曝光的作用,而相比而言曝光的时机也非常的重要,该时机发生在实例化之后,填充属性初始化之前。
正是因为属性注入(或者说set方法注入)时,实例化和初始化是分开的两步,所以才能让Spring有可乘之机,在这两个步骤之间做提前曝光,这才有了Spring能够支持set方法注入时循环依赖的结论。
而构造器的循环依赖Spring之所以不支持,也正是因为此时实例化和初始化是原子的一个步骤,没有办法在中间插入提前曝光的机会。
构造器注入的报错如下图:
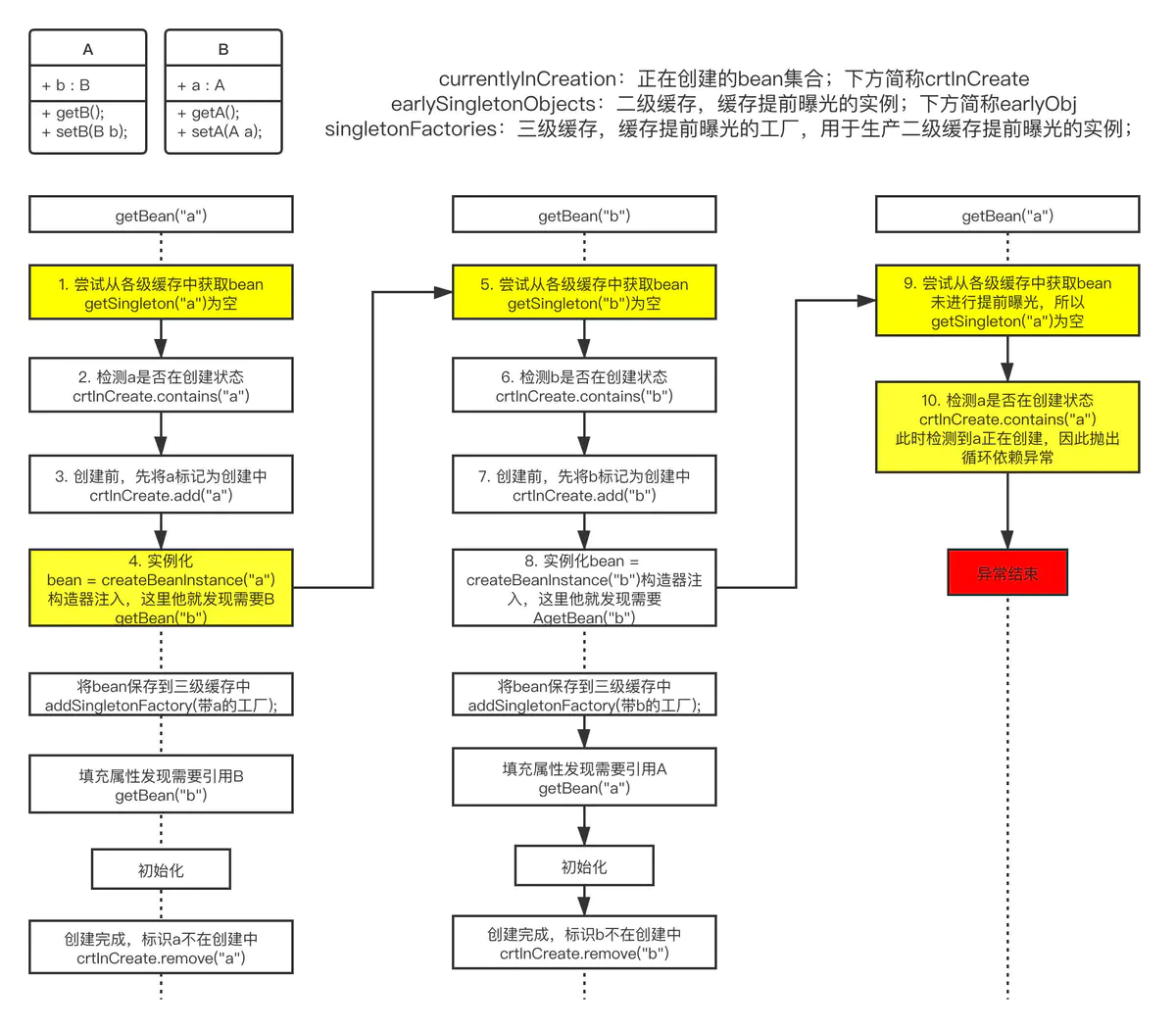
至于原型模式下的循环依赖,其实很好理解,因为原型模式每次都是重新生成一个全新的bean,根本没有缓存一说。这将导致实例化A完,填充发现需要B,实例化B完又发现需要A,而每次的A又都要不一样,所以死循环的依赖下去。
唯一的做法就是利用循环依赖检测,发现原型模式下存在循环依赖并抛出异常。
AbstractBeanFactory工厂类有个Set,叫做prototypesCurrentlyInCreation,它和前文中描述的singletonsCurrentlyInCreation一样,用来存放正在创建中的bean对象,只不过前者存的是原型模式的bean,后者存的是单例模式的bean。
Spring会在实例化prototype bean后将其放入prototypesCurrentlyInCreation中,如果有循环依赖,就会检查被依赖的bean是否也在prototypesCurrentlyInCreation中,如果是,那就表示依赖的bean和被依赖的bean同时在创建中,那就发生了循环依赖,这是不允许的。
1 | if (isPrototypeCurrentlyInCreation(beanName)) { |
3.4 为什么要有三级缓存
经过前文的叙述,我们貌似发现,三级缓存和二级缓存,貌似作用有点重复,两级缓存不够吗,一级缓存不够吗?为什么要用三级缓存?
只用一级缓存肯定不行,这很好理解,一级缓存的问题在于,就一个map,里面既有完整的bean,也有不完整的,尚未设置属性的bean。如果这时候,有其他线程获取到了不完整的bean,并且对还是null的属性做操作,那就直接空指针了。
那么两级缓存够吗?其实是够的,IoC循环依赖,两级缓存就够用了。
但是,如果参与循环依赖的A和B中,至少有一个对象有AOP切面呢?(AOP切面会动态生成一个代理对象,依赖注入的实际上得是代理对象才行)
在考虑有AOP动态代理对象存在的情况下,两级缓存就不够用了,假设我们给A加了个切面,Spring给A生成了一个动态代理对象A_Proxy。
如果只有两级缓存,一级缓存放完成初始化的bean,二级缓存放提前曝光的早期bean。那么
- A完成实例化之后将引用提前曝光至二级缓存,并开始初始化B,
- B发现要依赖A,就会从二级缓存中取出A对象,注入属性。此时B就会错误的引用了A,而不是Spring希望的引用A_Proxy。
那三级缓存就能解决这个问题么?可以的,还记得我们的第三级缓存存放的是工厂类ObjectFactory。当三级缓存命中的时候,我们是调用ObjectFactory.getObject()来获取对象的,而getObject()实际调用的又是各个beanPostProcessor的getEarlyBeanReference()方法:
1 | addSingletonFactory(beanName, new ObjectFactory() { |
其中,主要就是AOP的主力beanPostProcessor,AbstractAutoProxyCreator#getEarlyBeanReference:
1 | protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) { |
在看SmartInstantiationAwareBeanPostProcessor的getEarlyBeanReference():
1 | public Object getEarlyBeanReference(Object bean, String beanName) throws BeansException { |
这就能保证如果有动态代理的情况,那么从三级缓存取出来的对象,就会是代理对象A_Proxy。
我们把doCreateBean的流程串起来走一下,只列出相关的代码,并假设A和B循环依赖,且A有AOP切面,我们称原始的A为A_Origin,A的代理对象为A_Proxy:
1 | protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final Object[] args) { |
读到这里,也许有人会问,就算只使用两级缓存,我如果在A实例化后,紧接着就调用getEarlyBeanReference()方法去创建切面,然后将生成的A_Proxy放入二级缓存行不行?这不是又可以避免代理对象的问题,又只需要两级缓存吗?
答案是:理论上,是的,可以,但性能不好。
因为Spring中循环依赖出现场景很少,我们没有必要为了解决系统中那1%可能出现的循环依赖问题,而让99%的bean在创建时都去调用getEarlyBeanReference()走上这么一圈。大部分bean调用getEarlyBeanReference(),只会徒增判断逻辑,而没有实质的作用,他们既没有切面,也没有配置相关的BeanPostProcessor类。
使用三级缓存,就可以让确实有循环依赖场景的bean才会去调用getEarlyBeanReference()。因为只有有循环依赖场景的bean,才会用到二三级缓存。
而正常的bean都是
实例化——加入三级缓存——注入属性——执行init方法——执行BeanPostProcessor的方法——加入一级缓存——删除三级缓存——完成初始化
这样的流程。三级缓存的增删,只是一个以防万一而已。
行为型设计模式(模板/策略/命令/职责链/状态/观察者/中介者/迭代器/访问者/备忘录/解释器)
前言
因为设计模式种类多,且重理解重回忆,所以本文尽量言简意赅,便于时时温习。
设计模式(Design Pattern)是前辈们对代码开发经验的总结,是解决特定问题的一系列套路。它不是语法规定,而是一套用来提高代码可复用性、可维护性、可读性、稳健性以及安全性的解决方案。
1995年,GoF(Gang of Four,四人组/四人帮)合作出版了《设计模式:可复用面向对象软件的基础》一书,共收录了23种设计模式,从此树立了软件设计模式领域的里程碑,人称「GoF设计模式」。

这 23 种设计模式的本质是面向对象设计原则的实际运用,是对类的封装性、继承性和多态性,以及类的关联关系和组合关系的充分理解。
当然,软件设计模式只是一个引导,在实际的软件开发中,必须根据具体的需求来选择:
对于简单的程序,可能写一个简单的算法要比引入某种设计模式更加容易;
但是对于大型项目开发或者框架设计,用设计模式来组织代码显然更好。
我们要清楚,设计模式并不是Java的专利,它同样适用于C++、C#、JavaScript等其它面向对象的编程语言。
设计原则
开闭原则
开闭原则的含义是:当应用的需求改变时,在不修改软件实体的源代码或者二进制代码的前提下,可以扩展模块的功能,使其满足新的需求。
里氏替换原则
里氏替换原则通俗来讲就是:子类可以扩展父类的功能,但不能改变父类原有的功能。也就是说:子类继承父类时,除添加新的方法完成新增功能外,尽量不要重写父类的方法。
依赖倒置原则
依赖倒置原则的原始定义为:高层模块不应该依赖低层模块,两者都应该依赖其抽象;抽象不应该依赖细节,细节应该依赖抽象。其核心思想是:要面向接口编程,不要面向实现编程。
依赖倒置原则是实现开闭原则的重要途径之一,它降低了客户与实现模块之间的耦合。
单一职责原则
单一职责原则又称单一功能原则,由罗伯特·C.马丁(Robert C. Martin)于《敏捷软件开发:原则、模式和实践》一书中提出的。这里的职责是指类变化的原因,单一职责原则规定一个类应该有且仅有一个引起它变化的原因,否则类应该被拆分。
该原则提出对象不应该承担太多职责,如果一个对象承担了太多的职责,至少存在以下两个缺点:
- 一个职责的变化可能会削弱或者抑制这个类实现其他职责的能力;
- 当客户端需要该对象的某一个职责时,不得不将其他不需要的职责全都包含进来,从而造成冗余代码或代码的浪费。
迪米特法则
迪米特法则的定义是:只与你的直接朋友交谈,不跟“陌生人”说话。其含义是:如果两个软件实体无须直接通信,那么就不应当发生直接的相互调用,可以通过第三方转发该调用。其目的是降低类之间的耦合度,提高模块的相对独立性。
迪米特法则中的“朋友”是指:当前对象本身、当前对象的成员对象、当前对象所创建的对象、当前对象的方法参数等,这些对象同当前对象存在关联、聚合或组合关系,可以直接访问这些对象的方法。
模式分类
根据目的来分类
根据模式是用来完成什么工作来划分,这种方式可分为创建型模式、结构型模式和行为型模式3种。
创建型模式:用于描述“怎样创建对象”,它的主要特点是“将对象的创建与使用分离”。
GoF中提供了单例、原型、工厂方法、抽象工厂、建造者等5种创建型模式。
结构型模式:用于描述如何将类或对象按某种布局组成更大的结构。
GoF中提供了代理、适配器、桥接、装饰、外观、享元、组合等7种结构型模式。
行为型模式:用于描述类或对象之间怎样相互协作共同完成单个对象都无法单独完成的任务,以及怎样分配职责。
GoF中提供了模板方法、策略、命令、职责链、状态、观察者、中介者、迭代器、访问者、备忘录、解释器等11种行为型模式。
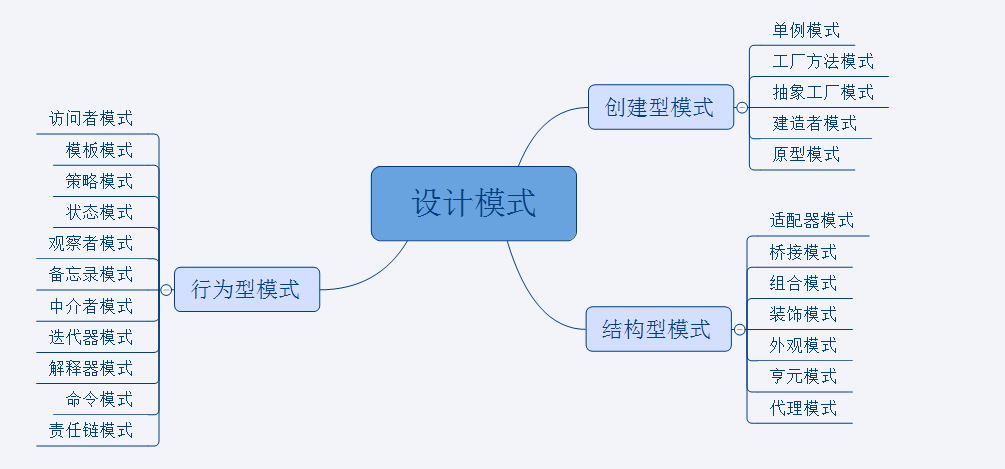
根据作用范围来分类
根据模式是主要用于类上还是主要用于对象上来分,这种方式可分为类模式和对象模式两种。
类模式:用于处理类与子类之间的关系,这些关系通过继承来建立,是静态的,在编译时刻便确定下来了。
GoF中的工厂方法、(类)适配器、模板方法、解释器属于该模式。
对象模式:用于处理对象之间的关系,这些关系可以通过组合或聚合来实现,在运行时刻是可以变化的,更具动态性。
GoF中除了以上4种,其他的都是对象模式。
| 创建型模式 | 结构型模式 | 行为型模式 | |
|---|---|---|---|
| 类模式 | 工厂方法 | (类)适配器 | 模板方法、解释器 |
| 对象模式 | 单例、原型、抽象工厂、建造者 | 代理、(对象)适配器、桥接、装饰、外观、享元、组合 | 策略、命令、职责链、状态、观察者、中介者、迭代器、访问者、备忘录 |
1 策略模式
【介绍】:
策略模式(Strategy Pattern)该模式定义了一系列算法,并将每个算法封装起来,使它们可以相互替换,且算法的变化不会影响使用算法的客户。它通过对算法进行封装,把使用算法的责任和算法的实现分割开来,并委派给不同的对象对这些算法进行管理。
策略模式允许我们在实现某一个功能时,如果存在多种算法或者策略,我们可以根据环境或者条件的不同选择不同的算法或者策略来完成该功能,如数据排序策略有冒泡排序、选择排序、插入排序、二叉树排序等,我们可以根据不同的场景使用不同的算法。
如果使用多重条件转移语句实现(即硬编码,if-else),不但使条件语句变得很复杂,而且增加、删除或更换算法要修改原代码,不易维护,违背开闭原则。如果采用策略模式就能很好解决该问题。
【比喻】:
在现实生活中常常遇到实现某种目标存在多种策略可供选择的情况,例如,出行旅游可以乘坐飞机、乘坐火车、骑自行车或自己开私家车等,超市促销可以釆用打折、送商品、送积分等方法。
【优点】:
- 多重条件语句不易维护,而使用策略模式可以避免使用多重条件语句,如 if…else 语句、switch…case 语句。
- 策略模式提供了一系列的可供重用的算法族,恰当使用继承可以把算法族的公共代码转移到父类里面,从而避免重复的代码。
- 策略模式可以提供相同行为的不同实现,客户可以根据不同时间或空间要求选择不同的。
- 策略模式提供了对开闭原则的完美支持,可以在不修改原代码的情况下,灵活增加新算法。
- 策略模式把算法的使用放到环境类中,而算法的实现移到具体策略类中,实现了二者的分离。
【缺点】:
- 客户端必须理解所有策略算法的区别,以便适时选择恰当的算法类。
- 策略模式造成很多的策略类,增加维护难度。
【应用】:
Spring在具体实例化Bean的过程中,创建对象时先通过ConstructorResolver找到对应的实例化方法和参数,再通过实例化策略InstantiationStrategy进行实例化,它有两种具体策略类,分别为SimpleInstantiationStrategy和CglibSubclassingInstantiationStrategy,前者对构造方法无MethodOverrides的对象使用反射来构造对象,而构造方法有MethodOverrides的对象则交给CglibSubclassingInstantiationStrategy来创建。
【案例】:
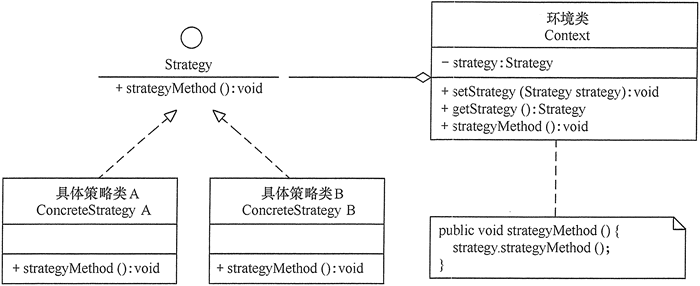
1 | //抽象策略类 |
1 | 具体策略A的策略方法被访问! |
2 观察者模式
【介绍】:
观察者模式(Observer Pattern)指多个对象间存在一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。这种模式有时又称作发布-订阅模式、模型-视图模式。
它的关键实现是在抽象类里有一个列表存放观察者们。一旦有变动发生,则依次调用这些观察者的相关方法。
【比喻】:
就是现实中的发布-订阅模型,或者说广播模型。
【优点】:
- 降低了目标与观察者之间的耦合关系,两者之间是抽象耦合关系。符合依赖倒置原则。
- 目标与观察者之间建立了一套触发机制。
【缺点】:
- 目标与观察者之间的依赖关系并没有完全解除,而且有可能出现循环引用。
- 当观察者对象很多时,通知的发布会花费很多时间,影响程序的效率。
【应用】:
Spring中的监听机制就使用到了观察者模式,其中:
- 观察者们需要实现
ApplicationListener<E extends ApplicationEvent>接口,这是抽象观察者。 - 抽象目标(或者叫做抽象的消息发布者)是
ApplicationEventPublisherAware接口 - Spring观察者模式发布事件的代码都在
ApplicationEventPublisher类中,所以我们生成的具体目标(或者叫做具体的消息发布者)没必要自己编写代码,直接调用ApplicationEventPublisher的publishEvent方法即可。 - Spring中的事件要继承
ApplicationEvent类,即观察者模式中的主题,可以看做一个普通的bean类,用于保存在事件监听器的业务逻辑中需要的一些字段;
发布事件之后,在Spring的ApplicationEventPublisher的底层,SimpleApplicationEventMulticater从容器中获取所有的监听器列表,遍历列表,对每个监听器分别执行invokeListener方法,紧接着它会调用一个doInvokeListener方法,该方法就会调用ApplicationListener的onApplicationEvent方法。
【案例】:
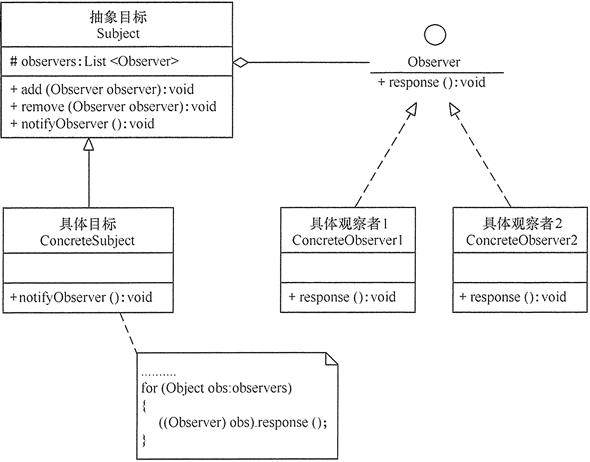
1 | //抽象目标,也是抽象的消息的发布者 |
1 | 具体目标发生改变... |
3 责任链模式
【介绍】:
责任链(Chain of Responsibility)模式,是为了避免请求发送者与多个请求接收者耦合在一起,于是将所有请求的接收者通过前一对象记住其下一个对象的引用而连成一条链;当有请求发生时,可将请求沿着这条链传递,直到有对象处理它为止。
在这种模式中,通常每个接收者都包含对另一个接收者的引用。如果一个对象不能处理该请求,那么它会把相同的请求传给下一个接收者,依此类推。
在责任链模式中,客户只需要将请求发送到责任链上即可,无须关心请求的处理细节和请求的传递过程,请求会自动进行传递。所以责任链将请求的发送者和请求的处理者解耦了。
通常情况下,可以通过数据链表来实现职责链模式的数据结构。

【比喻】:
在现实生活中,一个事件需要经过多个对象处理是很常见的场景。例如,公司员工请假,可批假的领导有部门负责人、副总经理、总经理等,但每个领导能批准的天数不同,员工必须根据需要请假的天数去找不同的领导签名,也就是说员工必须记住每个领导的姓名、电话和地址等信息。
【优点】:
- 降低了对象之间的耦合度。该模式使得一个对象无须知道到底是哪一个对象处理其请求以及链的结构,发送者和接收者也无须拥有对方的明确信息。
- 增强了系统的可扩展性。可以根据需要增加新的请求处理类,满足开闭原则。
- 增强了给对象指派职责的灵活性。当工作流程发生变化,可以动态地改变链内的成员或者调动它们的次序,也可动态地新增或者删除责任。
- 责任链简化了对象之间的连接。每个对象只需保持一个指向其后继者的引用,不需保持其他所有处理者的引用,这避免了使用众多的 if 或者 if···else 语句。
- 责任分担。每个类只需要处理自己该处理的工作,不该处理的传递给下一个对象完成,明确各类的责任范围,符合类的单一职责原则。
【缺点】:
- 不能保证每个请求一定被处理。由于一个请求没有明确的接收者,所以不能保证它一定会被处理,该请求可能一直传到链的末端都得不到处理。
- 对比较长的责任链,请求的处理可能涉及多个处理对象,系统性能将受到一定影响。
- 责任链建立的合理性要靠客户端来保证,增加了客户端的复杂性,可能会由于职责链的错误设置而导致系统出错,如可能会造成循环调用。
【应用】:
- Apache Tomcat对Encoding的处理
- Struts2的拦截器
- jsp servlet的Filter。
- Spring中的过滤器ApplicationFilterChain。
【案例】:
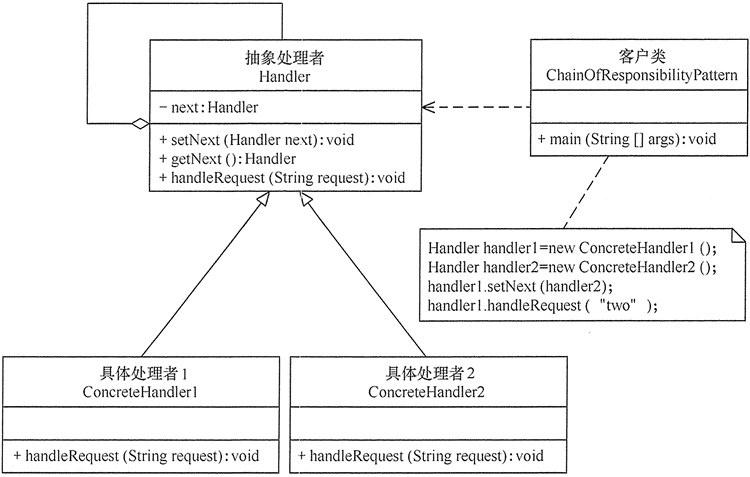
1 | //抽象处理者角色 |
4 模板模式
【介绍】:
模板模式(Template Pattern)定义了一个操作中的算法骨架,而将算法的一些步骤延迟到子类中,使得子类可以不改变该算法结构的情况下重定义该算法的某些特定步骤。它是一种类行为型模式。
【比喻】:
例如,去银行办理业务一般要经过以下4个流程:取号、排队、办理具体业务、对银行工作人员进行评分等。
其中取号、排队和对银行工作人员进行评分的业务对每个客户是一样的,可以在父类中实现,但是办理具体业务却因人而异,它可能是存款、取款或者转账等,可以延迟到子类中实现。
这样的例子在生活中还有很多,例如,一个人每天会起床、吃饭、做事、睡觉等,其中“做事”的内容每天可能不同。我们把这些规定了流程或格式的实例定义成模板,允许使用者根据自己的需求去更新它,例如,简历模板、论文模板等。
【优点】:
- 它封装了不变部分,扩展可变部分。它把认为是不变部分的算法封装到父类中实现,而把可变部分算法由子类继承实现,便于子类继续扩展。
- 它在父类中提取了公共的部分代码,便于代码复用。
- 部分方法是由子类实现的,因此子类可以通过扩展方式增加相应的功能,符合开闭原则。
【缺点】:
- 对每个不同的实现都需要定义一个子类,这会导致类的个数增加,系统更加庞大,设计也更加抽象,间接地增加了系统实现的复杂度。
- 父类中的抽象方法由子类实现,子类执行的结果会影响父类的结果,这导致一种反向的控制结构,它提高了代码阅读的难度。
- 由于继承关系自身的缺点,如果父类添加新的抽象方法,则所有子类都要改一遍。
【应用】:
- Java Servlet中,HttpServlet这个类就是一个抽象的模板类,它定义了doGet,doPost,doHead,doDelete等一系列的抽象方法,并在service方法中规定了前面这些方法的执行顺序和条件,形成了http访问的模板。我们定义的新的servlet子类,只需要继承HttpServlet,并实现doGet,doPost等方法即可。
- Mybatis中,BaseExecutor定义了数据库操作的基本模板:doUpdate()方法、doQuery()方法、doQueryCursor()方法、doFlushStatement()方法。继承BaseExecutor的子类只需要实现四个基本方法来完成数据库的相关操作即可。
- SpringBoot为用户封装了很多继承代码,都用到了模板方式,例如那一堆XXXtemplate。
【案例】:
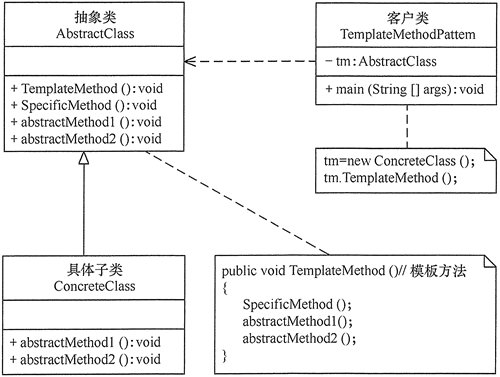
1 | //抽象类 |
1 | 抽象类中的具体方法被调用... |
5 状态模式
【介绍】:
状态模式(State Pattern)对有状态的对象,把复杂的“判断逻辑”提取到不同的状态对象中,允许状态对象在其内部状态发生改变时改变其行为。
在软件开发过程中,应用程序中的部分对象可能会根据不同的情况做出不同的行为,我们把这种对象称为有状态的对象,而把影响对象行为的一个或多个动态变化的属性称为状态。
当有状态的对象与外部事件产生互动时,其内部状态就会发生改变,从而使其行为也发生改变。
对这种有状态的对象编程,传统的解决方案是:将这些所有可能发生的情况全都考虑到,然后使用if-else或switch-case语句来做状态判断,再进行不同情况的处理。但是显然这种做法对复杂的状态判断存在天然弊端,条件判断语句会过于臃肿,可读性差,且不具备扩展性,维护难度也大。
以上问题如果采用“状态模式”就能很好地得到解决。状态模式的解决思想是:当控制一个对象状态转换的条件表达式过于复杂时,把相关“判断逻辑”提取出来,用各个不同的类进行表示,系统处于哪种情况,直接使用相应的状态类对象进行处理,这样能把原来复杂的逻辑判断简单化,消除了 if-else、switch-case 等冗余语句,代码更有层次性,并且具备良好的扩展力。
【比喻】:
例如人都有高兴和伤心的不同状态,不同的状态有不同的行为,将不同的状态及其对应的行为封装成独立的状态对象,这样就可以根据情绪表现出不同的行为,同时不同的行为也会反馈自己切换成不同的状态。
【优点】:
- 结构清晰,状态模式将与特定状态相关的行为局部化到一个状态中,并且将不同状态的行为分割开来,满足“单一职责原则”。
- 将状态转换显示化,减少对象间的相互依赖。将不同的状态引入独立的对象中会使得状态转换变得更加明确,且减少对象间的相互依赖。
- 状态类职责明确,有利于程序的扩展。通过定义新的子类很容易地增加新的状态和转换。
【缺点】:
- 状态模式的使用必然会增加系统的类与对象的个数。
- 状态模式的结构与实现都较为复杂,如果使用不当会导致程序结构和代码的混乱。
- 状态模式对开闭原则的支持并不太好,对于可以切换状态的状态模式,增加新的状态类需要修改那些负责状态转换的源码,否则无法切换到新增状态,而且修改某个状态类的行为也需要修改对应类的源码。
【应用】:
Spring中的状态机stateMachine。
【案例】:
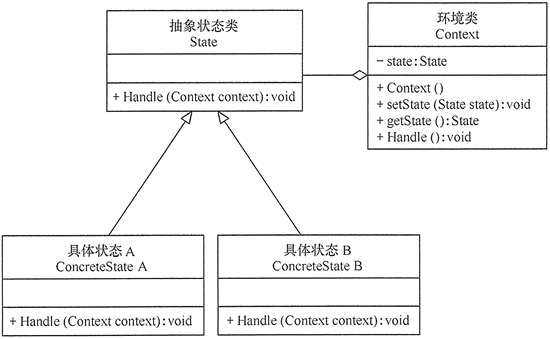
1 | //环境类 |
输出
1 | 当前状态是 A. |
状态模式和策略模式看起来很像,UML图都很像,但其实含义不一样。状态模式重点在各状态之间的切换从而做不同的事情,而策略模式更侧重于根据具体情况选择不同策略,并不涉及切换,策略之间是完全独立的。同时,在状态模式中,每个状态通过持有Context的引用,来实现状态转移;但是每个策略都不持有Context的引用,它们只是被Context使用。
6 迭代器模式
【介绍】:
迭代器(Iterator Pattern)模式提供一个对象来顺序访问集合对象中的一系列数据,它在客户访问类与集合类之间插入一个迭代器,这分离了集合对象与其遍历行为,对客户也隐藏了其内部细节而不暴露集合对象的内部表示。
例如Java中的Collection、List、Set、Map等都包含了迭代器。在日常开发中,我们几乎不会自己写迭代器。除非需要定制一个自己实现的数据结构对应的迭代器,否则,开源框架提供的API完全够用。
【比喻】:
比如:物流系统中的传送带,不管传送的是什么物品,都会被打包成一个个箱子,并且有一个统一的二维码。这样我们不需要关心箱子里是什么,在分发时只需要一个个检查发送的目的地即可。
比如,我们平时乘坐交通工具,上车的队列,都是统一刷卡或者刷脸进站,而不需要关心是男性还是女性、是残疾人还是正常人等信息。
【优点】:
- 访问一个集合对象的内容而无须暴露它的内部表示。
- 遍历任务交由迭代器完成,这简化了聚合类。
- 它支持以不同方式遍历一个集合,甚至可以自定义迭代器的子类以支持新的遍历。
- 增加新的集合类和迭代器类都很方便,无须修改原有代码。
- 封装性良好,为遍历不同的集合结构提供一个统一的接口。
【缺点】:
增加了类的个数,这在一定程度上增加了系统的复杂性。
【应用】:
Java中的Collection、List、Set、Map等都包含了迭代器。
【案例】:
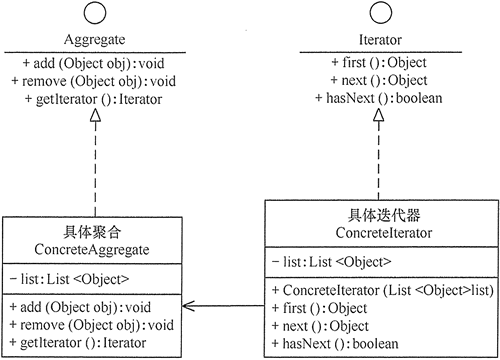
1 | //抽象集合 |
1 | 聚合的内容有:中山大学 华南理工 韶关学院 |
7 命令模式
【介绍】:
命令(Command Pattern)模式将一个请求封装为一个对象,使发出请求的责任和执行请求的责任分割开。这样两者之间通过命令对象进行沟通,这样方便将命令对象进行储存、传递、调用、增加与管理。
在命令对象内部持有处理该命令的接受者,这样每个命令和其接受者的关系就得到了绑定。
通过把命令封装为一个对象,命令发送者把命令对象发出后,就不去管是谁来接受处理这个命令,命令接受者接受到命令对象后进行处理,也不用管命令是谁发出的,所以命令模式实现了发送者与接受者之间的解耦,而具体把命令发送给谁还需要一个控制器。
【比喻】:
在现实生活中,命令模式的例子也很多。比如看电视时,我们只需要轻轻一按遥控器就能完成频道的切换,这就是命令模式,将换台请求和换台处理完全解耦了。电视机遥控器(命令发送者)通过按钮(具体命令)来遥控电视机(命令接收者)。而对于电视机遥控器来说,它只能操控电视,它操控的对象已经和遥控器绑定了,我们不管里面的逻辑。
对于用户来说,我们想看电视,就只管找电视遥控器,不关心电视遥控器是如何打开电视的,想开空调,就只管找空调遥控器,以此类推。
同样的,电视作为接受者,也不关心是谁打开了它,它只和遥控器绑定,如果哪天电视要升级改版,也和发送者没关系。
【优点】:
- 通过引入中间件(抽象接口)降低系统的耦合度。
- 扩展性良好,增加或删除命令非常方便。采用命令模式增加与删除命令不会影响其他类,且满足“开闭原则”。
- 可以实现宏命令。命令模式可以与组合模式结合,将多个命令装配成一个组合命令,即宏命令。
- 方便实现Undo和Redo操作。命令模式可以与后面介绍的备忘录模式结合,实现命令的撤销与恢复。
- 可以在现有命令的基础上,增加额外功能。比如日志记录,结合装饰器模式会更加灵活。
【缺点】:
- 可能产生大量具体的命令类。因为每一个具体操作都需要设计一个具体命令类,这会增加系统的复杂性。
- 命令模式的结果其实就是接收方的执行结果,但是为了以命令的形式进行架构、解耦请求与实现,引入了额外类型结构(引入了请求方与抽象命令接口),增加了理解上的困难。不过这也是设计模式的通病,抽象必然会额外增加类的数量,代码抽离肯定比代码聚合更加难理解。
【应用】:
Tomcat作为一个服务器本身会接受外部大量请求,当一个请求过来后tomcat根据域名去找对应的host,找到host后会根据应用名去找具体的context(应用),然后具体应用处理请求。
Tomcat中的Connector作为命令发出者,Connector接受到请求后把请求内容封装为request对象(命令对象),然后使用CoyoteAdapter作为分发器把请求具体发配到具体的host,host再根据request对象找到具体的context,至此找到了具体的应用,交给具体应用处理。
这就实现了:对于具体host来说他不关心这个请求是谁给的,对于Connector来说他也不必关心谁来处理,但是两者是通过request封装请求对象进行关联起来。
【案例】:
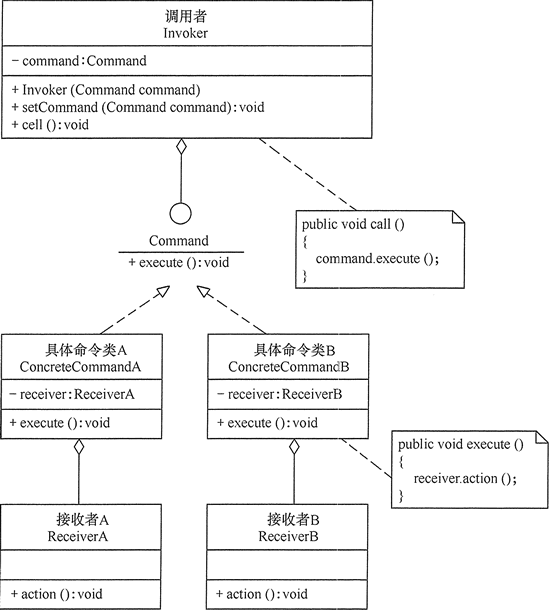
1 | //调用者 |
8 备忘录模式
【介绍】:
备忘录(Memento Pattern)模式在不破坏封装性的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态,以便以后当需要时能将该对象恢复到原先保存的状态。该模式又叫快照模式。
其实很多应用软件都提供了这项功能,如Word、记事本、Photoshop、Eclipse等软件在编辑时按Ctrl+Z组合键时能撤销当前操作,使文档恢复到之前的状态;
备忘录模式能记录一个对象的内部状态,当用户后悔时能撤销当前操作,使数据恢复到它原先的状态。
【比喻】:
每个人都有犯错误的时候,都希望有种“后悔药”能弥补自己的过失,让自己重新开始,但现实是残酷的。在计算机应用中,客户同样会常常犯错误,能否提供“后悔药”给他们呢?当然是可以的,而且是有必要的。这个功能由备忘录模式来实现。
【优点】:
- 提供了一种可以恢复状态的机制。当用户需要时能够比较方便地将数据恢复到某个历史的状态。
- 实现了内部状态的封装。除了创建它的发起人之外,其他对象都不能够访问这些状态信息。
- 简化了发起人类。发起人不需要管理和保存其内部状态的各个备份,所有状态信息都保存在备忘录中,并由管理者进行管理,这符合单一职责原则。
【缺点】:
资源消耗大。如果要保存的内部状态信息过多或者特别频繁,将会占用比较大的内存资源。
【应用】:
spring-webflow中的StateManageableMessageContext类,就才用了备忘录模式,它接口中定义了createMessagesMemento()方法,其实现类DefaultMessageContext有其默认实现:
1 | private Map<Object, List<Message>> sourceMessages; |
【案例】:
备忘录模式使用三个类 Memento、Originator和CareTaker。
Memento用来存储要被恢复的对象的状态。Originator创建并在Memento对象中存储状态。Caretaker对象是Memento的管理者,负责管理存储多版本的Memento,以及从Memento中恢复对象的状态。
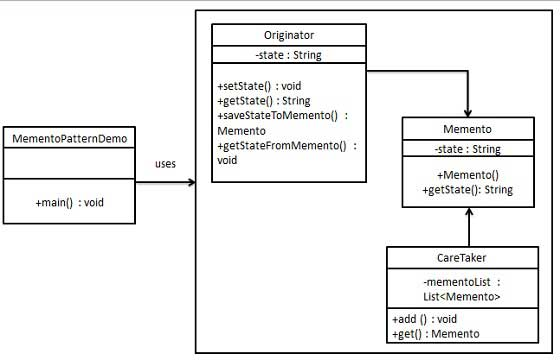
1 | public class Memento { |
1 | Current State: State #4 |
9 访问者模式
【介绍】:
访问者模式(Visitor Pattern)将作用于集合类中的各元素的操作分离出来封装成独立的类,使其在不改变数据结构的前提下可以添加作用于这些元素的新的操作,为数据结构中的每个元素提供多种访问方式。
比较难理解?我们用商场的商品来比喻一下。
【比喻】:
比如说在商场购物时放在购物车中的商品,购物车就是集合类,商品是元素(可能是不同类型),那么我们知道,不同的访问者,对于商品的操作是不一样的。收银员对商品的操作是计价,而顾客对商品的操作是使用。
常规情况下我们会在商品类中定义settle()方法用来计价,定义use()方法用来使用,但假如我们现在新增了一类访问者呢?假如新增了一类质检员,对商品进行质检,难道我们还要将每个商品类都新增check()方法吗?后面如果再来一类访问者呢?
访问者模式就是为了解决这种痛点应运而生的。
【优点】:
- 扩展性好。能够在不修改对象结构中的元素的情况下,为对象结构中的元素添加新的功能。
- 复用性好。可以通过访问者来定义整个对象结构通用的功能,从而提高系统的复用程度。
- 灵活性好。访问者模式将数据结构与作用于结构上的操作解耦,使得操作集合可相对自由地演化而不影响系统的数据结构。
- 符合单一职责原则。访问者模式把相关的行为封装在一起,构成一个访问者,使每一个访问者的功能都比较单一。
【缺点】:
- 增加新的元素类很困难。在访问者模式中,每增加一个新的元素类,都要在每一个具体访问者类中增加相应的具体操作,这违背了“开闭原则”。
- 破坏封装。访问者模式中具体元素对访问者公布细节,这破坏了对象的封装性。
- 违反了依赖倒置原则。访问者模式依赖了具体类,而没有依赖抽象类。
【应用】:
Spring的BeanDefinitionVisitor类被设计用来访问BeanDefinition对象。PropertyPlaceholderConfigurer类会遍历得到的所有的BeanDefinition对象,依次调用visitor.visitBeanDefinition(bd)方法。不过目前Spring目前只有BeanDefinitionVisitor一个访问者类,但代码中已经保留了拓展性。
【案例】:
访问者模式包含以下主要角色。
- 抽象访问者(Visitor)角色:定义一个访问具体元素的接口,为每个具体元素类对应一个访问操作visit(),该操作中的参数类型标识了被访问的具体元素。
- 具体访问者(ConcreteVisitor)角色:实现抽象访问者角色中声明的各个访问操作,确定访问者访问一个元素时该做什么。
- 抽象元素(Element)角色:声明一个包含接受操作accept()的接口,被接受的访问者对象作为accept()方法的参数。
- 具体元素(ConcreteElement)角色:实现抽象元素角色提供的accept()操作,其方法体通常都是visitor.visit(this) ,另外具体元素中可能还包含本身业务逻辑的相关操作。
- 对象结构(Object Structure)角色:是一个包含元素角色的容器,提供让访问者对象遍历容器中的所有元素的方法,通常由List、Set、Map等聚合类实现。
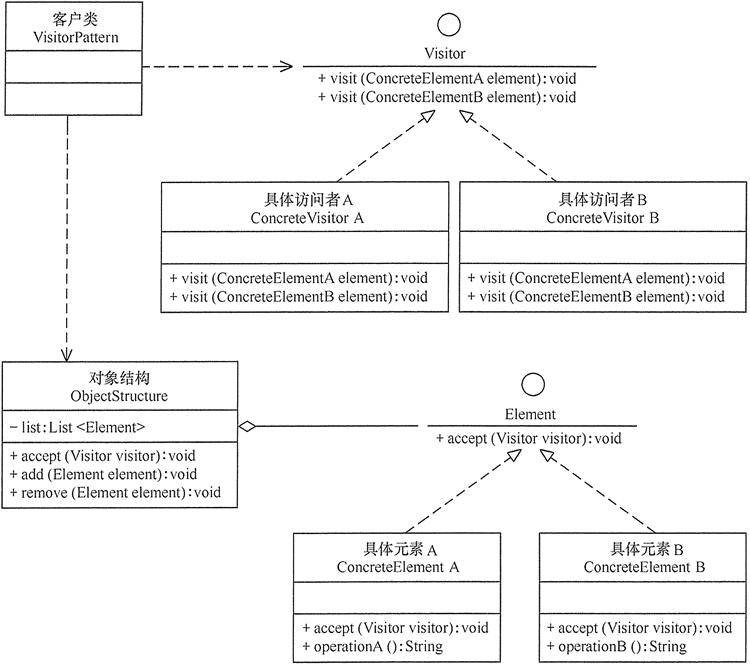
1 | //抽象访问者 |
1 | 具体访问者A访问,我是质检员,进行质检,元素A是罐头商品,打开罐头检查---->具体元素A的操作。我是罐头商品,打开罐头。 |
10 中介者模式
【介绍】:
中介者(Mediator Pattern)模式定义了一个中介对象来封装一系列对象之间的交互,使原有对象之间的耦合松散,且可以独立地改变它们之间的交互。
在现实生活中,常常会出现好多对象之间存在复杂的交互关系,这种交互关系常常是“网状结构”,它要求每个对象都必须知道它需要交互的对象。例如,每个人必须记住他(她)所有朋友的电话;而且,朋友中如果有人的电话修改了,他(她)必须让其他所有的朋友一起修改,这叫作“牵一发而动全身”,非常复杂。
如果把这种“网状结构”改为“星形结构”的话,将大大降低它们之间的“耦合性”,这时只要找一个“中介者”就可以了。如前面所说的“每个人必须记住所有朋友电话”的问题,只要在网上建立一个每个朋友都可以访问的“通信录”就解决了。
【比喻】:
例如,你想租房,可以找房产中介,房产中介那里有许多的房源信息。
例如,多个用户可以向聊天室(中介类)发送消息,聊天室向所有的用户显示消息。
【优点】:
- 类之间各司其职,符合迪米特法则。
- 降低了对象之间的耦合性,使得对象易于独立地被复用。
- 将对象间的一对多关联转变为一对一的关联,提高系统的灵活性,使得系统易于维护和扩展。
【缺点】:
中介者模式将原本多个对象直接的相互依赖变成了中介者和多个同事类的依赖关系。当同事类越多时,中介者就会越臃肿,变得复杂且难以维护。
【应用】:
在各种的MVC框架中,其中C(控制器)就是M(模型)和V(视图)的中介者。
【案例】:
中介者模式包含以下主要角色。
- 抽象中介者(Mediator)角色:它是中介者的接口,提供了同事对象注册与转发同事对象信息的抽象方法。
- 具体中介者(Concrete Mediator)角色:实现中介者接口,定义一个List来管理同事对象,协调各个同事角色之间的交互关系,因此它依赖于同事角色。
- 抽象同事类(Colleague)角色:定义同事类的接口,保存中介者对象,提供同事对象交互的抽象方法,实现所有相互影响的同事类的公共功能。
- 具体同事类(Concrete Colleague)角色:是抽象同事类的实现者,当需要与其他同事对象交互时,由中介者对象负责后续的交互。
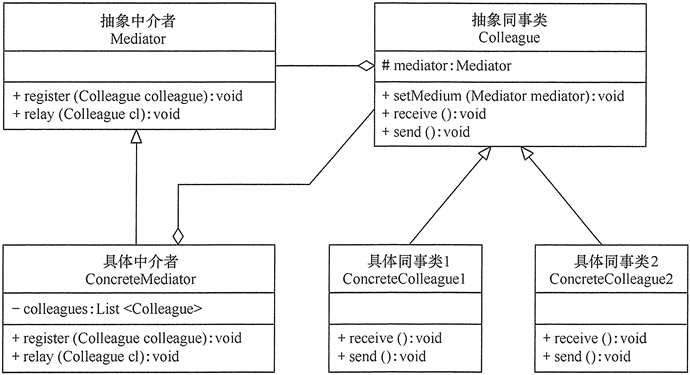
1 | //抽象中介者 |
1 | 具体同事类1发出请求。 |
11 解释器模式
【介绍】:
解释器(Interpreter Pattern)模式给分析对象定义一个语言,并定义该语言的文法表示,再设计一个解析器来解释语言中的句子。也就是说,用编译语言的方式来分析应用中的实例。这种模式实现了文法表达式处理的接口,该接口解释一个特定的上下文。
这种模式实现了一个表达式接口,该接口解释一个特定的上下文。这种模式被用在SQL解析、符号处理引擎等。
在项目开发中,如果要对数据表达式进行分析与计算,无须再用解释器模式进行设计了,Java提供了以下强大的数学公式解析器:Expression4J、MESP(Math Expression String Parser)和Jep等,它们可以解释一些复杂的文法,功能强大,使用简单。
【比喻】:
【优点】:
- 扩展性好。由于在解释器模式中使用类来表示语言的文法规则,因此可以通过继承等机制来改变或扩展文法。
- 容易实现。在语法树中的每个表达式节点类都是相似的,所以实现其文法较为容易。
【缺点】:
- 执行效率较低。解释器模式中通常使用大量的循环和递归调用,当要解释的句子较复杂时,其运行速度很慢,且代码的调试过程也比较麻烦。
- 会引起类膨胀。解释器模式中的每条规则至少需要定义一个类,当包含的文法规则很多时,类的个数将急剧增加,导致系统难以管理与维护。
- 可应用的场景比较少。在软件开发中,需要定义语言文法的应用实例非常少,所以这种模式很少被使用到。
【应用】:
用于SQL语句的解析。
【案例】:
假如“韶粵通”公交车读卡器可以判断乘客的身份,如果是“韶关”或者“广州”的“老人” “妇女”“儿童”就可以免费乘车,其他人员乘车一次扣2元。
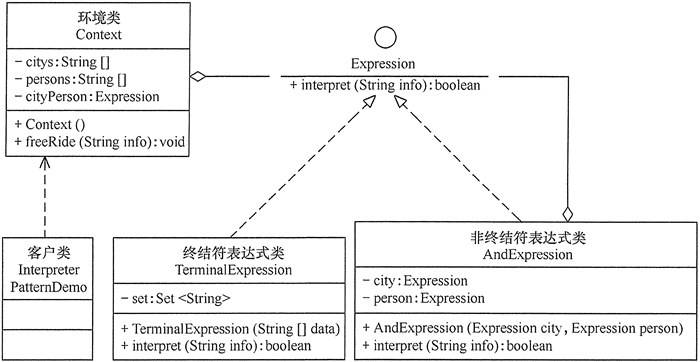
然后,根据文法规则按以下步骤设计公交车卡的读卡器程序的类图。
- 定义一个抽象表达式(Expression)接口,它包含了解释方法interpret(String info)。
- 定义一个终结符表达式(Terminal Expression)类,它用集合(Set)类来保存满足条件的城市或人,并实现抽象表达式接口中的解释方法 interpret(Stringinfo),用来判断被分析的字符串是否是集合中的终结符。
- 定义一个非终结符表达式(AndExpressicm)类,它也是抽象表达式的子类,它包含满足条件的城市的终结符表达式对象和满足条件的人员的终结符表达式对象,并实现 interpret(String info) 方法,用来判断被分析的字符串是否是满足条件的城市中的满足条件的人员。
- 最后,定义一个环境(Context)类,它包含解释器需要的数据,完成对终结符表达式的初始化,并定义一个方法 freeRide(String info) 调用表达式对象的解释方法来对被分析的字符串进行解释。
1 | //抽象表达式类 |
1 | 您是韶关的老人,您本次乘车免费! |
结构型设计模式(适配器/桥接/过滤器/组合/装饰器/外观/享元/代理)
前言
因为设计模式种类多,且重理解重回忆,所以本文尽量言简意赅,便于时时温习。
设计模式(Design Pattern)是前辈们对代码开发经验的总结,是解决特定问题的一系列套路。它不是语法规定,而是一套用来提高代码可复用性、可维护性、可读性、稳健性以及安全性的解决方案。
1995年,GoF(Gang of Four,四人组/四人帮)合作出版了《设计模式:可复用面向对象软件的基础》一书,共收录了23种设计模式,从此树立了软件设计模式领域的里程碑,人称「GoF设计模式」。
这 23 种设计模式的本质是面向对象设计原则的实际运用,是对类的封装性、继承性和多态性,以及类的关联关系和组合关系的充分理解。
当然,软件设计模式只是一个引导,在实际的软件开发中,必须根据具体的需求来选择:
对于简单的程序,可能写一个简单的算法要比引入某种设计模式更加容易;
但是对于大型项目开发或者框架设计,用设计模式来组织代码显然更好。
我们要清楚,设计模式并不是Java的专利,它同样适用于C++、C#、JavaScript等其它面向对象的编程语言。
设计原则
开闭原则
开闭原则的含义是:当应用的需求改变时,在不修改软件实体的源代码或者二进制代码的前提下,可以扩展模块的功能,使其满足新的需求。
里氏替换原则
里氏替换原则通俗来讲就是:子类可以扩展父类的功能,但不能改变父类原有的功能。也就是说:子类继承父类时,除添加新的方法完成新增功能外,尽量不要重写父类的方法。
依赖倒置原则
依赖倒置原则的原始定义为:高层模块不应该依赖低层模块,两者都应该依赖其抽象;抽象不应该依赖细节,细节应该依赖抽象。其核心思想是:要面向接口编程,不要面向实现编程。
依赖倒置原则是实现开闭原则的重要途径之一,它降低了客户与实现模块之间的耦合。
单一职责原则
单一职责原则又称单一功能原则,由罗伯特·C.马丁(Robert C. Martin)于《敏捷软件开发:原则、模式和实践》一书中提出的。这里的职责是指类变化的原因,单一职责原则规定一个类应该有且仅有一个引起它变化的原因,否则类应该被拆分。
该原则提出对象不应该承担太多职责,如果一个对象承担了太多的职责,至少存在以下两个缺点:
- 一个职责的变化可能会削弱或者抑制这个类实现其他职责的能力;
- 当客户端需要该对象的某一个职责时,不得不将其他不需要的职责全都包含进来,从而造成冗余代码或代码的浪费。
迪米特法则
迪米特法则的定义是:只与你的直接朋友交谈,不跟“陌生人”说话。其含义是:如果两个软件实体无须直接通信,那么就不应当发生直接的相互调用,可以通过第三方转发该调用。其目的是降低类之间的耦合度,提高模块的相对独立性。
迪米特法则中的“朋友”是指:当前对象本身、当前对象的成员对象、当前对象所创建的对象、当前对象的方法参数等,这些对象同当前对象存在关联、聚合或组合关系,可以直接访问这些对象的方法。
模式分类
根据目的来分类
根据模式是用来完成什么工作来划分,这种方式可分为创建型模式、结构型模式和行为型模式3种。
创建型模式:用于描述“怎样创建对象”,它的主要特点是“将对象的创建与使用分离”。
GoF中提供了单例、原型、工厂方法、抽象工厂、建造者等5种创建型模式。
结构型模式:用于描述如何将类或对象按某种布局组成更大的结构。
GoF中提供了代理、适配器、桥接、装饰、外观、享元、组合等7种结构型模式。
行为型模式:用于描述类或对象之间怎样相互协作共同完成单个对象都无法单独完成的任务,以及怎样分配职责。
GoF中提供了模板方法、策略、命令、职责链、状态、观察者、中介者、迭代器、访问者、备忘录、解释器等11种行为型模式。
根据作用范围来分类
根据模式是主要用于类上还是主要用于对象上来分,这种方式可分为类模式和对象模式两种。
类模式:用于处理类与子类之间的关系,这些关系通过继承来建立,是静态的,在编译时刻便确定下来了。
GoF中的工厂方法、(类)适配器、模板方法、解释器属于该模式。
对象模式:用于处理对象之间的关系,这些关系可以通过组合或聚合来实现,在运行时刻是可以变化的,更具动态性。
GoF中除了以上4种,其他的都是对象模式。
| 创建型模式 | 结构型模式 | 行为型模式 | |
|---|---|---|---|
| 类模式 | 工厂方法 | (类)适配器 | 模板方法、解释器 |
| 对象模式 | 单例、原型、抽象工厂、建造者 | 代理、(对象)适配器、桥接、装饰、外观、享元、组合 | 策略、命令、职责链、状态、观察者、中介者、迭代器、访问者、备忘录 |
1 代理模式
【介绍】:
在代理模式(Proxy Pattern)中,一个类代表另一个类的功能。这个类叫做代理类。在有些情况下,一个客户不能或者不想直接访问另一个对象,这时需要找一个中介帮忙完成某项任务,这个中介就是代理对象。
【比喻】:
购买火车票不一定要去火车站买,可以通过12306网站或者去火车票代售点买。又比如租房子,可以通过找中介完成。
【优点】:
- 代理模式在客户端与目标对象之间起到一个中介作用和保护目标对象的作用;
- 代理对象可以扩展目标对象的功能;
- 代理模式能将客户端与目标对象分离,在一定程度上降低了系统的耦合度,增加了程序的可扩展性
【缺点】:
- 代理模式会造成系统设计中类的数量增加
- 在客户端和目标对象之间增加一个代理对象,会造成请求处理速度变慢;
- 增加了系统的复杂度;
那么如何解决以上提到的缺点呢?答案是可以使用动态代理方式
【应用】:
spring AOP中就大量使用了代理模型。
【案例】:
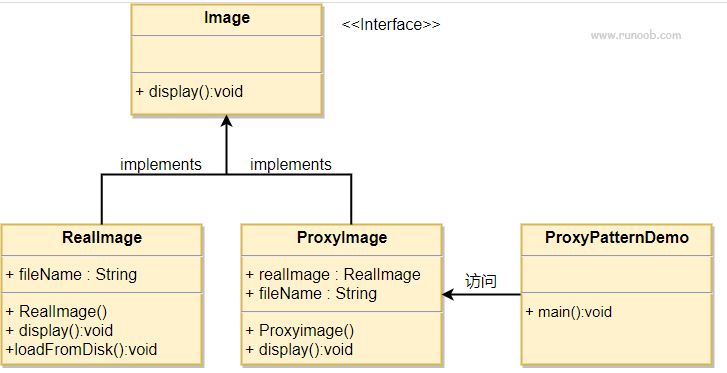
我们将创建一个Image接口和实现了Image接口的实体类。ProxyImage是一个代理类,减少 RealImage对象加载的内存占用。
ProxyPatternDemo类使用ProxyImage来获取要加载的Image对象,并按照需求进行显示。
1 | public interface Image { |
当被请求时,使用 ProxyImage 来获取 RealImage 类的对象。
1 | public class ProxyPatternDemo { |
2 适配器模式
【介绍】:
适配器模式(Adapter Pattern)是作为两个不兼容的接口之间的桥梁,它可以将一个类的接口转换成客户希望的另外一个接口,使得原本由于接口不兼容而不能一起工作的那些类能一起工作。
适配器模式分为类结构型模式和对象结构型模式两种,前者类之间的耦合度比后者高,且要求程序员了解现有组件库中的相关组件的内部结构,所以应用相对较少些。
适配器不是在设计时添加的,而是解决正在服役的项目的不兼容问题。
【比喻】:
在现实生活中,经常出现两个对象因接口不兼容而不能在一起工作的实例,这时需要第三者进行适配。
例如:
- 讲中文的人同讲英文的人对话时需要一个翻译
- 用直流电的笔记本电脑接交流电源时需要一个电源适配器
- 用计算机访问照相机的SD内存卡时需要一个读卡器等。
【优点】:
- 客户端通过适配器可以透明地调用目标接口。
- 复用了现存的类,程序员不需要修改原有代码而重用现有的适配者类。
- 将目标类和适配者类解耦,解决了目标类和适配者类接口不一致的问题。
- 在很多业务场景中符合开闭原则。
【缺点】:
- 适配器编写过程需要结合业务场景全面考虑,可能会增加系统的复杂性。
- 增加代码阅读难度,降低代码可读性,过多使用适配器会使系统代码变得凌乱。
【应用】:
spring AOP中的MethodInterceptor接口被用来拦截指定的方法,对方法进行增强。
【案例】:
例如一个美国人说英语,一个中国人说中文,为了跟美国人做生意,就需要一个适配器,来充当沟通两者的工作。现在,我们希望让一个能说中国话的个体(实现说中文的接口的类),开口说英文。
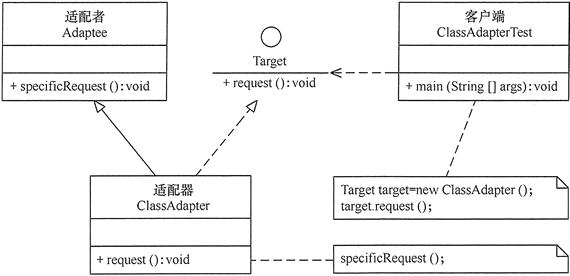
适配器有两种主要的实现,我们先看第一种——类适配器
类适配器:
1 | // 被适配类,已存在的、具有还有用处的特殊功能、但不符合我们既有的标准接口的类 |
对象适配器:
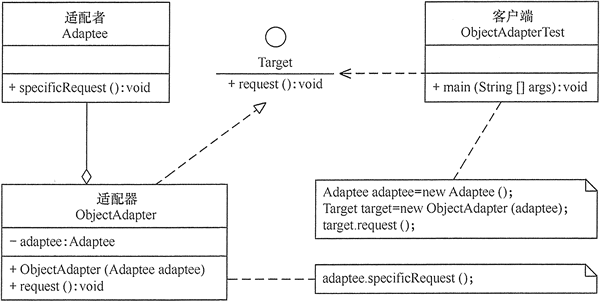
另外一种适配器模式是对象适配器,它不是使用多继承或继承再实现的方式,而是使用直接关联,或者称为委托的方式。
其他目标类和被适配类都一样,就是适配器类的定义方式有所不同:
1 | // 适配器类,直接关联被适配类,同时实现标准接口 |
3 桥接模式
【介绍】:
桥接(Bridge Pattern)是用于把抽象化与实现化解耦,使得二者可以独立变化。它通过提供抽象化和实现化之间的桥接结构,来实现二者的解耦。
在现实生活中,某些类具有两个或多个维度的变化,如图形既可按形状分,又可按颜色分。如何设计类似于Photoshop这样的软件,能画不同形状和不同颜色的图形呢?
如果用继承方式,m种形状和n 种颜色的图形就有m×n种结果,不但对应的子类很多,而且扩展困难。
桥接模式是用组合关系代替继承关系来实现,从而降低了抽象和实现这两个可变维度的耦合度。
【比喻】:
文字类桥接了颜色和字体的接口,实现组合成了不同颜色和字体的文字。
汽车类桥接了扭矩和功率的接口,实现组合成了不同扭矩和功率的汽车。
【优点】:
- 抽象与实现分离,利用组合关系,扩展能力强
- 符合开闭原则和合成复用原则
- 内部实现细节对客户透明
【缺点】:
由于聚合关系建立在抽象层,要求开发者针对抽象化进行设计与编程,能正确地识别出系统中两个独立变化的维度,这增加了系统的理解与设计难度。
【应用】:
Java的JDBC中,Driver类就是桥接对象,它组合了Connection/DriverPropertyInfo[]/Logger等功能类
1 | public interface Driver { |
【案例】:
我们有一个作为桥接实现的DrawAPI接口和实现了DrawAPI接口的实体类RedCircle、GreenCircle。Shape是一个抽象类,将使用DrawAPI的对象。BridgePatternDemo类使用Shape类来画出不同颜色的圆。
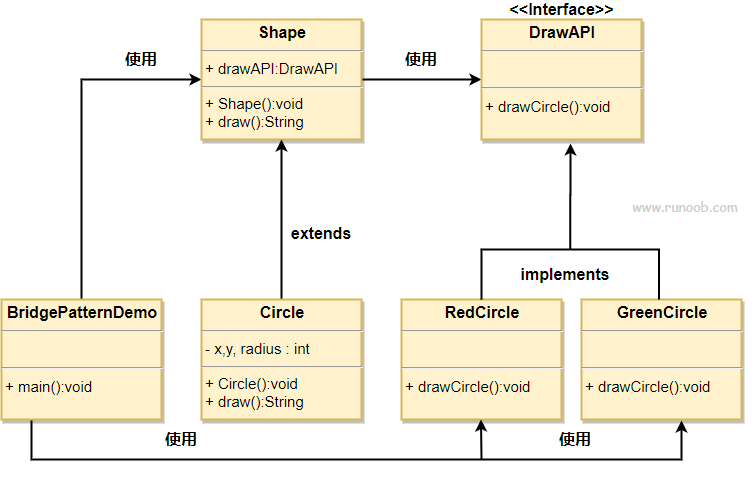
1 | // 绘画功能的api接口,以及两种颜色功能的功能类 |
1 | // 要桥接的对象类及其父类,注意,桥接进来的功能是组合在抽象层Shape上。 |
1 | // demo |
如果除了绘画维度的变化,还有材质维度的变化,那类似的,定义相关功能的接口,然后并列地组合在抽象层
4 装饰模式
【介绍】:
装饰器模式(Decorator Pattern)允许向一个现有的对象添加新的功能,同时又不改变其结构。
通常情况下,扩展一个类的功能会使用继承方式来实现。但继承具有静态特征,耦合度高,并且随着扩展功能的增多,子类会很膨胀。
如果使用组合关系来创建一个包装对象(即装饰对象)来包裹真实对象,并在保持真实对象的类结构不变的前提下,为其提供额外的功能,这就是装饰模式的目标。
【比喻】:
在《绝地求生:刺激战场》游戏里面我们都知道。枪支装上4倍镜后可以进行4倍瞄准;装上8倍镜后可以进行4倍瞄准、8倍瞄准。
四倍,八倍瞄准就是对现有对象的功能拓展。【拥有八倍镜的枪】和【拥有四倍镜的枪】就是两个装饰类,他们都不是通过继承来实现枪的功能,而是通过持有一个枪实现枪的功能。
故而【拥有八倍镜的枪】对象更像是持有了一把枪,并在内部实现了八倍瞄准功能。
如果使用继承模式,那么98k这把枪要实现【4倍98k】和【8倍98k】这两个子类,m4这把枪同样要实现两个子类,非常不灵活。
用装饰模式就很灵活了,不管是什么枪,都可以组合进【拥有八倍镜的枪】这个类中,甚至我们可以将【拥有四倍镜的枪】组合进【拥有八倍镜的枪】中,同时得到两种能力增强。
【优点】:
- 装饰器是继承的有力补充,比继承灵活,在不改变原有对象的情况下,动态的给一个对象扩展功能,即插即用
- 通过使用不同的装饰类,原有对象可以实现不同效果。
- 装饰器模式完全遵守开闭原则
【缺点】:
- 装饰模式会增加许多子类,过度使用会增加程序得复杂性。
- 装饰模式提供了一种比继承更加灵活机动的解决方案,但同时也意味着比继承更加易于出错,排错也很困难,对于多次装饰的对象,调试时寻找错误可能需要逐级排查,较为繁琐。
【应用】:
Java sdk的io包中,inputStream类和outputStream类使用的就是装饰模式,以输入流为例,BufferedInputStream和ByteArrayInputStream等类都继承了inputStream,他们都是装饰类。
如果要给一个输入流装饰缓冲池的功能和读各种基本类型数据的功能,那么可以这么使用:
DataInputStream in=new DataInputStream(new BufferedInputStream(new FileInputStream("D:\\hello.txt")));
装饰模式和代理模式很像,这两个模式的UML图都是一样的。但这两个模式在含义上有点差别。
代理模式是原对象做不了那件事,必须让代理对象去做,主导侧重于代理对象,比如说买车。
装饰模式是说,就是让原对象直接去做这件事,只是功能上增强一点,主导在于原对象。比如说炒菜的时候撒点盐。
【案例】:
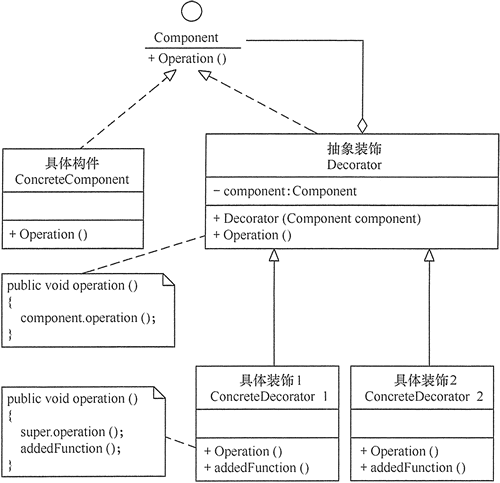
以前文的《绝地求生:刺激战场》游戏为例,我们定义一个gun的接口,一个Kar98K的具体gun,以及可以拓展Kar98K的两个装饰对象,Telescope8XGun和Telescope4XGun。
1 | public interface Gun { |
定义两个不同功能的装饰类:
1 | public abstract class AbstractTelescopeGun implements Gun { |
1 | public class Demo { |
发现没有,装饰模式可以装饰一个已经被装饰了的对象,比如new Telescope8XGun(gun)这句,此时的gun对象是Telescope4XGun对象。
5 外观模式
【介绍】:
外观模式(Facade Pattern)隐藏系统的复杂性,并向客户端提供了一个客户端可以访问系统的接口。
当一个系统的功能越来越强,子系统会越来越多,客户对系统的访问也变得越来越复杂。这时如果系统内部发生改变,客户端也要跟着改变,这违背了“开闭原则”,也违背了“迪米特法则”。
所以有必要为多个子系统提供一个统一的接口,从而降低系统的耦合度,这就是外观模式的目标。
【比喻】:
在现实生活中,常常存在办事较复杂的例子,如注册一家公司,有时要同多个部门联系,这时要是有一个统一的申请入口能解决一切手续问题就好了。
作为客户,不需要了解申请后会发生什么,可能背后涉及多个部门,但对客户来说是无感的。
【优点】:
- 降低了子系统与客户端之间的耦合度,使得子系统的变化不会影响调用它的客户类。
- 对客户屏蔽了子系统组件,减少了客户处理的对象数目,并使得子系统使用起来更加容易。
- 降低了大型软件系统中的编译依赖性,简化了系统在不同平台之间的移植过程,因为编译一个子系统不会影响其他的子系统,也不会影响外观对象。
【缺点】:
感觉没啥缺点,我们在编写代码时已经有此类意识了。
【应用】:
在日常编码工作中,我们都在有意无意的大量使用外观模式。
只要是高层模块需要调度多个子系统(2个以上的类对象),我们都会自觉地创建一个新的类封装这些子系统,提供精简的接口,让高层模块可以更加容易地间接调用这些子系统的功能。
尤其是现阶段各种第三方SDK、开源类库,很大概率都会使用外观模式。
【案例】:
外观(Facade)模式的结构比较简单,主要是定义了一个高层接口。它包含了对各个子系统的引用,客户端可以通过它访问各个子系统的功能。现在来分析其基本结构和实现方法。
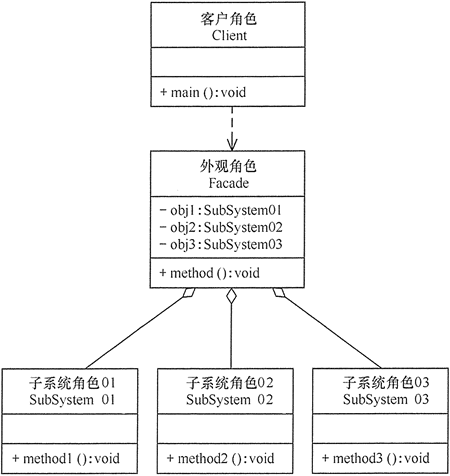
1 |
|
6 组合模式
【介绍】:
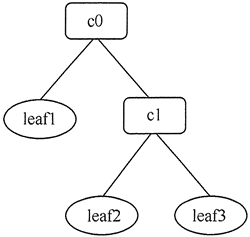
组合模式(Composite Pattern),又叫部分整体模式,是用于把一组相似的对象当作一个单一的对象。组合模式依据树形结构来组合对象,用来表示部分以及整体层次。
组合模式一般用来描述整体与部分的关系,它将对象组织到树形结构中,顶层的节点被称为根节点,根节点下面可以包含树枝节点和叶子节点,树枝节点下面又可以包含树枝节点和叶子节点。
我们把树枝节点称为Composite(容器构件),把叶子节点称为Leaf(叶子构件),同时他们都是Component(抽象构件)。
在使用组合模式时,根据抽象构件类的定义形式,我们可将组合模式分为透明组合模式和安全组合模式两种形式。
透明组合模式
透明组合模式中,抽象构件角色中声明了所有用于管理成员对象的方法,譬如在示例中 Component 声明了 add、remove 方法,这样做的好处是确保所有的构件类都有相同的接口。透明组合模式也是组合模式的标准形式。
透明组合模式的缺点是不够安全,因为叶子对象和容器对象在本质上是有区别的,叶子对象不可能有下一个层次的对象,即不可能包含成员对象,因此为其提供add()、remove()等方法是没有意义的。
安全组合模式
- 在安全组合模式中,在抽象构件角色中没有声明任何用于管理成员对象的方法,而是在容器构件Composite类中声明并实现这些方法。
- 安全组合模式的缺点是不够透明,因为叶子构件和容器构件具有不同的方法,且容器构件中那些用于管理成员对象的方法没有在抽象构件类中定义,因此客户端不能完全针对抽象编程,必须有区别地对待叶子构件和容器构件。
一般我们常用的是安全组合模式
【比喻】:
其实就是我们常见的树状结构,用代码的方式表达出来。
【优点】:
- 组合模式使得客户端代码可以一致地处理单个对象和组合对象,无须关心自己处理的是单个对象,还是组合对象,这简化了客户端代码;
- 更容易在组合体内加入新的对象,客户端不会因为加入了新的对象而更改源代码,满足“开闭原则”;
【缺点】:
- 设计较复杂,客户端需要花更多时间理清类之间的层次关系;
- 不容易限制容器中的构件;
- 不容易用继承的方法来增加构件的新功能;
【应用】:
MyBatis的强大特性之一便是它的动态SQL,其通过if,where,foreach等标签,可组合成非常灵活的SQL语句,从而提高开发人员的效率。
Mybatis在处理动态SQL节点时,应用到了组合设计模式,Mybatis会将映射配置文件中定义的动态SQL节点、文本节点等解析成对应的SqlNode实现,并形成树形结构。
【案例】:
我们来实现一个简单的目录树,有文件夹和文件两种类型,首先需要一个抽象构件类,声明了文件夹类和文件类需要的方法
1 | public abstract class Component { |
实现一个文件夹类Folder,继承Component,定义一个 List
1 | public class Folder extends Component { |
文件类File,继承Component父类,实现getName、print、getContent等方法
1 | public class File extends Component { |
最后
1 | public class Test { |
1 | 设计模式资料 |
7 享元模式
【介绍】:
享元模式(Flyweight Pattern)尽可能的让用户复用已经有的对象,从而避免造成反复创建对象的资源浪费。主要用于减少创建对象的数量,以减少内存占用和提高性能。
在面向对象程序设计过程中,有时会面临要创建大量相同或相似对象实例的问题。创建那么多的对象将会耗费很多的系统资源,它是系统性能提高的一个瓶颈。
例如,围棋和五子棋中的黑白棋子,图像中的坐标点或颜色,局域网中的路由器、交换机和集线器,教室里的桌子和凳子等。这些对象有很多相似的地方,如果能把它们相同的部分提取出来共享,则能节省大量的系统资源,这就是享元模式的产生背景。
元模式的定义提出了两个要求,细粒度和共享对象。因为要求细粒度,所以不可避免地会使对象数量多且性质相近,此时我们就将这些对象的信息分为两个部分:内部状态和外部状态。
- 内部状态指对象共享出来的信息,存储在享元信息内部,并且不会随环境的改变而改变;
- 比如,连接池中的连接对象,保存在连接对象中的用户名、密码、连接URL等信息,在创建对象的时候就设置好了,不会随环境的改变而改变,这些为内部状态。
- 外部状态指对象得以依赖的一个标记,随环境的改变而改变,不可共享。
- 而当每个连接被占用时,我们将其标记为占用状态。要被回收利用时,我们需要将它标记为可用状态,这些为外部状态。
而我们需要共享的部分,就是内部状态的部分数据。外部状态的数据无法共享,需要从享元对象中剥离出来。
【比喻】:
无需比喻,享元模式就是我们常用的缓存的思想。
【优点】:
相同对象只要保存一份,这降低了系统中对象的数量,从而降低了系统中细粒度对象给内存带来的压力。
【缺点】:
- 为了使对象可以共享,需要将一些不能共享的状态外部化,这将增加程序的复杂性。
- 读取享元模式的外部状态会使得运行时间稍微变长。
【应用】:
- Java中的String,如果有则返回,如果没有则创建一个字符串保存在字符串缓存池里面。
- 数据库的数据池。
- Java中的线程池。
【案例】:
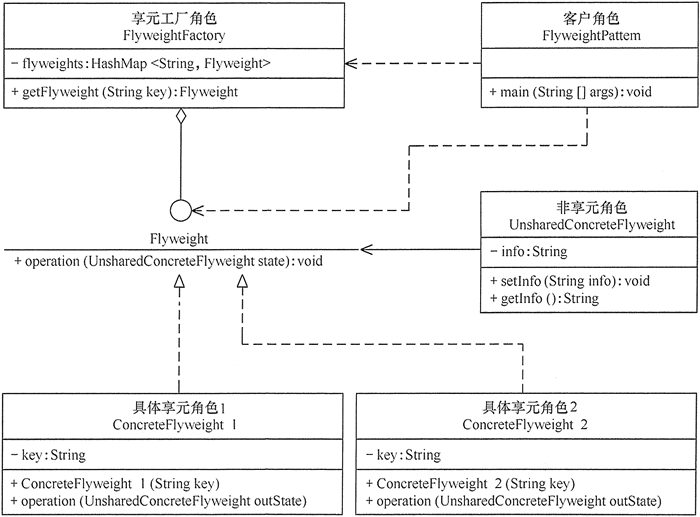
1 |
|
最后输出:
1 | 具体享元a被创建! |
创建型设计模式(工厂/抽象工厂/单例/建造者/原型模式)
前言
因为设计模式种类多,且重理解重回忆,所以本文尽量言简意赅,便于时时温习。
设计模式(Design Pattern)是前辈们对代码开发经验的总结,是解决特定问题的一系列套路。它不是语法规定,而是一套用来提高代码可复用性、可维护性、可读性、稳健性以及安全性的解决方案。
1995年,GoF(Gang of Four,四人组/四人帮)合作出版了《设计模式:可复用面向对象软件的基础》一书,共收录了23种设计模式,从此树立了软件设计模式领域的里程碑,人称「GoF设计模式」。
这 23 种设计模式的本质是面向对象设计原则的实际运用,是对类的封装性、继承性和多态性,以及类的关联关系和组合关系的充分理解。
当然,软件设计模式只是一个引导,在实际的软件开发中,必须根据具体的需求来选择:
对于简单的程序,可能写一个简单的算法要比引入某种设计模式更加容易;
但是对于大型项目开发或者框架设计,用设计模式来组织代码显然更好。
我们要清楚,设计模式并不是Java的专利,它同样适用于C++、C#、JavaScript等其它面向对象的编程语言。
设计原则
开闭原则
开闭原则的含义是:当应用的需求改变时,在不修改软件实体的源代码或者二进制代码的前提下,可以扩展模块的功能,使其满足新的需求。
里氏替换原则
里氏替换原则通俗来讲就是:子类可以扩展父类的功能,但不能改变父类原有的功能。也就是说:子类继承父类时,除添加新的方法完成新增功能外,尽量不要重写父类的方法。
依赖倒置原则
依赖倒置原则的原始定义为:高层模块不应该依赖低层模块,两者都应该依赖其抽象;抽象不应该依赖细节,细节应该依赖抽象。其核心思想是:要面向接口编程,不要面向实现编程。
依赖倒置原则是实现开闭原则的重要途径之一,它降低了客户与实现模块之间的耦合。
单一职责原则
单一职责原则又称单一功能原则,由罗伯特·C.马丁(Robert C. Martin)于《敏捷软件开发:原则、模式和实践》一书中提出的。这里的职责是指类变化的原因,单一职责原则规定一个类应该有且仅有一个引起它变化的原因,否则类应该被拆分。
该原则提出对象不应该承担太多职责,如果一个对象承担了太多的职责,至少存在以下两个缺点:
- 一个职责的变化可能会削弱或者抑制这个类实现其他职责的能力;
- 当客户端需要该对象的某一个职责时,不得不将其他不需要的职责全都包含进来,从而造成冗余代码或代码的浪费。
迪米特法则
迪米特法则的定义是:只与你的直接朋友交谈,不跟“陌生人”说话。其含义是:如果两个软件实体无须直接通信,那么就不应当发生直接的相互调用,可以通过第三方转发该调用。其目的是降低类之间的耦合度,提高模块的相对独立性。
迪米特法则中的“朋友”是指:当前对象本身、当前对象的成员对象、当前对象所创建的对象、当前对象的方法参数等,这些对象同当前对象存在关联、聚合或组合关系,可以直接访问这些对象的方法。
模式分类
根据目的来分类
根据模式是用来完成什么工作来划分,这种方式可分为创建型模式、结构型模式和行为型模式3种。
创建型模式:用于描述“怎样创建对象”,它的主要特点是“将对象的创建与使用分离”。
GoF中提供了单例、原型、工厂方法、抽象工厂、建造者等5种创建型模式。
结构型模式:用于描述如何将类或对象按某种布局组成更大的结构。
GoF中提供了代理、适配器、桥接、装饰、外观、享元、组合等7种结构型模式。
行为型模式:用于描述类或对象之间怎样相互协作共同完成单个对象都无法单独完成的任务,以及怎样分配职责。
GoF中提供了模板方法、策略、命令、职责链、状态、观察者、中介者、迭代器、访问者、备忘录、解释器等11种行为型模式。
根据作用范围来分类
根据模式是主要用于类上还是主要用于对象上来分,这种方式可分为类模式和对象模式两种。
类模式:用于处理类与子类之间的关系,这些关系通过继承来建立,是静态的,在编译时刻便确定下来了。
GoF中的工厂方法、(类)适配器、模板方法、解释器属于该模式。
对象模式:用于处理对象之间的关系,这些关系可以通过组合或聚合来实现,在运行时刻是可以变化的,更具动态性。
GoF中除了以上4种,其他的都是对象模式。
| 创建型模式 | 结构型模式 | 行为型模式 | |
|---|---|---|---|
| 类模式 | 工厂方法 | (类)适配器 | 模板方法、解释器 |
| 对象模式 | 单例、原型、抽象工厂、建造者 | 代理、(对象)适配器、桥接、装饰、外观、享元、组合 | 策略、命令、职责链、状态、观察者、中介者、迭代器、访问者、备忘录 |
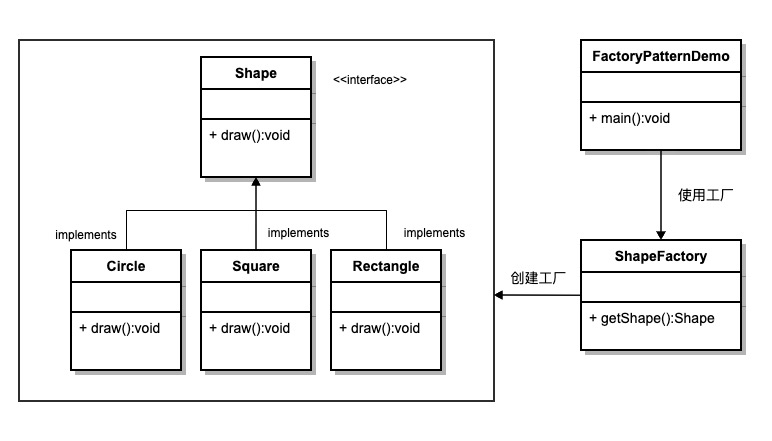
1 工厂模式
【介绍】:
工厂模式(Factory Pattern)是Java中最常用的设计模式之一,它提供了一种创建对象的最佳方式。
在工厂模式中,我们创建对象的逻辑不会对客户端暴露,而是收口在特定类型产品对应的工厂类中。
【比喻】:
您需要一辆汽车,可以直接从工厂里面提货,而不用去管这辆汽车是怎么做出来的,以及这个汽车里面的具体实现。制造汽车的逻辑都收敛在工厂中。
奔驰工厂实现了汽车工厂类,可以制造奔驰汽车,宝马工厂也实现了汽车工厂类,制造的是宝马汽车。你需要什么车,就调用对应工厂获得。
【优点】:
一个调用者想创建一个对象,只要知道其名称就可以了。
扩展性高,如果想增加一个产品,只要扩展一个工厂类就可以。
屏蔽产品的具体实现,调用者只关心产品的接口。
【缺点】:
每次增加一个产品时,都需要增加一个具体类和对象实现工厂,使得系统中类的个数成倍增加,在一定程度上增加了系统的复杂度,同时也增加了系统具体类的依赖。
复杂对象适合使用工厂模式,而简单对象,特别是只需要通过new 就可以完成创建的对象,无需使用工厂模式。如果使用工厂模式,就需要引入一个工厂类,会增加系统的复杂度。
【应用】:
- Spring框架中BeanFactory,bean生成的创建逻辑,都收敛在其中。
【案例】:
如下图,FactoryPatternDemo 类使用ShapeFactory来获取Shape对象。它将向 ShapeFactory 传递信息(CIRCLE/RECTANGLE/SQUARE),以便获取它所需对象的类型。
1 | public class ShapeFactory { |
2 抽象工厂模式
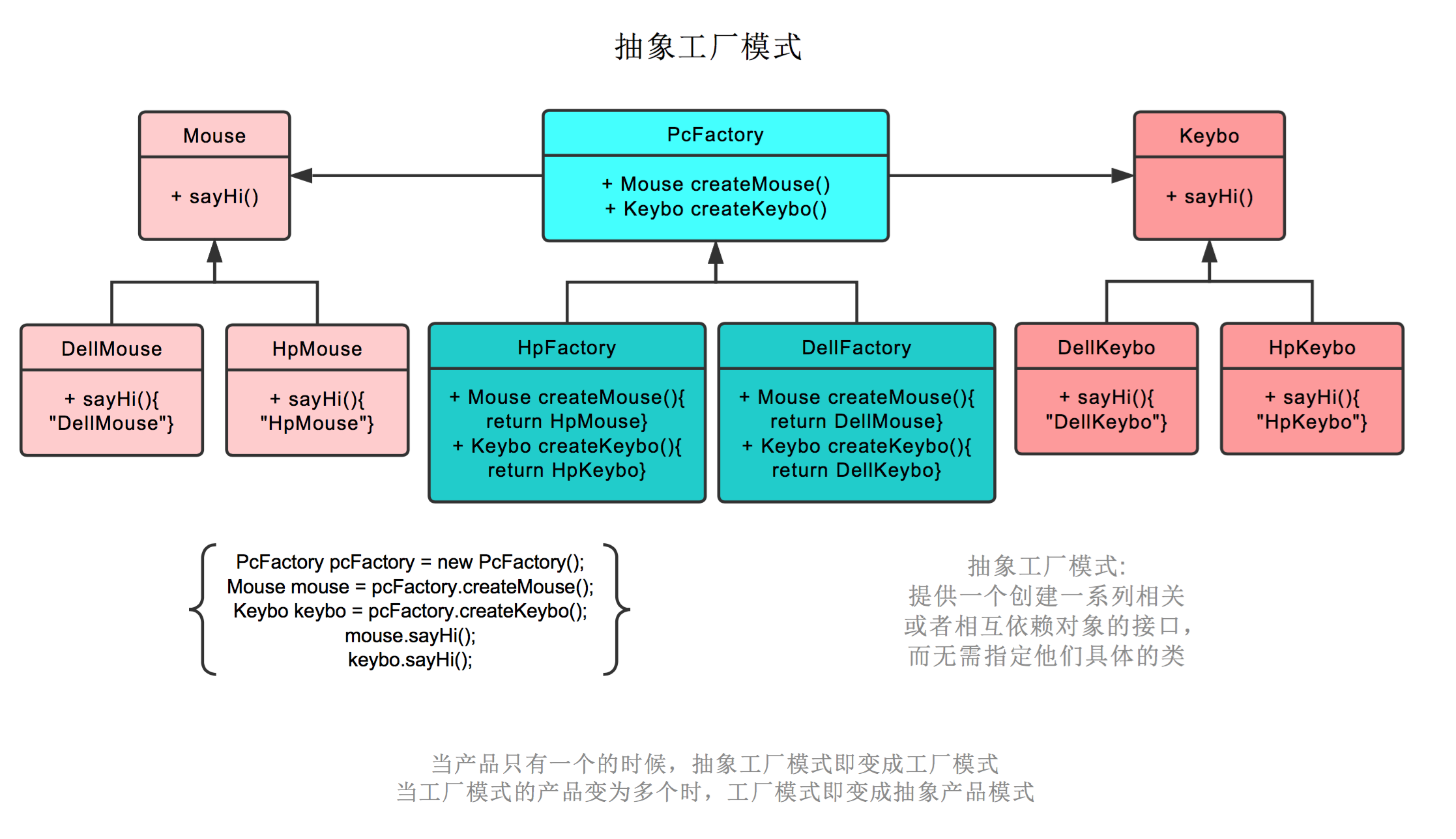
【介绍】:
抽象工厂模式(Abstract Factory Pattern)是一种为访问类提供一个创建一组相关或相互依赖对象的接口,且访问类无须指定所要产品的具体类就能得到同组的不同产品的模式结构。
抽象工厂模式是工厂方法模式的升级版本,工厂模式只生产一个类型的产品,而抽象工厂模式集合了同组的工厂,可生产同组多个类型的产品。
抽象工厂模式主要设计产品组的概念,就是某一个工厂生产出配套的一系列产品。例如,在生产足球的同时,SoccerFactory还可以生产与之配套的足球杂志。
【比喻】:
前面介绍的工厂模式中考虑的是一类产品的生产,如汽车厂只生产轿车。而这里抽象工厂模式,则是综合汽车厂的模式,它拥有汽车厂,卡车厂,特种车厂。
或者换个维度,抽象工厂模式也可以是全产业链汽车厂,它拥有汽车厂,轮胎厂,汽车车标厂等等。
奔驰车厂实现抽象工厂类,可分别生产奔驰车,奔驰轮胎和奔驰车标。我们如果需要一套奔驰牌的东西,直接调用奔驰车厂就行。宝马车厂同理。
【优点】:
当一个产品组中的多个对象被设计成一起工作时,它能保证客户端从单个抽象工厂类中始终只能获取同一个产品组中的对象。如从奔驰车厂中获取的,不管是轮胎还是汽车,肯定都是奔驰牌。
我如果想替换一整套的组合,那么只要替换奔驰车厂为宝马车厂类就行了,这样汽车,轮胎和车标,都自动换成了宝马牌。
【缺点】:
产品组的扩展非常困难,要增加一个系列的某一产品,既要在抽象的工厂里加代码,又要在具体的新产品类里面加代码。
【应用】:
- java JDK中的java.sql.Connection类。MySQLConnection和OracleConnection等继承了它,并在各自的内部,实现了自己专用的Statement/PreparedStatement/CallableStatement对象。
【案例】:
抽象工厂模式也就是不仅生产鼠标,同时生产键盘。PC厂商是个父类,有生产鼠标,生产键盘两个接口。戴尔工厂,惠普工厂继承它,可以分别生产戴尔鼠标+戴尔键盘,和惠普鼠标+惠普键盘。
1 | public abstract class PcFactory { |
1 | public class DellFactory extends PcFactory{ |
1 | public class HpFactory extends PcFactory{ |
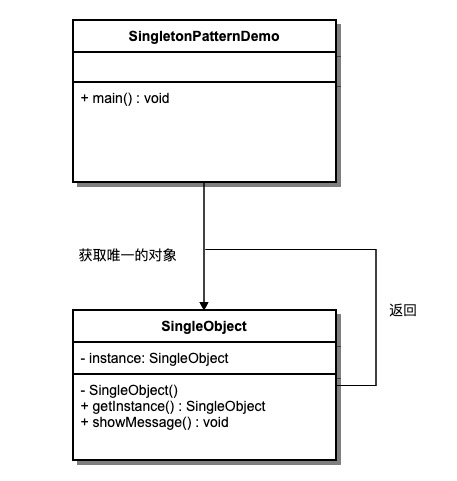
3 单例模式
【介绍】:
单例模式(Singleton Pattern),它的定义就是确保某一个类只有一个实例,并且提供一个全局访问点。
单例模式具备典型的3个特点:1、只有一个实例。 2、自我实例化。 3、提供全局访问点。
因此当系统中只需要一个实例对象或者系统中只允许一个公共访问点,除了这个公共访问点外,不能通过其他访问点访问该实例时,可以使用单例模式。
【比喻】:无
【优点】:
- 在内存里只有一个实例,减少了内存的开销,尤其是频繁的创建和销毁实例(比如管理学院首页页面缓存)。
- 避免对资源的多重占用(比如写文件操作)。
【缺点】:
- 没有接口,不能继承,与单一职责原则冲突,一个类应该只关心内部逻辑,而不关心外面怎么样来实例化。
【应用】:
- spring框架中的ApplicationContext
- 数据库中的连接池
【案例】:
我们将创建一个Singleton类。Singleton 类有它的私有构造函数和本身的一个静态实例。
Singleton类提供了一个静态方法,供外界获取它的静态实例。
1 | // 第1种:懒汉式单例,线程不安全,懒加载 |
1 | // 第2种:饿汉式单例,线程不安全,非懒加载 |
1 | // 第3种:双检锁/双重校验锁单例,线程安全,懒加载 |
1 | // 第4种:登记式/静态内部类,线程安全,懒加载 |
1 | // 第5种:枚举,线程安全,非懒加载 |
一般情况下,不建议使用懒汉方式,建议使用第2种饿汉方式。只有在要明确实现lazy loading效果时,才会使用第4种登记方式。如果涉及到反序列化创建对象时,可以尝试使用第5种枚举方式。如果有其他特殊的需求,可以考虑使用第3种双检锁方式。
4 建造者模式
【介绍】:
建造者模式(Builder Pattern)使用多个简单的对象一步一步构建成一个复杂的对象。一个Builder类会一步一步构造最终的对象。该 Builder 类是独立于其他对象的。
【比喻】:
将一个复杂对象分布创建。如果一个超大的类的属性特别多,我们可以把属性分门别类,不同属性组成一个稍微小一点的类,再把好几个稍微小点的类窜起来。
比方说一个电脑,可以分成不同的稍微小点的部分CPU、主板、显示器。CPU、主板、显示器分别有更多的组件,不再细分。
生活中这样的例子很多,如游戏中的不同角色,其性别、个性、能力、脸型、体型、服装、发型等特性都有所差异;还有汽车中的方向盘、发动机、车架、轮胎等部件也多种多样;每封电子邮件的发件人、收件人、主题、内容、附件等内容也各不相同。
【优点】:
- 建造者独立,易扩展。
- 便于控制细节风险。
【缺点】:
- 产品必须有共同点,范围有限制。
- 如内部变化复杂,会有很多的建造类。
【应用】:
主要应用在如下情况中:有时候面临着”一个复杂对象”的创建工作,其通常由各个部分的子对象用一定的算法构成;由于需求的变化,这个复杂对象的各个部分经常面临着剧烈的变化,但是将它们组合在一起的算法却相对稳定。
- java JDK的StringBuilder类。
- Zookeeper的Java客户端CuratorFrameworkFactory类中的Builder内部类。
- Spring中的BeanDefinitionBuilder类。
【案例】:
以组装一台电脑为例,电脑包含了主机,操作系统,显示器三个核心部分。我们定义抽象的Builder,在生产一个具体的MacbookBuilder,用来创建MacBook。
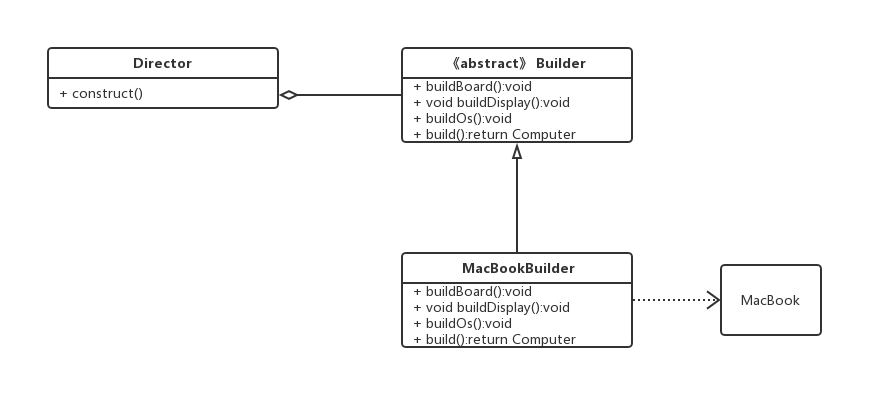
1 | // 定义电脑的抽象类 |
1 | // 抽象的Builder |
Director类,负责具体的构造 Computer
1 | public class Director { |
5 原型模式
【介绍】:
原型模式(Prototype Pattern)是用于创建重复的大对象,它实现了一个原型接口,该接口用于创建当前对象的克隆。当直接创建对象的代价比较大时,则可以采用这种模式。
例如,一个对象需要在一个高代价的数据库操作之后被创建。我们可以缓存该对象,在下一个请求时返回它的克隆,在需要的时候更新数据库,以此来减少数据库调用。
与通过对一个类进行实例化来构造新对象不同的是,原型模式是通过拷贝一个现有对象生成新对象的。浅拷贝实现Cloneable的重写,深拷贝是通过实现Serializable读取二进制流。
【比喻】:
原型模式的创建的对象是一个克隆对象,可以理解成科幻电影中的克隆机器人,直接生产一个机器人可能需要巨大的代价(比如要消耗大量的IO资源或者硬盘资源,或者调用大量的数据库数据等),那么我们就以某个已经生产出来的机器人为原型或者模板,采用克隆技术去复制它。
【优点】:
- Java自带的原型模式基于内存二进制流的复制,在性能上比直接new一个对象更加优良。
- 逃避构造函数的约束。
【缺点】:
- 需要为每一个类都配置一个clone方法
- clone方法位于类的内部,当对已有类进行改造的时候,需要修改代码,违背了开闭原则。
- 当实现深克隆时,需要编写较为复杂的代码,而且当对象之间存在多重嵌套引用时,为了实现深克隆,每一层对象对应的类都必须支持深克隆,实现起来会比较麻烦。因此,深克隆、浅克隆需要运用得当。
【应用】:
spring中,scope=”singleton”和scope=”prototype”分别表示该bean是单例模式还是非单例模式。prototype作用域部署的bean,每一次请求(将其注入到另一个bean中,或者以程序的方式调用容器的getBean()方法)都会产生一个新的bean实例,这内部就是使用了原型模式。
【案例】:
我们将创建一个抽象类Shape和扩展了Shape类的实体类。下一步是定义类ShapeCache,该类把shape对象的原型存储在一个Hashtable中,并在请求的时候返回它们的克隆。
1 | // 定义父类shape,三个子类我们就不赘述了 |
1 | public class ShapeCache { |
1 | // PrototypePatternDemo 使用 ShapeCache 类来获取存储在 Hashtable 中的形状的克隆。 |
JAVA中浮点型数据的存储方式
前言
在JAVA中,我们知道int和float占用4个字节,double和long占用8个字节。
那为何int和long的取值范围分别是[-2^31,2^31],float的取值范围却是[-3.40282346638528860e+38 , -1.40129846432481707e-45] ∪ [1.40129846432481707e-45 ~ 3.40282346638528860e+38]?(long和double同理)
或者我们看如下这道题:
1 | public static void main(String[] args) { |
答案是f_v2==d_v2为false,而f_v3==d_v3为true。
一切的原因,都要从java对于浮点型数据的存储说起。
我们开门见山,直接给出将十进制浮点数存储到内存空间中需要的步骤:
- 将十进制浮点数转为二进制浮点数
- 将二进制浮点数再转换成科学计数法
- 优化空间,使用一些技巧,提升存储效率
1 将十进制浮点数转为二进制浮点数
计算机的存储是基于二进制的,要存储一个十进制浮点数,那么必然要先将这个其转为二进制。对于整数的十进制转二进制,我想我们大家都很熟悉,那么对于一个浮点数,十进制如何转为二进制呢?
浮点数可以分为三个部分:符号部分,整数部分,小数部分。
符号部分我们先不论,我们来看一个浮点数20.3:
整数部分:
整数部分是20,转二进制变成10100
小数部分:
小数部分是0.3,小数转为二进制,在java中有如下规则:
- 将小数部分乘2,得到一个小数res。
- 取res的整数部分为当前bit的值。
- 再取res的小数部分接着乘2。
- 重复上述过程,直至最后没有小数或者小数出现循环。
以0.3为例:
0.3 * 2 = 0.6 (取整数0)
0.6 * 2 = 1.2 (取整数1)
0.2 * 2 = 0.4 (取整数0)
0.4 * 2 = 0.8 (取整数0)
0.8 * 2 = 1.6 (取整数1)
0.6 * 2 = 1.2 (取整数1)
计算到这里,将再出现0.6,进入循环了,所以最终0.3的二进制结果是:0.3 = 0.01001 1001 1001...1001
所以20.3 = 10100.01001 1001 1001...1001
再以0.5为例:
0.5 * 2 = 1.0 (取整数1)
0 * 2 = 0 (取整数0)
计算到这里出现0了,计算结束。所以,转换后0.5 = 0.1
所以20.5 = 10100.1
2 将二进制浮点数转换成科学计数法
如果要把十进制浮点数,存储到内存空间中,也就是4或者8个字节中,那么还需要进一步将二进制的浮点数转换成科学计数法。
我们可以很容易得到以下等式
20.5(十进制) = 10100.1(二进制) = 1.01001E4(十进制科学计数) = 1.01001E100(二进制科学计数)
20.3(十进制) = 10100.01001 1001...1001(二进制) = 1.010011001...1001E4(十进制科学计数) = 1.010011001...1001E100(二进制科学计数)
这里E100指10的4次方,4也要二进制表示就是100;
用以科学计数法表示的1.01001 E 100举例,1.01001部分叫做尾数;E叫做基数,在科学计数法里E=10;100部分叫做指数;
那么我们要存储1.01001E100,要存哪些信息呢?
- 尾数1.01001要存,如果遇到像0.3那样的无限循环的尾数,空间不够存储的部分直接舍弃就好,这也是为什么浮点数会有精度问题的原因。
- 基数E不要存,因为E固定等于10。
- 指数100要存。
- 除此之外还有遗漏吗?当然,别忘了正负的符号,这也需要一个bit来存。
所以我们可以看到,float和double的存储结构是这样的:
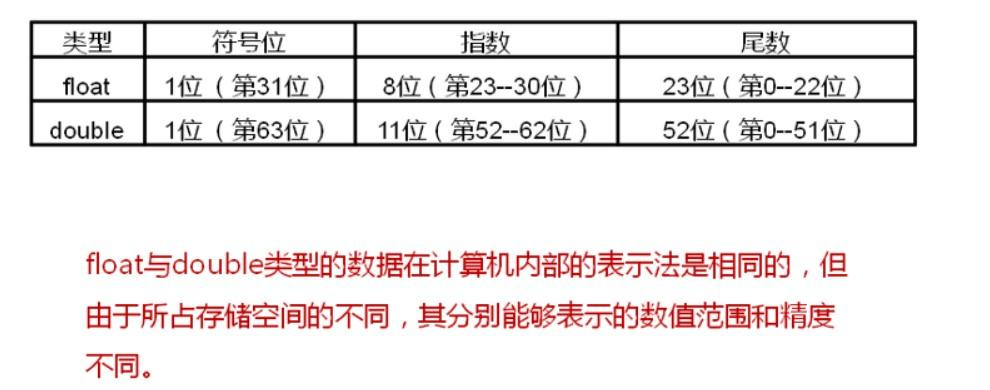
那么1.01001E100,我们是不是只要将符号位0、尾数位1.01001和指数位100分别存入对应空间就行了呢?当然这么存也是可以的,但为了节约空间,java设计了一些小技巧,使得空间的利用率更大。
3 优化空间
3.1 尾数的首位1舍弃
尾数1.01001要存,但不用全部都存,因为尾数第一位固定是1,我们没必要存,只要存.01001就行,这样就节省了一个bit。
3.2 指数位采用移位存储法
值得注意的是指数位的存储,float指数位有8bit,正常情况下,我们可以用常规的第一个bit表示符号,后面7个bit表示数值的存法,这样存储的指数值从-2^7到2^7。(double同理)
然而java中对指数位,采用的是移位存储法,即指数值的二进制,先加上127(float)或者1023(double),再存储。
如1.01001E100中指数是100,存入float中,那么要先加127:
1 | 00000100 |
所以20.5存储在float中是这样的: 0 | 10000011 | 01001 00000 00000 00000 000
为什么不用传统的存储法,而要采用移位存储法呢?因为传统的存储法,0 000000和1 000000都表示十进制的0,只不过前者是+0,后者是-0;两个0含义相同,而float指数位只有8bit,最多只能表示256个数,现在两个等价的0占用了两种表示方法,那就有一种表示方法被浪费了。而使用移位存储法,则没有正负0的问题,不会造成浪费。
4 结语
最后回到我们在前言的题目:为什么2.3f==2.3d为false,而2.5f==2.5f为true。
我们可以知道:
- 2.5的存储是:
- float:
0 | 10000011 | 01001000....(补0直到23位) - double:
0 | 1000 000 0011 | 01001....(补0直到52位)
- float:
- 2.3的存储是:
- float:
0 | 10000011 | 010011001...(循环直到23位) - double:
0 | 1000 000 0011 | 010011001...(循环直到52位)
- float:
在先强转后比较的时候,比如float转成double,会将指数部分先-127,得到原始的指数二进制值,再将其+1023,得到double类型的指数值,位数不足的在高位补零。double转为float同理。所以强转和比较,指数部分是没有问题的。
重点就在于尾数部分,float转成double,会在尾数的后面补0,double转为float,则删掉后面多余的尾数位。
对于2.5来说,转换时增删的部分都是0,所以不影响比较的大小。
而对于2.3来说,增删的部分,删掉的是循环的1001,增的却是0,这就导致了2.3f和2.3d的尾数部分不相等。
【I/O设计总结三】详解Reactor/Proactor高性能IO处理模式
前言
随着IO多路复用技术的出现,出现了很多事件处理模式,其中Reactor/Proactor模式是其中的佼佼者。
Reactor模式是非阻塞同步的I/O模型,Proactor模式是非阻塞异步I/O模型。
平时接触的开源产品如Netty、Mina、Redis、ACE,事件模型都使用的Reactor模式;
而同样做事件处理的Proactor,由于缺少操作系统支持的原因,相关的开源产品也少;这里学习下其模型结构,重点对比下两者的异同点;
1 Reactor事件处理模型
我们来回顾一下《【I/O设计总结一】五种I/O模型总结》中学习的IO多路复用模型:
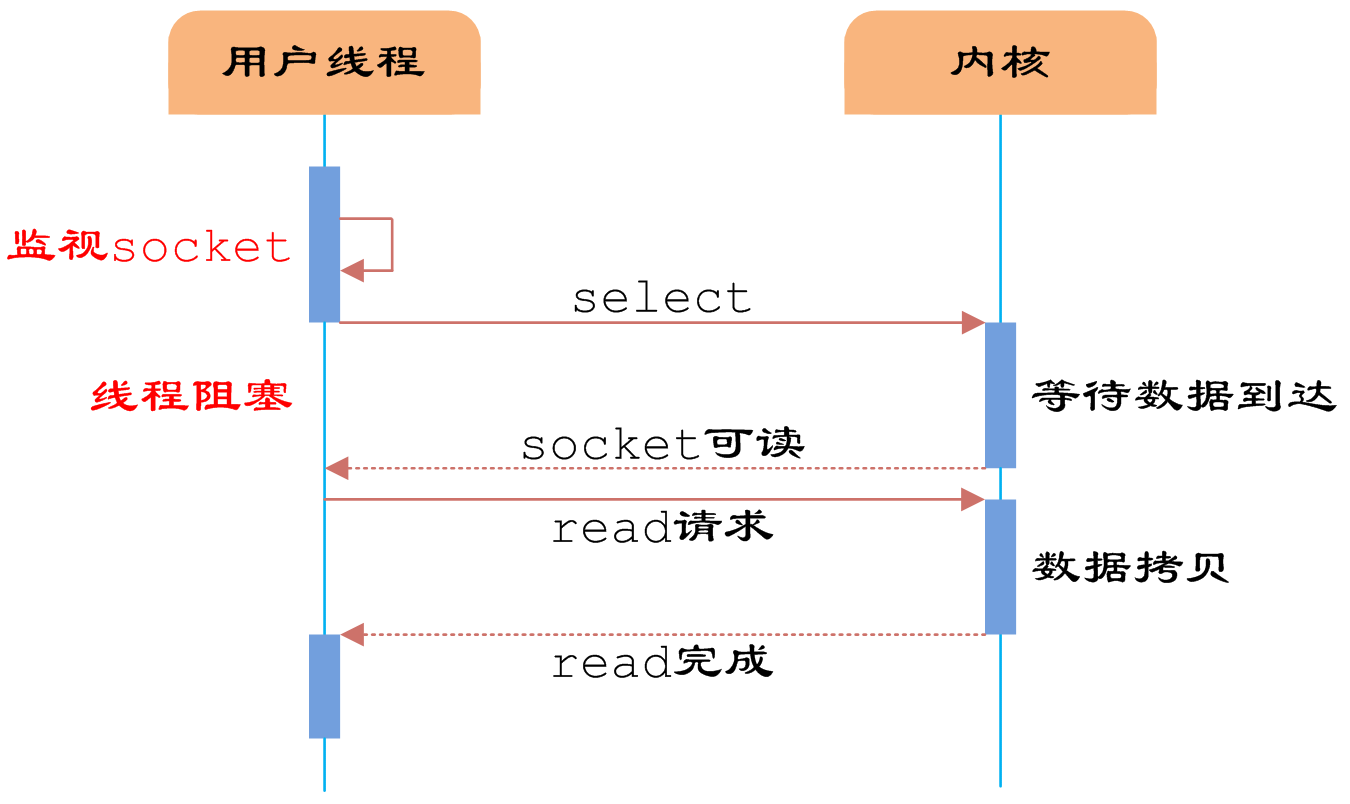
同时,我们在《【I/O设计总结二】详解IO多路复用和其三种模式——select/poll/epoll》一文中,我们介绍了linux系统的select,poll和epoll三个事件的分发函数,我们可以直接编写代码,让应用线程去调用这三个函数中的某一个,完成最简单的IO多路复用模型,也就是如上图所示的这般流程。
这样原始版本的IO多路复用模型好吗?显然不好,直接调用无法并发,效率太低,如果当前的请求没有处理完,那么后面的请求只能被阻塞,服务器的吞吐量太低。
利用线程池技术稍加改进,我们想到了经典的connection per thread,每一个连接用一个线程处理,对于每一个请求都分发给一个线程,每个线程中都独自处理I/O操作。tomcat服务器的早期版本确实是这样实现的。
一连接一线程的方式当然有很多优点,但缺点也很明显:对于资源要求太高,系统中创建线程是需要比较高的系统资源的,如果连接数太高,系统无法承受,而且,线程的反复创建-销毁也需要代价。
这时,我们采用了基于事件驱动的设计,当有事件触发时,才会调用处理器进行数据处理。Reactor模式应运而生。
Reactor是“事件反应”的意思,可以通俗地理解为“来了一个事件Reactor就有相应的反应”,具体的反应就是我们写的业务代码,Reactor会根据事件类型来调用相应的代码进行处理。
Reactor模式也叫Dispatcher模式(在很多开源的系统里面会看到这个名称的类,其实就是实现Reactor模式的),分发确实更加贴近模式本身的含义,即I/O多路复用统一监听事件,收到事件后分发(Dispatch)给某个进程。
归根结底,Reactor就是基于事件驱动设计,利用回调和线程池技术来高效率使用select等函数的设计。
1.1 Reactor模型的架构
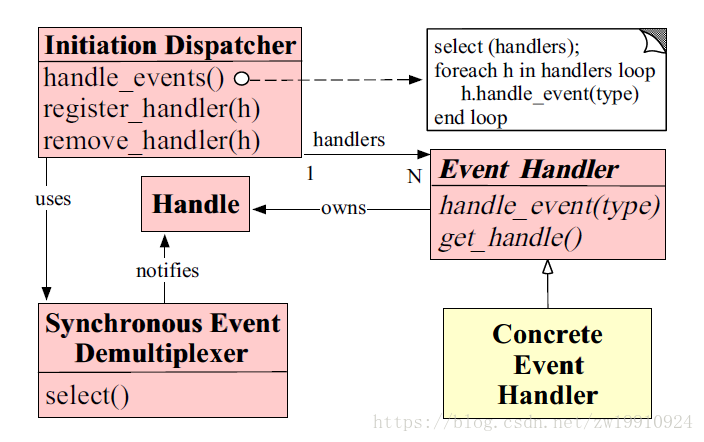
模型架构如上图所示,我们来一一解释这些控件:
- Handle:句柄,用来封装或标识socket连接或是打开文件,你可以理解为在模型中,它代表一个连接或者I/O流文件。
- Event Handler:事件处理接口,用来绑定某个handle和应用程序所提供的特定事件处理逻辑。Concrete Event HandlerA和Concrete Event HandlerB是它的具体实现类,应用程序可针对不同的连接(handle)定制不同的处理逻辑(event)。
- Synchronous Event Demultiplexer:同步事件多路分解器,由操作系统内核实现的一个函数(如Linux的select/poll/epoll);用于阻塞等待发生在句柄集合上的一个或多个事件;返回就绪的Event Handler集合。Java NIO的Selector就是一个Demultiplexer。
- Initiation Dispatcher:分发器,定义一个接口,实现以下功能:
- register_handle():供应用程序注册它定义的Event Handler。即应用程序通过该方法将Event Handler加入Reactor的Synchronous Event Demultiplexer。
- remove_handle():供应用程序删除Synchronous Event Demultiplexer中关注的Event Handler。
- handle_events():核心方法,也是Reactor模式的发动机,这个方法的核心逻辑如下:
- 首先通过同步事件多路选择器提供的select()方法监听网络事件。
- 当有网络事件就绪后,就遍历注册的Event Handler,找到对应的Event Handler来处理该网络事件。
- handle_events()是非阻塞的,主程序可以调用handle_events()后继续其他的操作,handle_events()内的逻辑会触发轮询,回调等操作。调用一次handle_events只会触发一次轮询检查。
- 如果主程序是服务端的话,由于网络事件是源源不断的,主程序一般会不停调用Dispatcher的handle_events()。比如一个server服务端,开辟一个线程,循环调用handle_events(),非阻塞同步性的处理多个客户端的连接。
Demultiplexer和Dispatcher是Reactor的核心,如果我们看到有人说Reactor负责监听和分发事件,那么其实就是将Demultiplexer和Dispatcher整合成一个Reactor组件来描述。
下文的图,以及描述中出现的单Reactor和多Reactor,指的就是Demultiplexer+Dispatcher的组合提,即Reactor=Demultiplexer+Dispatcher
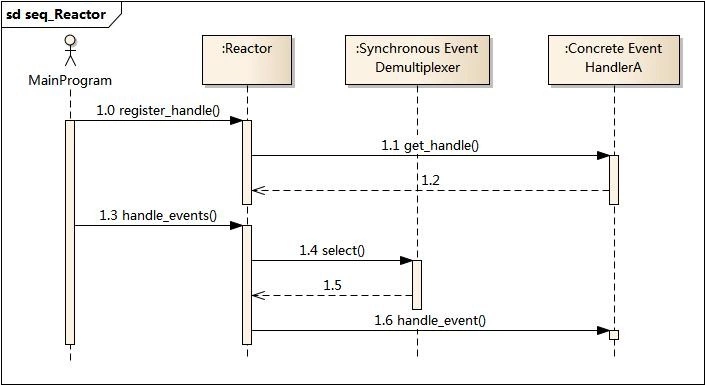
由图可以看到,Reactor模型的简单流程就是:
- 每当有一个客户端连接进来,被服务端接收到,服务端就会将这个连接封装为一个handle,同时会创建的一个个Event Handler,将handle封装进去,并在Event Handler内设定响应的回调函数。
- 服务端调用Dispatcher的register_handle()方法,将Event Handler注册进来。
- 服务端会不停的调用Dispatcher的handle_events()方法,而handle_events()方法会调用Demultiplexer的select()方法,得到就绪的Event Handler。然后调用这个Event Handler的handle_event()方法,执行回调函数。
1.2 Reactor模型的实现方案
Reactor模式的设计,一般和资源池(进程池或线程池)相配合。其中Reactor组件包含Demultiplexer和Dispatcher这两个组件,包含数量不固定,分别负责监听和分配事件,处理资源池负责调度来处理事件。
初看Reactor的实现是比较简单的,但实际上结合不同的业务场景,Reactor模式的具体实现方案灵活多变,主要体现在:
- Reactor的数量可以变化:可以是一个Reactor,也可以是多个Reactor。
- 资源池的数量可以变化:以进程为例,可以是单个进程,也可以是多个进程,线程同理。
将上面两个因素排列组合一下,理论上可以有 4 种选择,但由于多Reactor单进程实现方案相比单Reactor单进程方案,既复杂又没有性能优势,因此多Reactor单进程方案仅仅是一个理论上的方案,实际没有应用。
最终Reactor模式有这三种典型的实现方案:
- 单Reactor单进程/线程。
- 单Reactor多线程。
- 多Reactor多进程/线程。
以上方案具体选择进程还是线程,更多地是和编程语言及平台相关。例如,Java语言一般使用线程(例如,Netty),C语言使用进程和线程都可以。例如,Nginx使用进程,Memcache使用线程。
1.2.1 非Reactor的传统模型
为了比较Reactor模型的优势,我们先来介绍一下Reactor模型出现以前的传统模型,Java OIO(old IO)时代,这种模型经常被使用:客户端与服务端建立好连接过后,服务端对每一个建立好的连接使用一个handler来处理,而每个handler都会绑定一个线程。
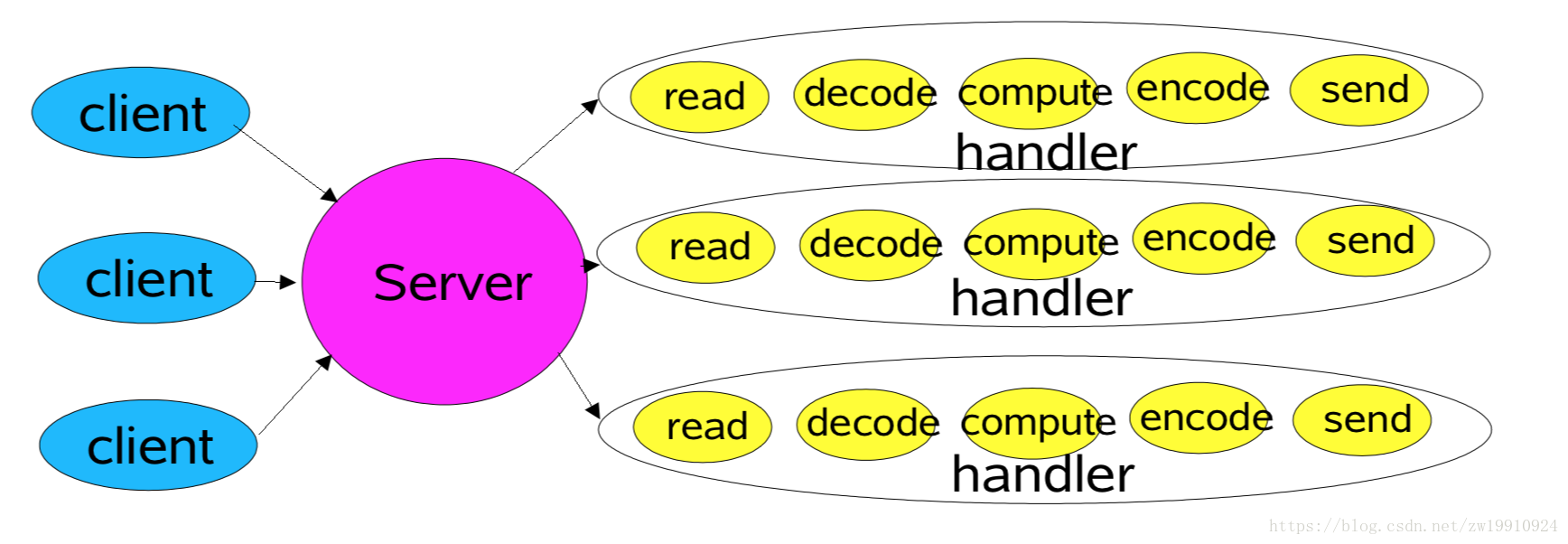
图中的acceptor是注册的一个特殊的Event Handler,负责创建连接的请求,如果Dispatcher接收到某个客户端请求,发现是创建连接的请求,那么就会直接将其转发给acceptor来处理。
这样做在连接的客户端不多的情况下,也算是个不错的选择。但在连接的客户端很多的情况下就会出现问题:
- 每一个连接服务端都会产生一个线程,当并发量比较高的情况下,会产生大量的线程。
- 在服务端很多线程的情况下,大量的线程的上下文切换是一个很大的开销,会比较影响性能。
- 与服务端连接建立后,连接上未必是时时刻刻都有数据进行传输的,但是创建的线程一直都在,会造成服务端线程资源的一个极大的浪费。
1.2.2 单线程Reactor模型
介绍了非Reactor的传统模型,我们再来介绍Reactor模型的朴素原型——单线程Reactor模型。这是Java NIO常用的模型。
由于Java OIO的网络编程模型在客户端很多的情况下回产生服务端线程数过多的问题,因此根据Reactor模式做出了改进。
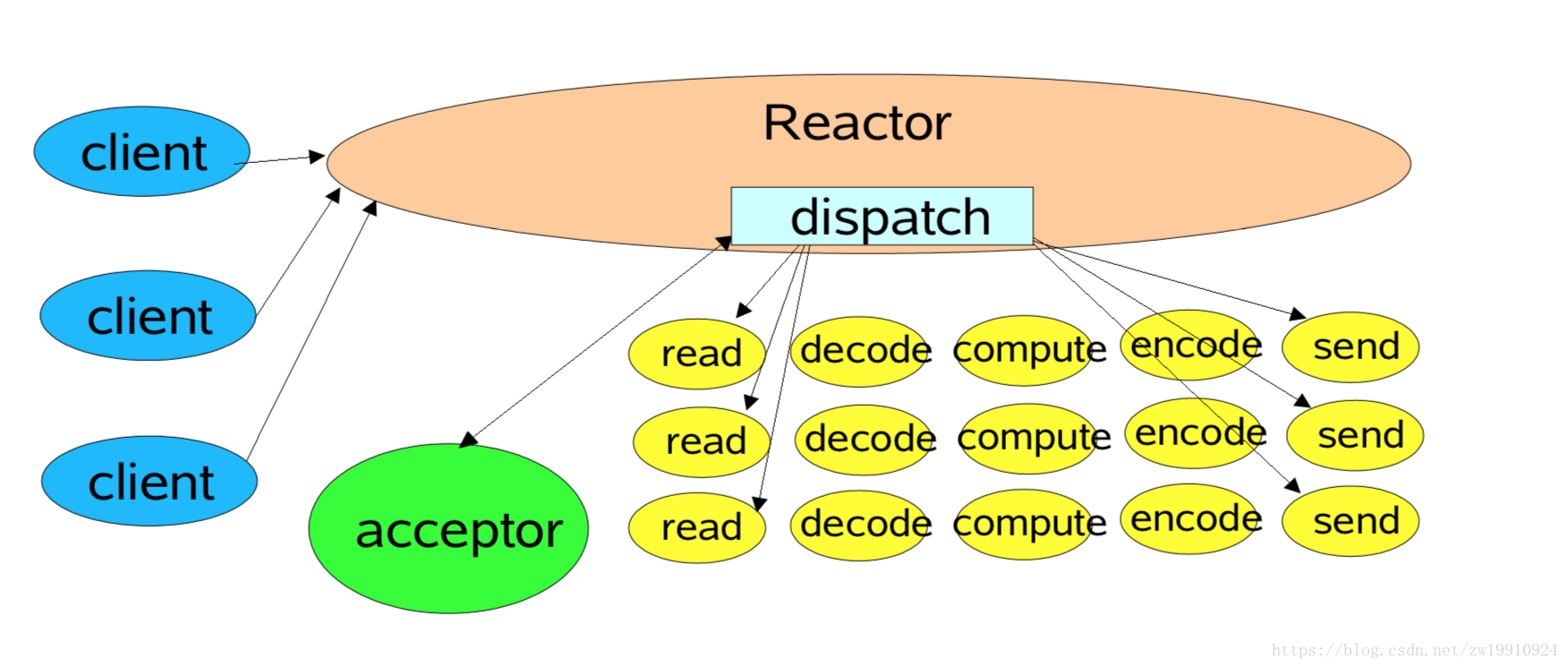
根据上图,Reactor角色对IO事件进行监听(Demultiplexer负责)和分发(Dispatcher负责)。当事件产生时,Dispatcher会将handle分发给对应的处理器Event Handler进行处理。
面对IO阻塞,传统OIO使用多线程来消除阻塞的影响,一个socket开启一个线程来处理以防止一个连接IO的阻塞影响到其他的连接的处理。
而在单线程Reactor模型中,通过Reactor对于IO事件的监听和分发,服务端只需要一个IO线程就能处理多个客户端的连接。这就解决了导致服务端线程数过多的问题。
Reactor的单线程模式的单线程主要是针对于IO操作而言,也就是所有的IO的accept()、read()、write()以及connect()操作都在一个线程上完成的。
这个线程可以是服务端调用Dispatcher.handle_events()的线程,也可以是Dispatcher自己无限循环调用handle_events()的线程。我们称这个线程为Reactor的IO线程。
这个IO线程会循环调用Dispatcher的handle_events()方法,handle_events()方法会继续调用Demultiplexer的select方法,轮询检查注册进来的Event Handler中的handle,如果发生事件,那么回调Event Handler的handle_event(),执行包括read、decode、complete、encode、send的完整IO处理逻辑。
但是这种模型还是有缺陷的,那就是所有的客户端的请求都由一个IO线程来进行处理。当并发量比较大的情况下,服务端的处理性能无法避免会下降,因为服务端IO线程每次只能处理一个客户端的请求,其他的请求只能等待。
1.2.3 多线程Reactor模型
在目前的单线程Reactor模式中,不仅IO操作在该Reactor的IO线程上,连非IO的业务操作也在该线程上进行处理了,这可能会大大延迟IO请求的响应。所以我们应该将非IO的业务逻辑操作从Reactor线程上卸载,以此来加速Reactor线程对IO请求的响应。
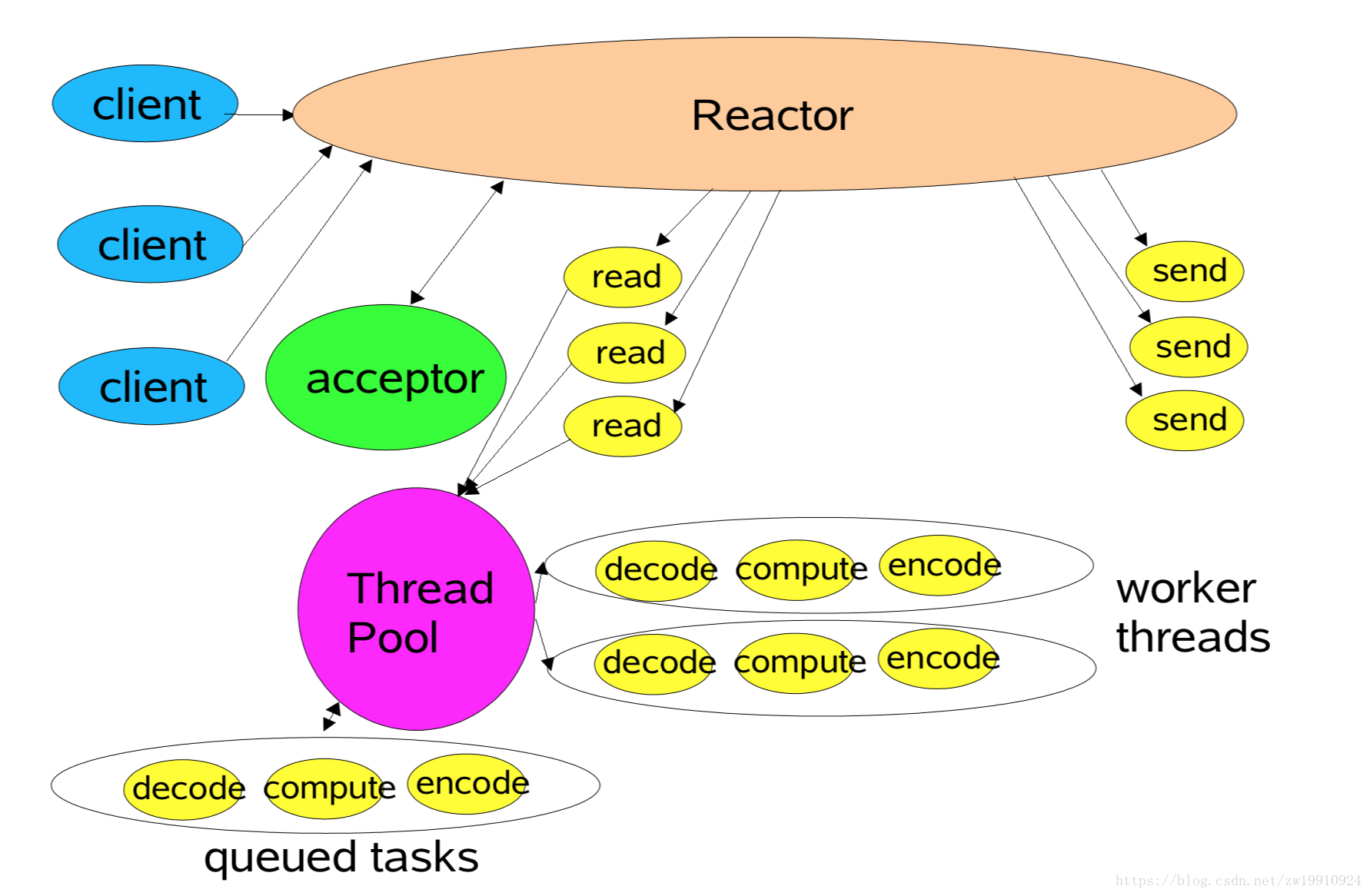
如上图所示,Reactor还是一个IO线程,负责监听IO事件以及分发。只不过在事件发生时,Dispatcher回调Event Handler的handle_event(),只会执行read和send操作,中间的业务逻辑处理部分,即decode、complete、encode,都使用了一个线程池来进行处理,这样能够提高Reactor线程的I/O响应,不至于因为一些耗时的业务逻辑而延迟对后面I/O请求的处理,解决了服务端单线程处理请求而带来的性能瓶颈。
但是这样还是有问题,这样会把性能的瓶颈转移到IO处理上。因为IO事件的监听和分发采用的还是单个线程,在并发量比较高的情况下,这个也是比较影响性能的。这是否还有继续优化的空间呢?
1.2.4 多线程多Reactor模型
虽然多线程Reactor模型将非I/O操作交给了线程池来处理,但是所有的I/O操作依然由Reactor单线程执行,在高负载、高并发或大数据量的应用场景,依然较容易成为瓶颈。所以,对于Reactor的优化,又产生出下面的多Reactor模式。

对于多个CPU的机器,为充分利用系统资源,将Reactor拆分为两部分,如上图
mainReactor负责监听server socket,用来处理网络新连接的建立,将建立的socketChannel指定注册给subReactor,通常一个线程就可以处理;
subReactor维护自己的Demultiplexer, 基于mainReactor注册的Event Handler多路分离I/O读写事件;
对非I/O的操作,依然转交给线程池(Thread Pool)执行。
此种模型中,每个模块的工作更加专一,耦合度更低,性能和稳定性也大量的提升,支持的可并发客户端数量可达到上百万级别。关于此种模型的应用,目前有很多优秀的框架已经在应用了,比如mina、Nginx、Memcached和Netty等。
1.2.5 总结
3种模式可以用个比喻来理解:餐厅常常雇佣接待员负责迎接顾客,当顾客入坐后,侍应生专门为这张桌子服务。
单Reactor单线程:接待员和侍应生是同一个人,全程为顾客服务。
单Reactor多线程:1 个接待员,多个侍应生,接待员只负责接待。
主从Reactor多线程:多个接待员,多个侍应生。
1.3 Reactor模型的优劣
- 优点:
- Reactor实现相对简单,对于链接多,但耗时短的处理场景高效;
- 操作系统可以在多个事件源上等待,并且避免了线程切换的性能开销和编程复杂性;
- 事件的串行化对应用是透明的,可以顺序的同步执行而不需要加锁;
- 事务分离:将与应用无关的多路复用、分配机制和与应用相关的回调函数分离开来。
- 缺点:
- Reactor处理耗时长的操作会造成事件分发的阻塞,影响到后续事件的处理;
1.4 Reactor模型的应用
1.4.1 Reactor模型在Java NIO中
我们知道,Java NIO的网络编程中,会有一个死循环执行Selector.select()操作,找出注册到Selector上的Channel中已经准备好的IO事件,然后再对这些事件进行处理。
故而NIO中的Selector组件对应的就是Reactor模式的Synchronous Event Demultiplexer同步事件多路分解器。
选择过后得到的SelectionKey,其实就对应的是上面的handle,也就是代表的一个个的IO事件。而NIO中并没有进行事件分发和封装处理器,因此Reactor模式中的其他组件NIO并没有给出实现。
1.4.2 Reactor模式在Netty中
上面java NIO实现了reactor模式的两个角色,Demultiplexer和handle。
而剩余的三个角色,则由Netty给出了实现。
学习过Netty的应当知道,Netty服务端的编程有一个bossGroup和一个workerGroup,还需要编写自己的ChannelHandler。
bossGroup和workerGroup都是一个事件循环组(EventLoopGroup,一般我们用的是NIOEventLoopGroup),每个事件循环组有多个事件循环(EventLoop,NIO对应的是NIOEventLoop)。
mainReactor对应Netty中配置的BossGroup线程组,主要负责接受客户端连接的建立。一般只暴露一个服务端口,BossGroup线程组一般一个线程工作即可。
subReactor对应Netty中配置的WorkerGroup线程组,BossGroup线程组接受并建立完客户端的连接后,将网络socket转交给WorkerGroup线程组,然后在WorkerGroup线程组内选择一个线程,进行I/O的处理。WorkerGroup线程组主要处理I/O,一般设置2*CPU核数个线程。
bossGroup/workerGroup中的事件循环EventLoop就充当了Dispatcher的角色。
Netty中我们需要实现的Handler的顶层接口ChannelHandler对应的就是Event Handler角色,而我们添加进去的一个个的Handler对应的就是Concrete Event Handler。
注意,Netty的Handler是Concrete Event Handler的角色,Netty的SelectionKey才是handle的角色。
最后我们总结一下Netty和Reactor角色的对应关系:
- Initiation Dispatcher ———— NioEventLoop
- Synchronous Event Demultiplexer ———— Selector
- Handle———— SelectionKey
- Event Handler ———— ChannelHandler
- ConcreteEventHandler ———— 具体的ChannelHandler的实现
- mainReactor ———— bossGroup(NioEventLoopGroup)线程组
- subReactor ———— workerGroup(NioEventLoopGroup)线程组
- acceptor ———— ServerBootstrapAcceptor
- ThreadPool ———— 用户自定义线程池或者EventLoopGroup
2 Proactor事件处理模型
Reactor模式是非阻塞同步的I/O模型,Proactor模式是非阻塞异步I/O模型。它们的区别就在于异步二字,Proactor能实现真正的异步,但真正的异步IO也需要操作系统更强的支持。
在Reactor模型中,事件循环利用select等函数,主动地将已经就绪的handle找出,并通过回调通知给用户线程,由用户线程定义的回调函数自行读取数据、处理数据。换句话说,用户线程定义的回调函数中,要自行操作write(),将IO数据从内核空间写到用户空间。
而在Proactor模型中,就不是利用select等函数寻找就绪的handle了,要记得Proactor是异步IO模型,异步是什么?我们不用主动调用select函数去寻找,而是直接等通知就行了。
并通过回调通知给用户线程,但当用户线程收到通知时,数据已经被内核读取完毕,并放在了用户线程指定的缓冲区内,内核在IO完成后通知用户线程直接使用即可。也就是说,此时用户线程定义的回调函数中,不需要自行操作write(),因为IO数据已经从内核空间写到用户空间了。
Reactor中,write()操作还是同步的,由用户线程自己解决,而Proactor中,真正做到了异步write(),它依赖于内部实现的异步操作处理器(Asynchronous Operation Processor)以及异步事件分离器(Asynchronous Event Demultiplexer)将IO操作与应用回调隔离。
相比于Reactor,Proactor并不十分常用,不少高性能并发服务程序使用IO多路复用模型+多线程任务处理的架构基本可以满足需求。况且目前操作系统对异步IO的支持并非特别完善,更多的是采用Reactor模型模拟Proactor异步IO的方式:IO事件触发时不直接通知用户线程,而是非阻塞地将数据读写完毕后放到用户指定的缓冲区中,再执行回调逻辑
Java7之后已经支持了异步IO,感兴趣的读者可以尝试使用。
2.1 Proactor模型的架构
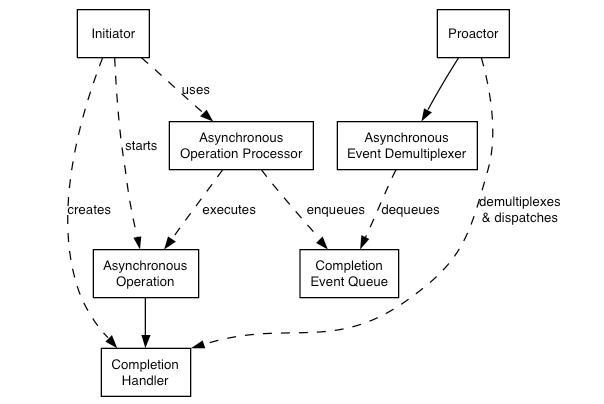
模型架构如上图所示,我们来一一解释这些控件:
其中Handle的含义,跟Reactor模型一致,Event Handler和Completion Handler也类似,它们都是事件的抽象封装。
Handle:句柄,用来封装或标识socket连接或是打开文件,你可以理解为在模型中,它代表一个连接或者I/O流文件。
Completion Handler:完成事件接口,用来绑定某个handle和应用程序所提供的特定事件处理逻辑。Concrete Completion Handler是它的具体实现类,应用程序可针对不同的连接(handle)定制不同的回调函数(event)。
Completion Event Queue:完成事件的队列;异步操作完成的结果放到队列中等待后续使用。
Asynchronous Operation Processor:异步操作处理器;负责执行异步操作,一般由操作系统内核实现;绑定在Handle上,负责对监听到的Handle事件进行回调唤醒对应的异步操作,生成对应的Completion Event并添加到完成事件的队列中。
Asynchronous Operation:异步操作,主要用于处理程序中长时间持续操作;
Asynchronous Event Demultiplexer:异步事件多路分解器,和Reactor的Demultiplexer作用类似,但因为Proactor是异步的,故而不需要Demultiplexer主动发起select轮询,只要监视着完成事件的队列,看是否有Completion Handler被异步插入到队列中即可。
Proactor:Proactor模型的主动器,提供应用程序的事件循环,重复地从Demultiplexer中获得就绪的Completion Handler,并调用其handle_event()方法。
Initiator:本地应用程序服务入口,初始化一个异步操作并注册一个Completion Handler和一个带有异步操作处理器的Proactor,当操作完成时通知它。
可以看到,Proactor角色的作用和Reactor的Dispatcher作用一致。它其实就是Proactor模型的Dispatcher,只不过叫法不一样罢了。
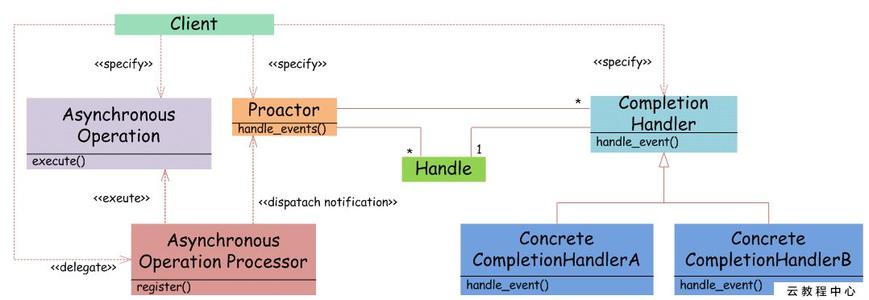
也有部分文章将Dispatcher+Demultiplexer合并在Proactor角色里,就像Reactor模型中有时用Reactor表示Dispatcher+Demultiplexer,如下图:
2.2 Proactor模型的流程
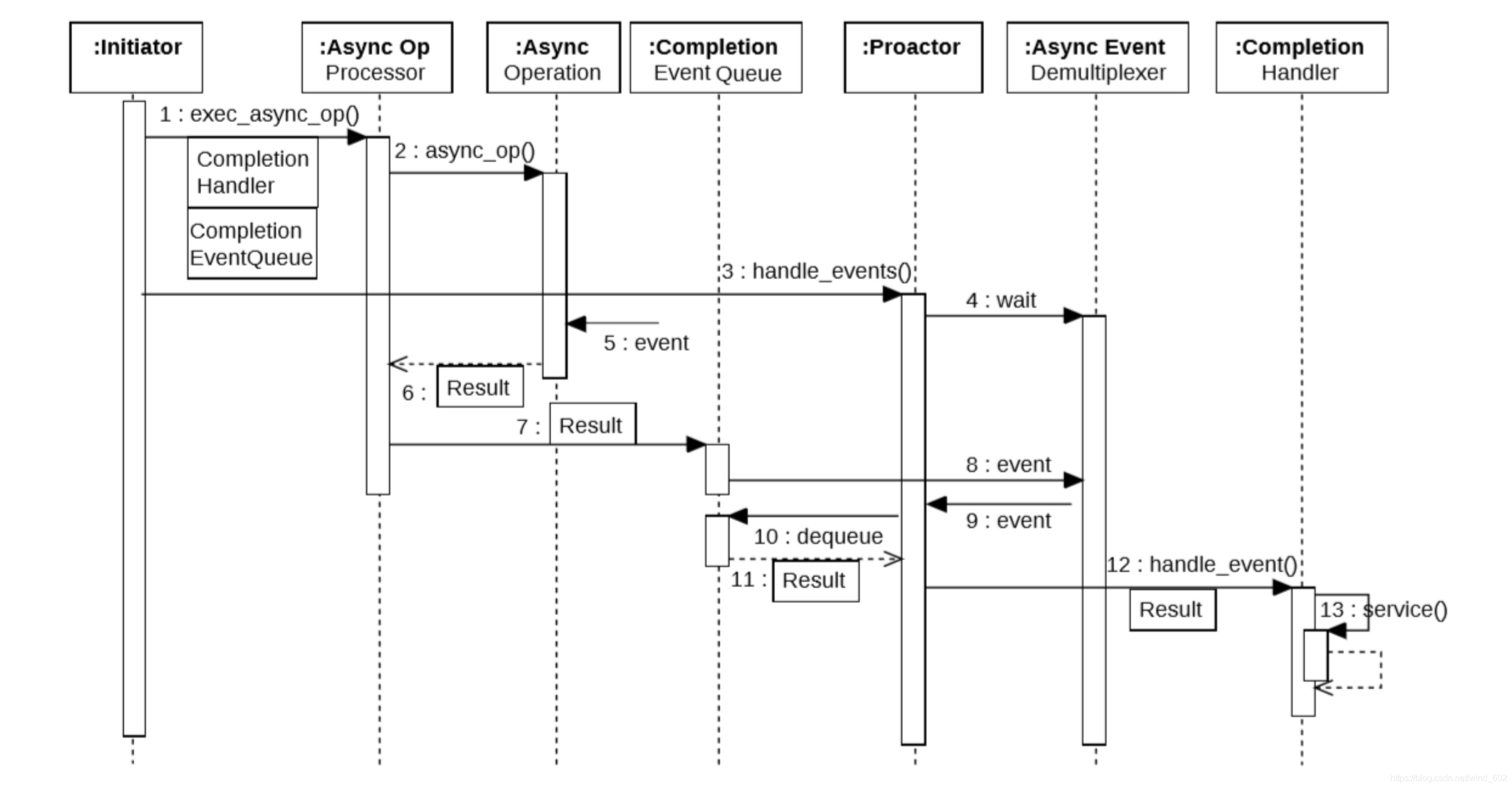
由图可以看到,Proactor模型的流程可以被归纳为:
Initiator创建Proactor,Completion Event Queue和Completion Handler对象,并将其通过Asynchronous Operation Processor的exec_async_op()方法注册到内核,并调用async_op()方法,开启独立的内核线程执行异步操作,实现真正的异步。
调用之后应用程序和异步操作处理就独立运行;应用程序可以调用新的异步操作,而其它操作可以并发进行;
Initiator调用Proactor.handle_events()方法,启动Proactor主动器,进行无限的事件循环,调用Demultiplexer.wait()方法,等待完成事件到来;
异步事件的就绪被Asynchronous Operation Processor监听到,将其对应的Completion Handler加入Completion Event Queue队列。
Demultiplexer监视着Completion Event Queue队列,发现有数据,便将队列中的Completion Handler返回。
Proactor从Demultiplexer得到就绪的Completion Handler,知道事件已经就绪,随即调用Completion Handler.handle_event()方法。
虽然Proactor模式中每个异步操作都可以绑定一个Proactor对象(类似多Reactor的实现方式),但是一般在操作系统中,Proactor被实现为Singleton模式,以便于集中化分发操作完成事件。
2.3 Proactor模型的优劣
- 优点:
- Proactor在理论上性能更高,能够处理耗时长的并发场景。
- 缺点:
- Proactor实现逻辑复杂;依赖操作系统对异步的支持,目前实现了纯异步操作的操作系统少,实现优秀的如windows IOCP,但由于其windows系统用于服务器的局限性,目前应用范围较小;而Unix/Linux系统对纯异步的支持有限,应用事件驱动的主流还是通过select/epoll来实现。
2.4 Proactor模型的应用
Proactor因为要有操作系统的支持,故而应用的场景并不多,Linux下高性能的网络库中大多使用的Reactor 模式去实现。比如Boost Asio在Linux下用epoll和select去模拟proactor模式。
除此之外,glibc实现的POSIX aio也是采用proactor模式
3 Reactor和Proactor的对比
3.1 区别
同步和异步
- Reactor无法实现真正的异步,他们所有操作都是同步的,所以有时为了性能考虑,需要借助线程池,将同步的操作并发化。
- Proactor基于操作系统的支持,可以实现真正的异步。
主动/被动的写操作
- Reactor将handler放到select(),等待可写就绪,事件就绪后,需要应用程序主动调用write(),将数据从内核空间写入到用户空间,写完数据后再处理后续逻辑;
- Proactor调用aoi_write后立刻返回,由内核负责将数据从内核空间写入到用户空间,写完后调用相应的回调函数处理后续逻辑。换句话说,Proactor通知应用线程的时候,数据已经在用户空间就绪了。
主动/被动的处理方式
- Reactor模式被称为反应器,是一种被动的处理,即调用IO多路复用接口来做事件监听(注意此时是在用户空间调用select等函数),select等函数监听事件就是一个等待的过程,有事件来了之后再“做出反应”。
- 而Proator模式的IO是系统级实现,是在内核中完成,读的过程中,用户空间的函数可以继续处理,并没有被阻塞;读完之后调用相应用户回调函数处理;
3.2 实现
Reactor实现了一个被动的事件分离和分发模型,服务等待请求事件的到来,再通过不受间断的同步处理事件,从而做出反应;
Proactor实现了一个主动的事件分离和分发模型;这种设计允许多个任务并发的执行,从而提高吞吐量。
所以涉及到文件I/O或耗时I/O可以使用Proactor模式,或使用多线程模拟实现异步I/O的方式。
3.3 适用场景
Reactor:同时接收多个服务请求,并且依次同步的处理它们的事件驱动程序;
Proactor:异步接收和同时处理多个服务请求的事件驱动程序。
【I/O设计总结一】五种I/O模型总结
前言
在了解IO设计之前,我们首先的搞明白几个概念:什么是阻塞和非阻塞,什么是同步和异步;
同步和异步是针对应用程序和内核的交互而言的;
- 同步指的是应用程序触发IO操作并等待或者轮询的去查看IO操作是否就绪,也就是需要应用程序自己主动去查看。
- 异步是指应用程序触发IO操作以后便开始做自己的事情,而当IO操作已经完成的时候会得到IO完成的通知,或者调用应用程序注册的回调函数。也就是说应用程序可以等着被通知。
阻塞和非阻塞描述的是用户线程调用内核IO操作的方式;
- 阻塞方式下,应用程序调用读取或者写入函数后将一直阻塞等待着,IO操作需要彻底完成后,才会返回到用户空间。
- 非阻塞方式下,应用程序调用读取或者写入函数后内核,会立即返回给应用程序一个状态值,表示数据是否准备好,而不是一直将应用程序阻塞着,直到IO操作彻底完成。
Unix的一个输入操作一般有两个不同的阶段:
1、等待数据准备好。
2、从内核到进程拷贝数据。
对于一个套接口上的输入操作,第一步一般是等待数据到达网络,当分组到达时,它被拷贝到内核中的某个缓冲区,第二步是将数据从内核缓冲区拷贝到应用缓冲区。
于是,同步/非同步,阻塞/非阻塞这两个维度的排列组合,便构成了我们今天常见的I/O设计模型:同步阻塞,同步非阻塞,异步阻塞,异步非阻塞IO
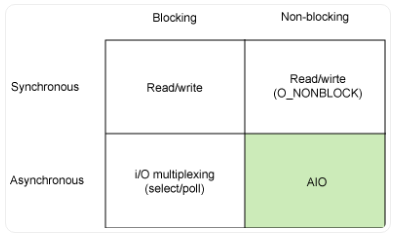
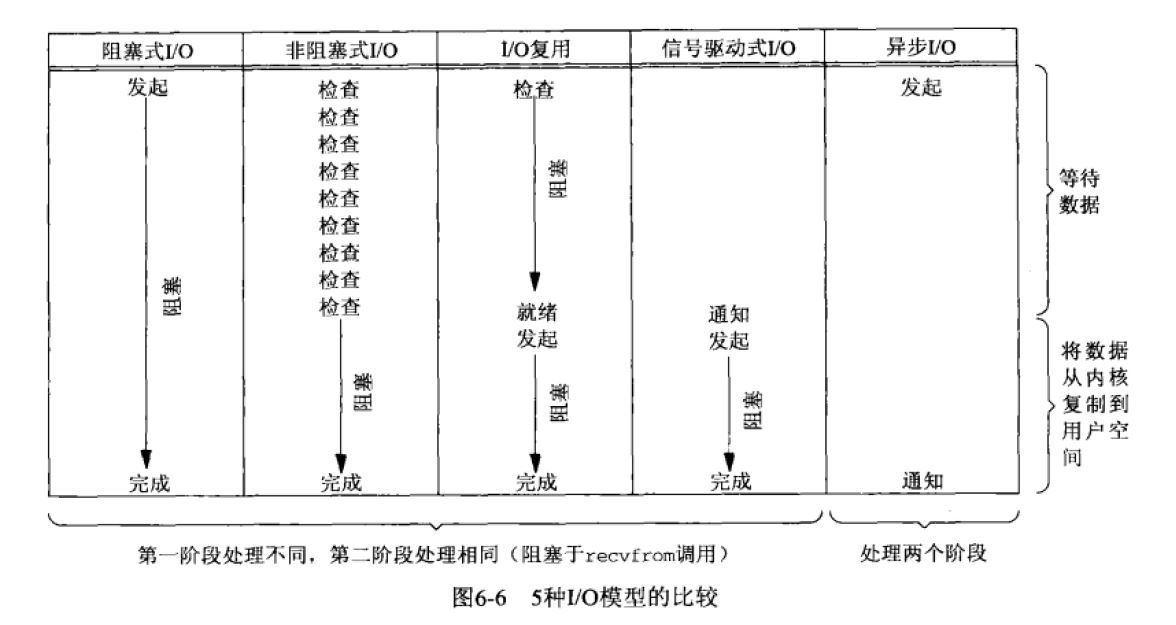
另外,Richard Stevens 在《Unix 网络编程》卷1中提到的基于信号驱动的IO(Signal Driven IO)模型,由于该模型并不常用,本文不作太多。
- 阻塞式I/O(BIO)
- 非阻塞式I/O(NIO)
- I/O多路复用模型(IO multiplexing,即select,poll和epoll)
- 信号驱动I/O(SIGIO)
- 异步I/O(Posix.1的aio_系列函数)
1 阻塞式I/O模型(BIO)
在此种方式下,用户进程在发起一个IO操作以后,必须等待IO操作的完成,只有当真正完成了IO操作以后,用户进程才能运行。JAVA传统的IO模型属于此种方式!
应用程序调用一个IO函数,导致应用程序阻塞,如果数据已经准备好,则从内核拷贝到用户空间,否则一直等待下去。
在linux中,默认情况下所有的socket都是blocking,一个典型的读操作流程大概是这样:
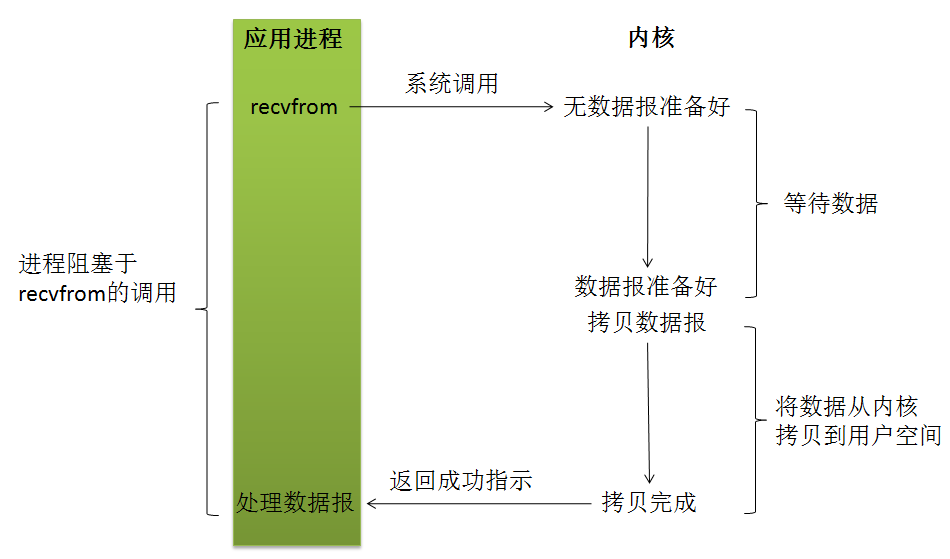
当用户进程调用了recvfrom这个系统函数,kernel就开始了IO的第一个阶段:准备数据(对于网络IO来说,很多时候数据在一开始还没有到达。比如,还没有收到一个完整的UDP包。这个时候kernel就要等待足够的数据到来)。这个过程需要等待,也就是说数据被拷贝到操作系统内核的缓冲区中是需要一个过程的。
而在用户进程这边,整个进程会被阻塞(当然,是进程自己选择的阻塞)。当kernel一直等到数据准备好了,它就会将数据从kernel中拷贝到用户内存,然后kernel返回结果,用户进程才解除block的状态,重新运行起来。
2 非阻塞式I/O模型(nonblocking IO)
我们把一个套接口设置为非阻塞就是告诉内核,当所请求的I/O操作无法完成时,不要将进程睡眠,而是返回一个错误。
这样我们的I/O操作函数将不断的轮询数据是否已经准备好,如果没有准备好,继续询问,直到数据准备好为止。在这个不断轮询的过程中,会大量的占用CPU的时间。
非阻塞式IO虽然不会让进程阻塞,可以在数据未完备的时候让进程返回,但应用进程会连续不断地查询内核,看看某操作是否准备好,这对CPU时间是极大的浪费,其中目前JAVA的NIO就属于同步非阻塞IO。
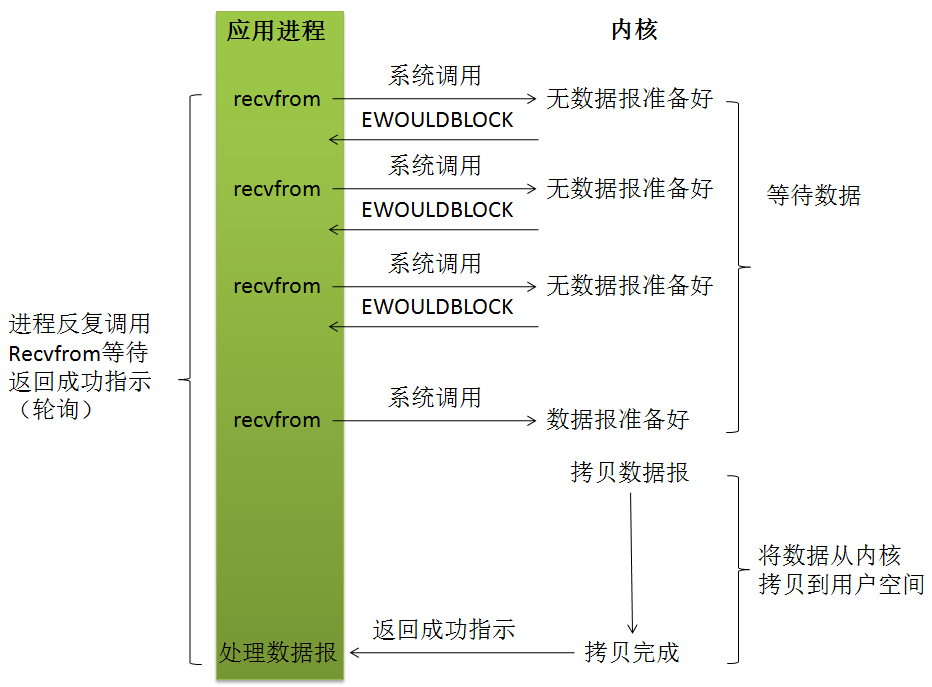
当用户进程发出read操作时,如果kernel中的数据还没有准备好,那么它并不会阻塞用户进程,而是立刻返回一个error。
从用户进程角度讲 ,它发起一个read操作后,并不需要等待,而是马上就得到了一个结果。用户进程判断结果是一个error时,它就知道数据还没有准备好,于是它可以再次发送read操作。
一旦kernel中的数据准备好了,并且又再次收到了用户进程的system call,那么它马上就将数据拷贝到了用户内存,然后返回。
3 I/O多路复用模型
设想一下,我们想要得到高性能的IO模型,在阻塞I/O模式下,虽然不会占用大量的CPU时间,一个线程只能处理一个流的I/O事件。如果想要同时处理多个流,要么多进程(fork),要么多线程(pthread_create),很不幸这两种方法效率都不高。
那么我们再考虑一下非阻塞忙轮询的I/O方式,我们发现我们似乎可以利用非阻塞式I/O来达到处理多个流的目的。我们只要不停的让每个流从头到尾轮流去向内核问一遍,一直循环周而复始。这样就可以处理多个流了。
但这样的做法有个问题:如果所有的流都没有数据,那么只会白白浪费CPU。
为了避免CPU空转,可以引进了一个非阻塞式的代理(一开始有一位叫做select的代理,后来又有一位叫做poll的代理,不过两者的本质是一样的)。这个代理比较厉害,可以同时观察许多流的I/O事件,在空闲的时候,select/poll会把应用线程阻塞掉,然后自己会不断的非阻塞式的轮训注册的流,当有一个或多个流有I/O事件时,select/poll就会返回,应用线程就会从阻塞态中醒来,于是我们的程序就会知道有I/O事件完备了,至于是哪个流完备了,还要应用程序轮询一遍所有的流。
然而,如果没有I/O事件产生,我们的程序就会阻塞在select或者poll处,这依然有个问题,我们从select那里仅仅知道了有I/O事件发生了,但却并不知道是哪几个流(可能有一个,多个,甚至全部),我们只能无差别轮询所有流,找出能读出数据,或者写入数据的流,再对他们进行操作。
即如果用select/poll,我们有O(n)的无差别轮询的时间复杂度,同时处理的流越多,每一次无差别轮询时间就越长。
为了解决这个问题,我们引入了epoll代理,epoll可以理解为event poll,不同于无差别轮询,epoll只会把哪个流发生了怎样的I/O事件通知我们。
IO multiplexing就是我们说的select,poll,epoll。IO多路复用的好处就在于单个process就可以同时处理多个网络连接的IO。它的基本原理就是select,poll,epoll这个function会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程。
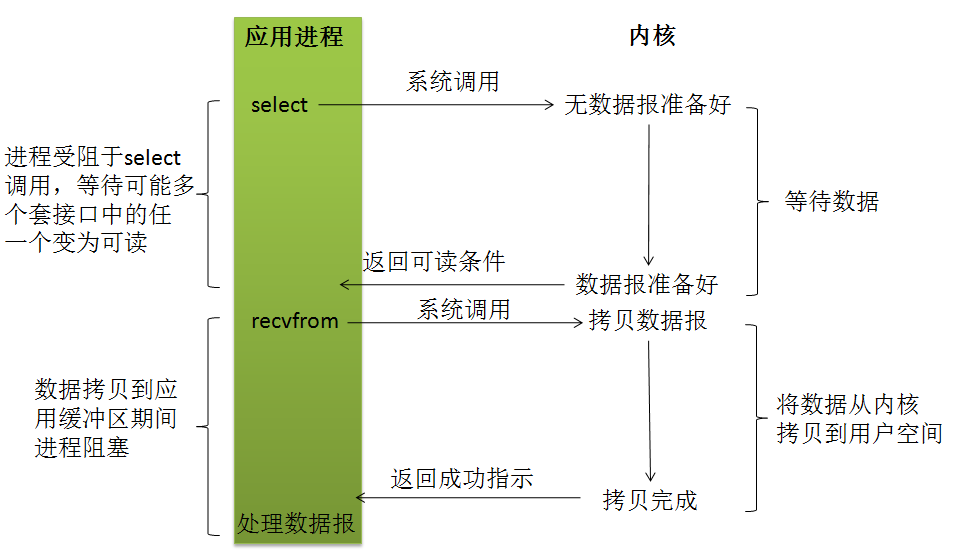
从流程上来看,使用select函数进行IO请求和同步阻塞模型没有太大的区别,甚至还多了添加监视socket,以及调用select函数的额外操作,效率更差。实际上select/epoll的优势并不是对于单个连接能处理得更快。
使用select以后最大的优势是用户可以在一个线程内同时处理多个socket的IO请求。用户可以注册多个socket,然后不断地调用select读取被激活的socket,即可达到在同一个线程内同时处理多个IO请求的目的。而在同步阻塞模型中,必须通过多线程的方式才能达到这个目的。
IO多路复用的详细内容,可见本站博客《【I/O设计总结二】详解IO多路复用和其三种模式——select/poll/epoll》
IO多路复用是最常使用的IO模型,但是其异步程度还不够“彻底”,因为应用进程调用select/poll函数的时候,还是会被阻塞。因此IO多路复用只能称为异步阻塞IO,而非真正的异步IO。
不过Reactor设计模式优化了select/poll的阻塞性,使得IO多路复用模型变成真正的异步IO。Reactor设计模式将在《【I/O设计总结三】详解Reactor/Proactor高性能IO处理模式》中介绍。
4 信号驱动I/O模型
我们也可以用信号,让内核在描述符就绪时发送SIGIO信号通知我们。通过sigaction系统调用安装一个信号处理函数。该系统调用将立即返回,我们的进程继续工作,也就是说它没有被阻塞。
当数据报准备好读取时,内核就为该进程产生一个SIGIO信号。我们随后既可以在信号处理函数中调用recvfrom读取数据报,并通知应用进程数据已经准备好待处理。
优势:等待数据报到达期间进程不被阻塞。应用进程可以继续执行,只要等待来自信号处理函数的通知:既可以是数据已准备好被处理,也可以是数据报已准备好被读取。

5 异步I/O模型(asynchronous IO)
linux下的asynchronous IO其实用得很少。“真正”的异步IO需要操作系统更强的支持。在IO多路复用模型中,事件循环将文件句柄的状态事件通知给用户线程,由用户线程自行读取数据、处理数据。而在异步IO模型中,当用户线程收到通知时,数据已经被内核读取完毕,并放在了用户线程指定的缓冲区内,内核在IO完成后通知用户线程直接使用即可。
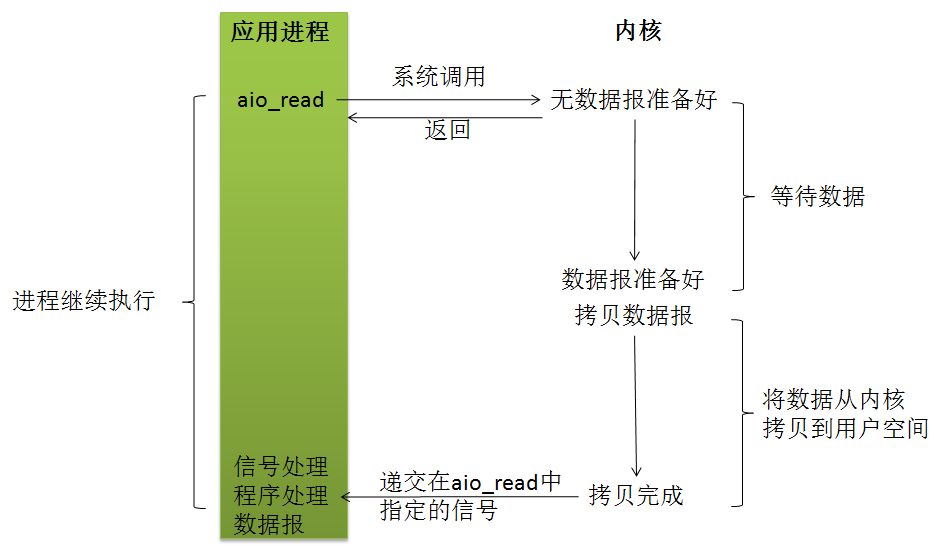
异步IO模型使用了Proactor设计模式实现了上述的这一机制。Proactor设计模式将在《【I/O设计总结三】详解Reactor/Proactor高性能IO处理模式》中介绍。
6 总结
下面一图总结上述五种I/O模型: