序言
我们知道,线程池帮我们重复管理线程,避免创建大量的线程增加开销。
合理的使用线程池能够带来3个很明显的好处:
- 降低资源消耗:通过重用已经创建的线程来降低线程创建和销毁的消耗
- 提高响应速度:任务到达时不需要等待线程创建就可以立即执行。
- 提高线程的可管理性:线程池可以统一管理、分配、调优和监控。
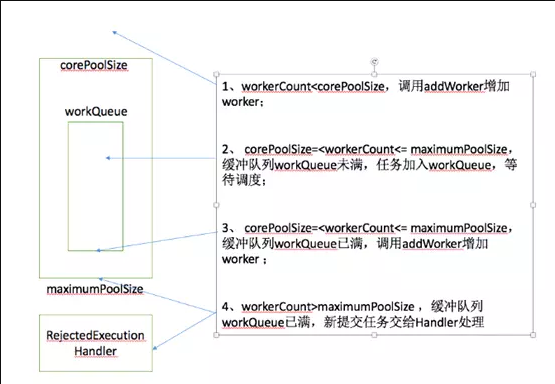
java源生的线程池,实现于ThreadPoolExecutor类,这也是我们今天讨论的重点1. ThreadPoolExecutor类构造方法
Jdk使用ThreadPoolExecutor类来创建线程池,我们来看看它的构造方法。
1 | /** |
int corePoolSize, //核心线程的数量
int maximumPoolSize, //最大线程数量
long keepAliveTime, //超出核心线程数量以外的线程空闲时,线程存活的时间
TimeUnit unit, //存活时间的单位,有如下几种选择
1
2
3
4
5
6
7TimeUnit.DAYS; //天
TimeUnit.HOURS; //小时
TimeUnit.MINUTES; //分钟
TimeUnit.SECONDS; //秒
TimeUnit.MILLISECONDS; //毫秒
TimeUnit.MICROSECONDS; //微妙
TimeUnit.NANOSECONDS; //纳秒BlockingQueue
workQueue, //保存待执行任务的队列,常见的也有如下几种: 1
2
3
4
5ArrayBlockingQueue;
LinkedBlockingQueue;
SynchronousQueue;
PriorityBlockingQueue
...
ThreadFactory threadFactory, //创建新线程使用的工厂
RejectedExecutionHandler handler // 当任务无法执行时的处理器(线程拒绝策略)
2. 核心类变量
2.1 ctl变量
ThreadPoolExecutor中有一个控制状态的属性叫ctl,它是一个AtomicInteger类型的变量,它一个int值可以储存两个概念的信息:
workerCount:表明当前池中有效的线程数,通过workerCountOf方法获得,workerCount上限是(2^29)-1。(最后存放在ctl的低29bit)
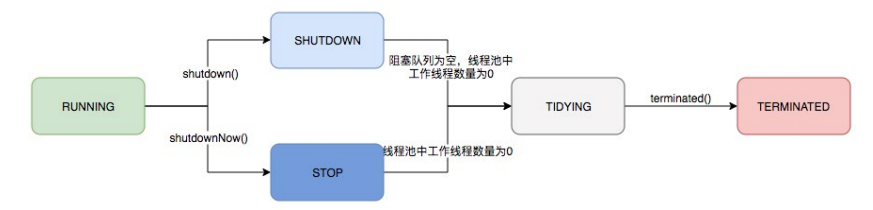
runState:表明当前线程池的状态,通过workerCountOf方法获得,最后存放在ctl的高3bit中,他们是整个线程池的运行生命周期,有如下取值,分别的含义是:
- RUNNING:可以新加线程,同时可以处理queue中的线程。线程池的初始化状态是RUNNING。换句话说,线程池被一旦被创建,就处于RUNNING状态,
- SHUTDOWN:不增加新线程,但是可以处理queue中的线程。调用线程池的shutdown()方法时,线程池由RUNNING -> SHUTDOWN。
- STOP 不增加新线程,同时不处理queue中的线程,会中断正在处理任务的线程。调用线程池的shutdownNow()接口时,线程池由(RUNNING or SHUTDOWN ) -> STOP。
- TIDYING 当所有的任务已终止,ctl记录的”任务数量”为0,阻塞队列为空,线程池会变为TIDYING状态。当线程池变为TIDYING状态时,会执行钩子函数terminated()。terminated()在ThreadPoolExecutor类中是空的,若用户想在线程池变为TIDYING时,进行相应的处理;可以通过重载terminated()函数来实现。
- TERMINATED 线程池彻底终止,就变成TERMINATED状态。线程池处在TIDYING状态时,执行完terminated()之后,就会由 TIDYING -> TERMINATED。
1 | private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0)); |
COUNT_BITS=32(integer的size)-3=29,于是五种状态左移29位分别是:
- RUNNING: 11100000000000000000000000000000
- SHUTDOWN: 00000000000000000000000000000000
- STOP: 00100000000000000000000000000000
- TIDYING: 01000000000000000000000000000000
- TERMINATED:01100000000000000000000000000000
而ThreadPoolExecutor是通过runStateOf和workerCountOf获得者两个概念的值的。
用一个变量去存储两个值,可避免在做相关决策时,出现不一致的情况,不必为了维护两者的一致,而占用锁资源。
runStateOf和workerCountOf方法是如何剥离出ctl变量的两个有效值呢?这其中我们可以看到CAPACITY是实现一个字段存两个值的最重要的字段。
2.2 CAPACITY变量
CAPACITY=(1 << COUNT_BITS) – 1 转成二进制为:000 11111111111111111111111111111,他是线程池理论上可以允许的最大的线程数。
所以很明显,它的重点在于,其高3bit为0,低29bit为1;
这样,workderCountOf方法中,CAPACITY和ctl进行&运算时,它能获得高3位都是0,低29位和ctl低29位相同的值,这个值就是workerCount;
同理,runStateOf方法,CAPACITY的取反和ctl进行&操作,获得高3位和ctl高三位相等,低29位都为0的值,这个值就是runState;
2.3 workQueue
1 | /** |
一个BlockingQueue
2.4 workers
1 | /** |
一个HashSet
2.5 mainLock
1 | private final ReentrantLock mainLock = new ReentrantLock(); |
mainLock是线程池的主锁,是可重入锁,当要操作workers set这个保持线程的HashSet时,需要先获取mainLock,还有当要处理largestPoolSize、completedTaskCount这类统计数据时需要先获取mainLock
2.6 其他重要属性
1 | private int largestPoolSize; //用来记录线程池中曾经出现过的最大线程数 |
3 核心内部类
3.1 Worker
Worker类是线程池中具化一个线程的对象,线程池为了掌握线程的状态并维护线程的生命周期,设计了线程池内的工作线程Worker。我们来看看源码:
1 | /** |
Worker这个工作线程实现了Runnable接口,并持有一个线程thread,一个初始化的任务firstTask。thread是在调用构造方法时通过ThreadFactory来创建的线程,可以用来执行任务;
firstTask用来保存传入的第一个任务,这个任务可以有也可以为null。如果这个值是非空的,那么线程就会在启动初期立即执行这个任务,也就对应核心线程创建时的情况;如果这个值是null,那么就需要创建一个线程去执行任务列表(workQueue)中的任务,也就是非核心线程的创建。
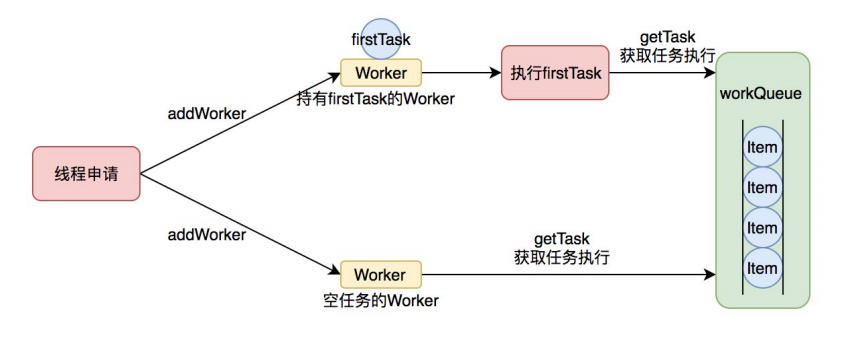
之所以要将thread和firstTask封装成一个Worker,是因为线程池需要利用Worker来实现工作线程的加锁,以及控制中断。
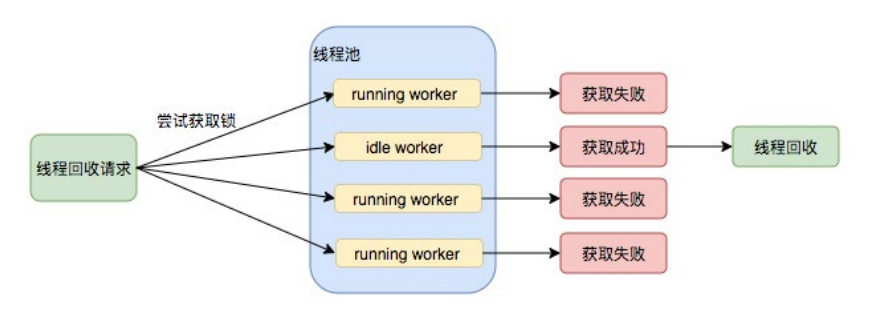
Worker是通过继承AQS,使用AQS来实现独占锁这个功能。没有使用可重入锁ReentrantLock,而是使用AQS,为的就是实现不可重入的特性去反应线程现在的执行状态。
- lock方法一旦获取了独占锁,表示当前线程正在执行任务中。
- 如果正在执行任务,则不应该中断线程。
- 如果该线程现在不是独占锁的状态,也就是空闲的状态,说明它没有在处理任务,这时可以对该线程进行中断。
- 线程池在执行shutdown方法或tryTerminate方法时会调用interruptIdleWorkers方法来中断空闲的线程,interruptIdleWorkers方法会使用tryLock方法来判断线程池中的线程是否是空闲状态;如果线程是空闲状态则可以安全回收。
4 核心方法
好了,基本上我们将线程池的几个主角,ctl,workQueue,workers,Worker简单介绍了一遍,现在,我们来看看线程池是怎么玩的。
4.1 线程的运行
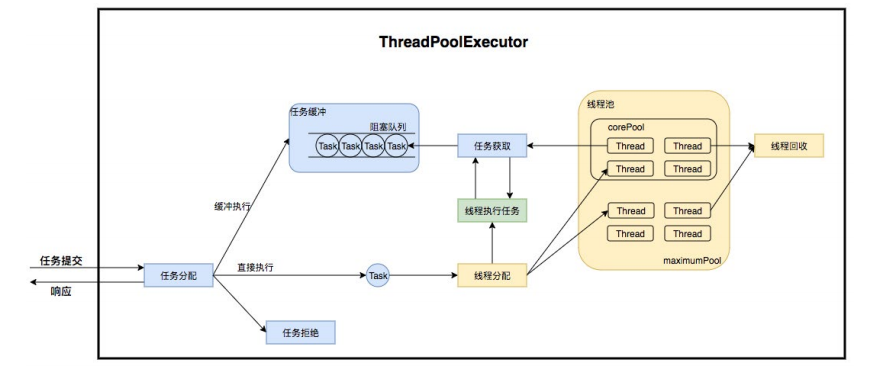
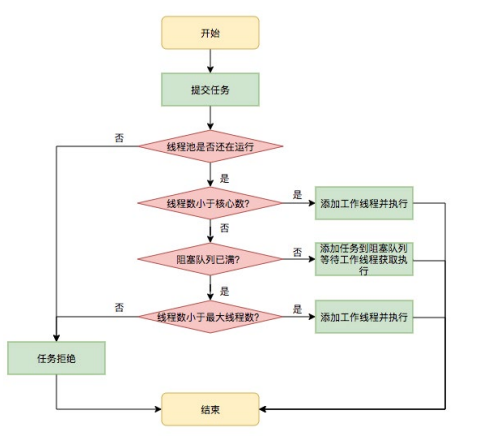
我们先来看一个简单的线程池的运行流程图:
4.1.1 execute方法
这是线程池实现类外露供给外部实现提交线程任务command的核心方法,对于无需了解线程池内部的使用者来说,这个方法就是把某个任务交给线程池,正常情况下,这个任务会在未来某个时刻被执行,实现和注释如下:
1 | /** |
1 | public void execute(Runnable command) { |
我们可以简单归纳如下: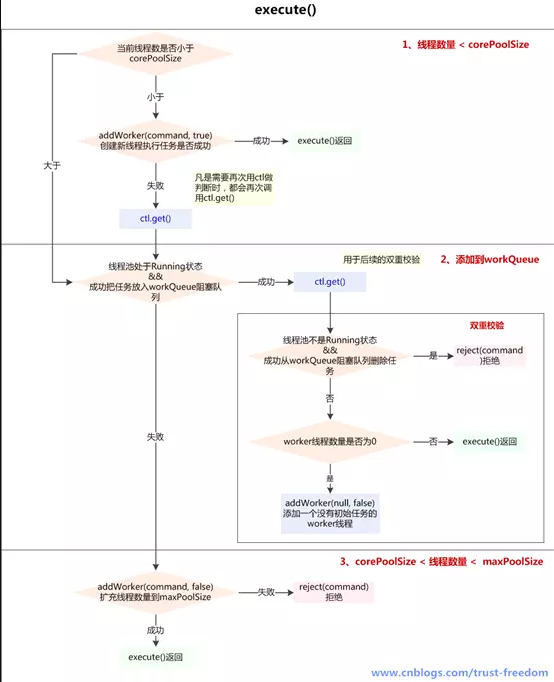
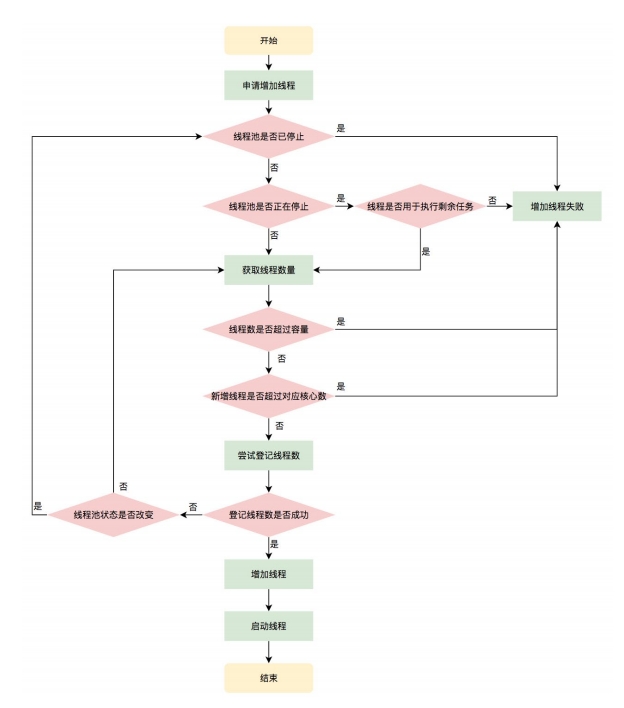
4.1.2 addWorker
在execute方法中,我们看到核心的逻辑是由addWorker方法来实现的,当我们将一个任务提交给线程池,线程池会如何处理,就是主要由这个方法加以规范:
该方法有两个参数:
- firstTask: worker线程的初始任务,可以为空
- core: true:将corePoolSize作为上限,false:将maximumPoolSize作为上限
排列组合,addWorker方法有4种传参的方式:
- addWorker(command, true)
- addWorker(command, false)
- addWorker(null, false)
- addWorker(null, true)
在execute方法中就使用了前3种,结合这个核心方法进行以下分析
- 第一个:线程数小于corePoolSize时,放一个需要处理的task进Workers Set。如果Workers Set长度超过corePoolSize,就返回false
- 第二个:当队列被放满时,就尝试将这个新来的task直接放入Workers Set,而此时Workers Set的长度限制是maximumPoolSize。如果线程池也满了的话就返回false
- 第三个:放入一个空的task进workers Set,长度限制是maximumPoolSize。这样一个task为空的worker在线程执行的时候会去任务队列里拿任务,这样就相当于创建了一个新的线程,只是没有马上分配任务
- 第四个:这个方法就是放一个空的task进Workers Set,而且是在小于corePoolSize时,如果此时Set中的数量已经达到corePoolSize那就返回false,什么也不干。实际使用中是在prestartAllCoreThreads()方法,这个方法用来为线程池预先启动corePoolSize个worker等待从workQueue中获取任务执行
1 | /** |
同样的,我们可以归纳一下: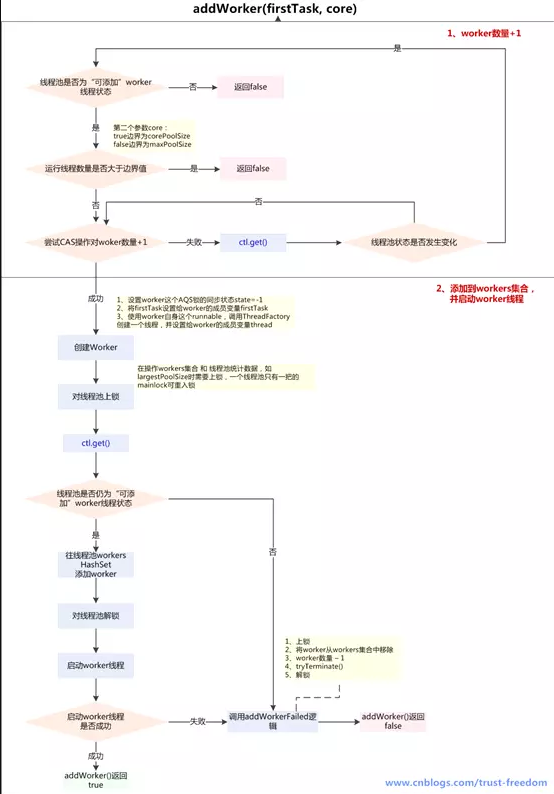
4.1.3 runWorker 方法
在addWorker方法中,我们将一个新增进去的worker所组合的线程属性thread启动了,但我们知道,在worker的构造方法中,它将自己本身注入到了thread的target属性里,所以绕了一圈,线程启动后,调用的还是worker的run方法,而在这里面,runWorker定义了线程执行的逻辑:
1 | /** |
1 | final void runWorker(Worker w) { |
我们归纳: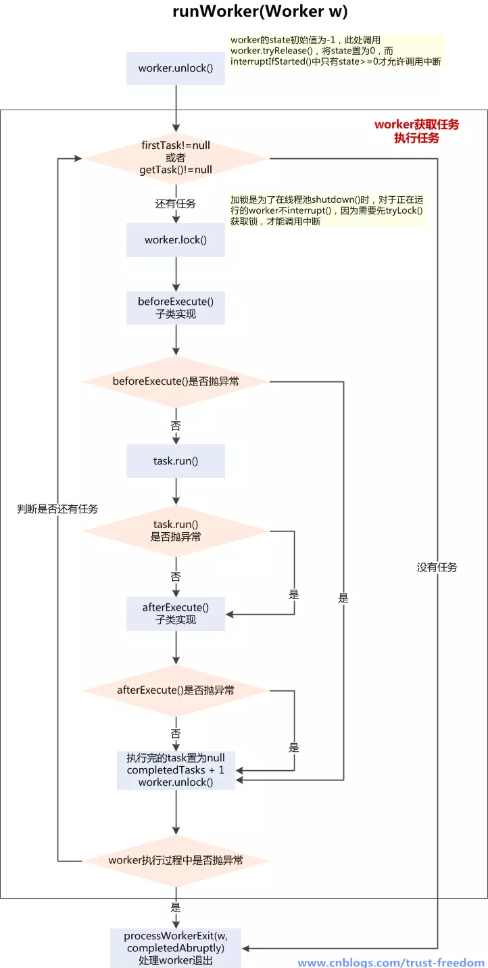

4.1.4 getTask方法
runWorker方法中的getTask()方法是线程处理完一个任务后,从队列中获取新任务的实现,也是处理判断一个线程是否应该被销毁的逻辑所在:
1 | /** |
归纳: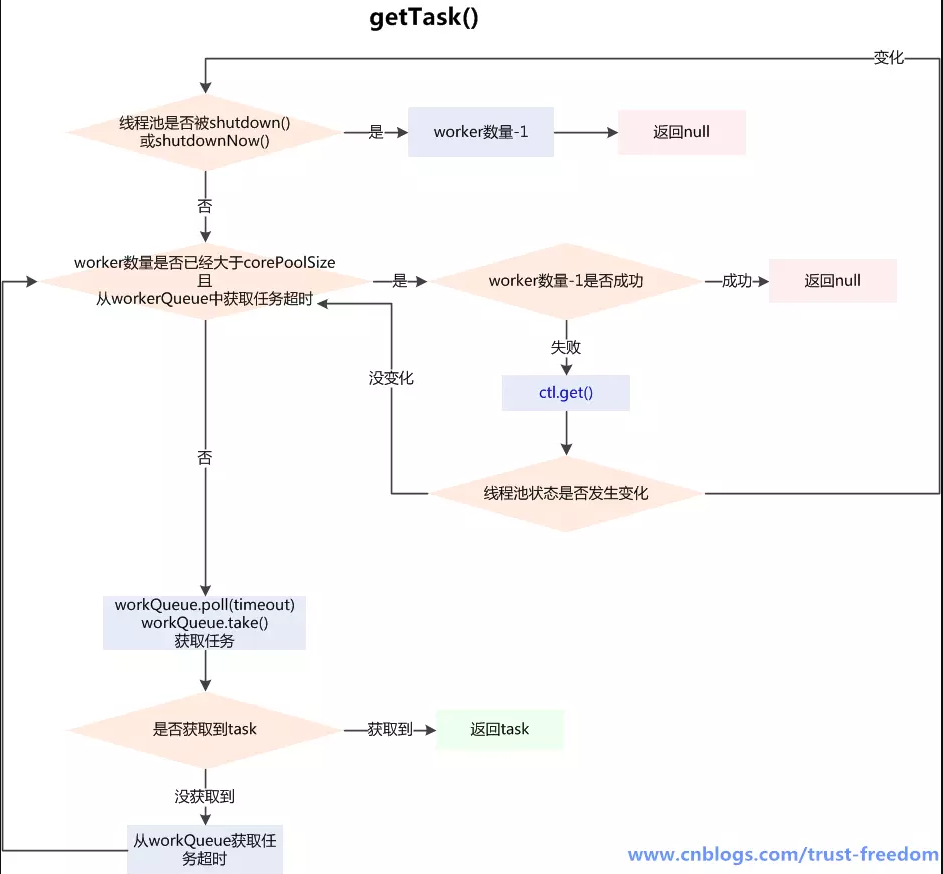
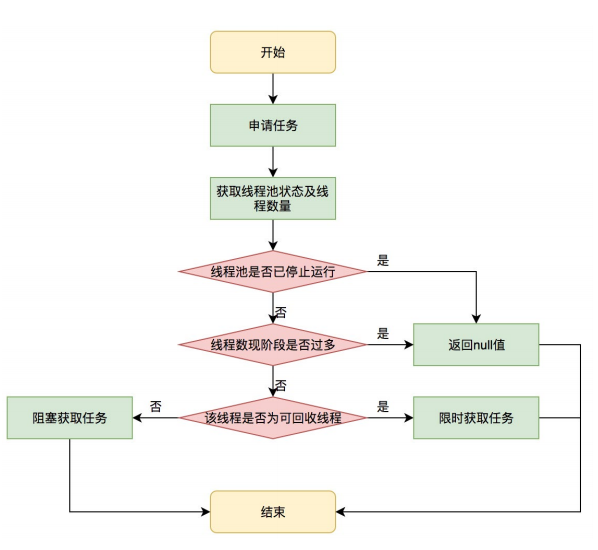
4.1.5 processWorkerExit方法
在runWorker方法中,我们看到当不满足while条件后,线程池会执行退出线程的操作,这个操作,就封装在processWorkerExit方法中。
1 | /** |
总而言之:如果线程池还没有完全终止,就仍需要保持一定数量的线程。
线程池状态是running 或 shutdown的情况下:
- 如果当前线程是突然终止的,addWorker()
- 如果当前线程不是突然终止的,但当前线程数量 < 要维护的线程数量,addWorker()
故如果调用线程池shutdown(),直到workQueue为空前,线程池都会维持corePoolSize个线程,然后再逐渐销毁这corePoolSize个线程。

4.1.6 submit方法
前面我们讲过execute方法,其作用是将一个任务提交给线程池,以期在未来的某个时间点被执行。
submit方法在作用上,和execute方法是一样的,将某个任务提交给线程池,让线程池调度线程去执行它。
那么它和execute方法有什么区别呢?我们来看看submit方法的源码:
submit方法的实现在ThreadPoolExecutor的父类AbstractExecutorService类中,有三种重载方法:
1 | /** |
源码很简单,submit方法,将任务task封装成FutureTask(newTaskFor方法中就是new了一个FutureTask),然后调用execute。所以submit方法和execute的所有区别,都在这FutureTask所带来的差异化实现上。
总而言之,submit方法将一个任务task用future模式封装成FutureTask对象,提交给线程执行,并将这个FutureTask对象返回,以供主线程在该任务被线程池执行之后得到执行结果。
注意,获得执行结果的方法FutureTask.get(),会阻塞执行该方法的线程,尤其是当任务被DiscardPolicy策略和DiscardOldestPolicy拒绝的时候,get方法会一直阻塞在那里,所以我们最好使用自带超时时间的future。
4.2 线程池的关闭
4.2.1 shutdown方法
讲完了线程池的基本运转过程,在方法章的最后,我们来看看负责线程池生命周期最后收尾工作的几个重要方法,首先是shutdown方法。
1 | /** |
我们可以看到,shutdown方法只不过是中断唤醒了所有阻塞的线程,并且把线程池状态置为shutdown,正如注释所说的,它没有等待所有正在执行任务的线程执行完任务,把状态置为shutdown,已经足够线程池丧失基本的功能了。
在该方法中,线程池如何中断线程是我们最需要关心的,我们来看一下interruptIdleWorkers方法:
1 | private void interruptIdleWorkers(boolean onlyOne) {//参数onlyOne表示是否只中断一个线程就退出,在shutdown中该值为false。 |
我们可以看到,在中断方法中,我们调用了worker的tryLock方法去尝试获取worker的锁,所以我们说,worker类这一层的封装,是用来控制线程中断的,正在执行任务的线程已经上了锁,无法被中断,只有在获取阻塞队列中的任务的线程(我们称为空闲线程)才会有被中断的可能。
之前我们看过getTask方法,在这个方法中, worker是不加锁的,所以可以被中断。我们为什么说“中断不代表线程立刻停止,它要继续处理到阻塞队列为空时才会被销毁”呢?具体逻辑,我们再来看一下getTask的源码,以及我们的注释(我们模拟中断发生时的场景):
1 | private Runnable getTask() { |
总结:正阻塞在getTask()获取任务的worker在被中断后,会抛出InterruptedException,不再阻塞获取任务。捕获中断异常后,将继续循环到getTask()最开始的判断线程池状态的逻辑,当线程池是shutdown状态,且workQueue.isEmpty时,return null,进行worker线程退出逻辑。
所以,这就是我们为什么说,shutdown方法不会立刻停止线程池,它的作用是阻止新的任务被添加进来(逻辑在addWorker方法的第一个if判断中,可以返回去看一下),并且继续处理完剩下的任务,然后tryTerminated,尝试关闭。
4.2.2 tryTerminate方法
1 | /** |
总结一下:tryTerminate被调用的时机主要有:
- shutdown方法时
- processWorkerExit方法销毁一个线程时
- addWorkerFailed方法添加线程失败或启动线程失败时
- remove方法,从阻塞队列中删掉一个任务时
4.2.3 shutdownNow方法
我们知道,shutdown后线程池将变成shutdown状态,此时不接收新任务,但会处理完正在运行的 和 在阻塞队列中等待处理的任务。
我们接下来要说的shutdownNow方法,作用是:shutdownNow后线程池将变成stop状态,此时不接收新任务,不再处理在阻塞队列中等待的任务,还会尝试中断正在处理中的工作线程。
代码如下:
1 | /** |
interruptWorkers 很简单,循环对所有worker调用 interruptIfStarted,其中会判断worker的AQS state是否大于0,即worker是否已经开始运作,再调用Thread.interrupt
需要注意的是,对于运行中的线程调用Thread.interrupt并不能保证线程被终止,task.run内部可能捕获了InterruptException,没有上抛,导致线程一直无法结束
4.2.4 awaitTermination方法
该方法的作用是等待线程池终止,参数是timeout:超时时间和unit: timeout超时时间的单位,返回结果:true:线程池终止,false:超过timeout指定时间
1 | // |
termination.awaitNanos() 是通过 LockSupport.parkNanos(this, nanosTimeout)实现的阻塞等待
阻塞等待过程中发生以下具体情况会解除阻塞(对上面3种情况的解释):
如果发生了 termination.signalAll()(内部实现是 LockSupport.unpark())会唤醒阻塞等待,且由于ThreadPoolExecutor只有在 tryTerminated()尝试终止线程池成功,将线程池更新为terminated状态后才会signalAll(),故awaitTermination()再次判断状态会return true退出
如果达到了超时时间 termination.awaitNanos() 也会返回,此时nano==0,再次循环判断return false,等待线程池终止失败
如果当前线程被 Thread.interrupt(),termination.awaitNanos()会上抛InterruptException,awaitTermination()继续上抛给调用线程,会以异常的形式解除阻塞
综上,要想优雅的关闭线程池,我们应该:
1 | executorService.shutdown(); |
5 拒绝策略
我们最后来看一下线程池构造函数的最后一个参数:RejectedExecutionHandler。
任务拒绝模块是线程池的保护部分,线程池有一个最大的容量,当线程池的任务缓存队列已满,并且线程池中的线程数目达到maximumPoolSize时,就需要拒绝掉该任务,采取任务拒绝策略,保护线程池。
拒绝策略是一个接口,其设计如下:
1 | public interface RejectedExecutionHandler { |
用户可以通过实现这个接口去定制拒绝策略,也可以选择JDK提供的四种已有拒绝策略,其特点如下:
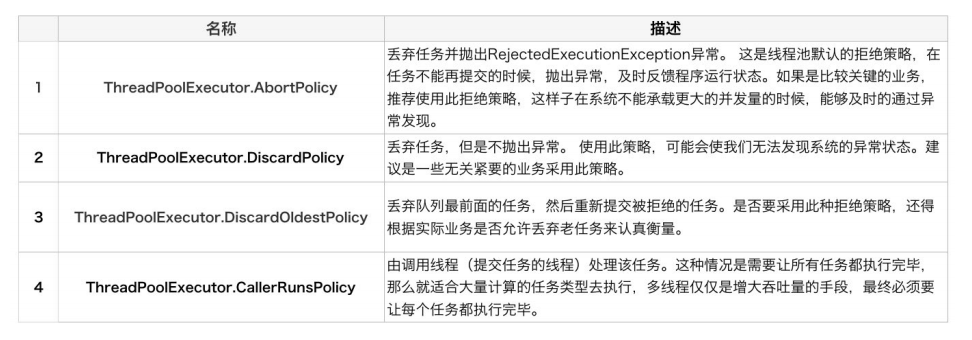
四个拒绝策略的代码如下:
1 | /** |
核心的rejectedExecution方法,在ThreadPoolExecutor中被reject方法调用:
1 |
|
而reject方法在execute方法中被调用:
1 | /** |