前言
项目中的es由ver.1.4.5升级至ver.5.2.0。
安装elasticSearch
1 | #下载 |
修改elasticsearch.yml
1 | $ES_HOME/config/elasticsearch.yml |
在这里不详细展开elasticsearch.yml的各个配置项,附上链接。
配置es外部链接
安装elasticsearch-head
lasticsearch-head是一个很好的可视化前端框架,方便用可视化界面对es进行调用。elasticsearch-head在Github的地址如下:https://github.com/mobz/elasticsearch-head
安装也不复杂,由于它是一个前端的工具,因此需要我们预先安装了node和npm,之后执行下面的步骤:
1 | git clone git://github.com/mobz/elasticsearch-head.git |
安装完成后,运行命令npm run start就行。
调整弃用api的兼容问题
1.setting
1.4.5的org.elasticsearch.common.settings.ImmutableSettings已经弃用,生成配置对象setting的方式改成:
1 | Settings settings = Settings.builder().put("cluster.name", clusterName).put("client.transport.sniff", true).build(); |
2.InetSocketTransportAddress
org.elasticsearch.common.transport.InetSocketTransportAddress#InetSocketTransportAddress(java.lang.String, int)方法已经弃用,注入集群地址的方式改成:
1 | clusterNodeAddressList.add(new InetSocketTransportAddress(InetAddress.getByName(host), 9300)); |
3.TransportClient
org.elasticsearch.client.transport.TransportClient#TransportClient(org.elasticsearch.common.settings.Settings),该构造方法已经弃用,生成TransportClient实例的方式改成:
1 | transportClient = new PreBuiltTransportClient(settings); |
4.ClusterHealthStatus
org.elasticsearch.action.admin.cluster.health.ClusterHealthStatus类已经弃用,相同功能由org.elasticsearch.cluster.health.ClusterHealthStatus继承
5.ScriptSortBuilder调整
原版写法:
1 | Map<Object, Integer> optionalSortMap = manualSortMapBuilder.put("other", sortIndex + 1).build(); |
调整为:
1 | Map<Object, Integer> optionalSortMap = manualSortMapBuilder.put("other", sortIndex + 1).build(); |
6.FilterBuilder调整
org.elasticsearch.index.query.FilterBuilder类已经弃用,基本上从2.x版本开始,Filter就已经弃用了(不包括bool查询内的filter),所有FilterBuilder全都要用QueryBuilder的各种子类来调整:
1.org.elasticsearch.index.query.BoolFilterBuilder
1 | BoolFilterBuilder boolFilterBuilder = FilterBuilders.boolFilter(); |
调整为:
1 | BoolQueryBuilder boolFilterBuilder = new BoolQueryBuilder(); |
2.org.elasticsearch.index.query.NestedFilterBuilder
1 | filterBuilder = FilterBuilders.nestedFilter(param.getPath(), boolFilterBuilder); |
调整为:
1 | filterBuilder = new NestedQueryBuilder(param.getPath(), boolFilterBuilder, ScoreMode.None); |
3.org.elasticsearch.index.query.MissingFilterBuilder
5.x版本中,missing关键字已经弃用,其功能由其逆运算exist继承。
1 | MissingFilterBuilder missingFilterBuilder = FilterBuilders.missingFilter(paramName); |
调整为:
1 | ExistsQueryBuilder existsQueryBuilder = new ExistsQueryBuilder(paramName); |
4.org.elasticsearch.index.query.TermFilterBuilder
1 | filterBuilder = FilterBuilders.termFilter(paramName, param.getEqValue()); |
调整为:
1 | filterBuilder = new TermQueryBuilder(paramName, param.getEqValue()); |
5.org.elasticsearch.index.query.TermsFilterBuilder
1 | filterBuilder = FilterBuilders.inFilter(paramName, param.getInValues()); |
调整为:
1 | filterBuilder = new TermsQueryBuilder(paramName, param.getInValues()); |
6.org.elasticsearch.index.query.RangeFilterBuilder
1 | //gte |
调整为:
1 | //gte |
7.search_type=count
原来我们想要计算文档的需要用到search_type=count,现在5.0已经将该API移除,取而代之你只需将size置于0即可:
1 | GET /my_index/_search?search_type=count |
调整为:
1 | #5.0以后 |
8.RangeBuilder
org.elasticsearch.search.aggregations.bucket.range.RangeBuilder已经弃用,相应功能由org.elasticsearch.search.aggregations.bucket.range.RangeAggregationBuilder实现,直接替换即可。
9.TopHitsAggregationBuilder
org.elasticsearch.search.aggregations.metrics.tophits.TopHitsBuilder已经弃用,相应功能由org.elasticsearch.search.aggregations.metrics.tophits.TopHitsAggregationBuilder实现,直接替换即可。
10.FiltersAggregationBuilder
org.elasticsearch.search.aggregations.bucket.filters.FiltersAggregationBuilder构造报文调整
1 | FiltersAggregationBuilder filtersAggregationBuilder = AggregationBuilders.filters(aggregationField.getAggName()); |
调整成:
1 | List<FiltersAggregator.KeyedFilter> keyedFilters = new LinkedList<FiltersAggregator.KeyedFilter>(); |
11.HighlightBuilder;
org.elasticsearch.search.highlight.HighlightBuilder弃用,相关功能由org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder实现。
12.OptimizeRequestBuilder
org.elasticsearch.action.admin.indices.optimize.OptimizeRequestBuilder 已经弃用,聚合索引的功能由org.elasticsearch.action.admin.indices.forcemerge.ForceMergeRequestBuilder来实现。
13.IndicesAliasesRequestBuilder
1.newAddAliasAction
旧版删除了AliasAction类的newAddAliasAction方法,故而IndicesAliasesRequestBuilder添加AliasActions应该:
1 | requestBuilder.addAliasAction(AliasAction.newAddAliasAction(toIndex, indexAlias)); |
调整成
1 | requestBuilder.addAliasAction(IndicesAliasesRequest.AliasActions.add().index(toIndex).alias(indexAlias)); |
2.newRemoveAliasAction
旧版删除了AliasAction类的newRemoveAliasAction方法,故而IndicesAliasesRequestBuilder删除AliasActions应该:
1 | requestBuilder.addAliasAction(AliasAction.newRemoveAliasAction(fromIdx, indexAlias)); |
调整成
1 | requestBuilder.addAliasAction(IndicesAliasesRequest.AliasActions.remove().index(fromIdx).alias(indexAlias)); |
14.AbstractAggregationBuilder的子类变更
1.org.elasticsearch.search.aggregations.bucket.terms.TermsBuilder
org.elasticsearch.search.aggregations.bucket.terms.TermsBuilder更名为
org.elasticsearch.search.aggregations.bucket.terms.TermsAggregationBuilder
2.org.elasticsearch.search.aggregations.bucket.range.date.DateRangeBuilder
org.elasticsearch.search.aggregations.bucket.range.date.DateRangeBuilder更名为
org.elasticsearch.search.aggregations.bucket.range.date.DateRangeAggregationBuilder
3.org.elasticsearch.search.aggregations.metrics.tophits.TopHitsBuilder
org.elasticsearch.search.aggregations.metrics.tophits.TopHitsBuilder更名为
org.elasticsearch.search.aggregations.metrics.tophits.TopHitsAggregationBuilder
15.SearchHit类
org.elasticsearch.search.SearchHit#isSourceEmpty方法改为org.elasticsearch.search.SearchHit#hasSource方法,反向替换。
16.DeleteByQueryResponse
org.elasticsearch.action.deletebyquery.DeleteByQueryResponse已经弃用,
调整关键字等结构性问题
1. String数据类型弃用
在 ES2.x 版本字符串数据是没有 keyword 和 text 类型的,只有string类型,ES更新到5版本后,取消了 string 数据类型,代替它的是 keyword 和 text 数据类型。区别在于:
text类型定义的文本会被分析,在建立索引前会将这些文本进行分词,转化为词的组合,建立索引。允许 ES来检索这些词语。text 数据类型不能用来排序和聚合。
keyWord类型表示精确查找的文本,不需要进行分词。可以被用来检索过滤、排序和聚合。keyword 类型字段只能用本身来进行检索。
在没有显性定义时,es默认为“text”类型。
2. multi_field关键字弃用
相关mapping方式改为:
1 | #对需要设置的字段,在'type'属性后增加"fields": |
3. analyzer
1.改版后,设置了search_analyzer的情况下,analyzer也要设置,否则会报:
1 | analyzer on field [name] must be set when search_analyzer is set。 |
2.改版后,index_analyzer设置被弃用,如果设置,会报
1 | MapperParsingException[Mapping definition for [fields] has unsupported parameters: [index_analyzer : ik_max_word]]; |
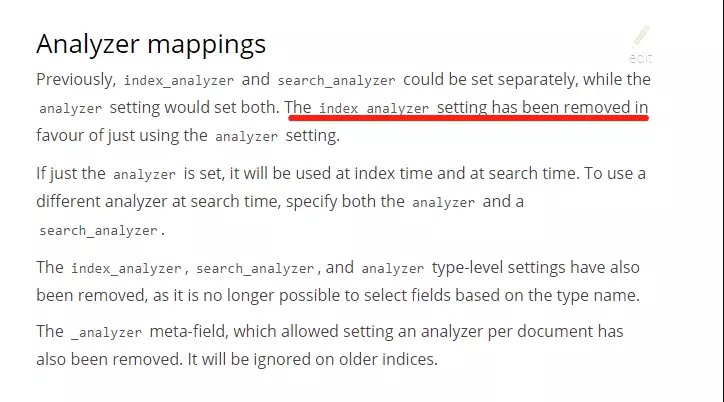
这里扩展一下,在原来的版本中,index_analyzer负责建立索引时的分词器定义,search_analyzer负责搜索时的分词器定义。
索引期间查找解析器的完整顺序是这样的:
- 定义在字段映射中的index_analyzer
- 定义在字段映射中的analyzer
- 定义在文档_analyzer字段中的解析器
- type的默认index_analyzer
- type的默认analyzer
- 索引设置中default_index对应的解析器
- 索引设置中default对应的解析器
- 节点上default_index对应的解析器
- 节点上default对应的解析器
- standard解析器
而查询期间的完整顺序则是:
- 直接定义在查询中的analyzer
- 定义在字段映射中的search_analyzer
- 定义在字段映射中的analyzer
- type的默认search_analyzer
- type的默认analyzer
- 索引设置中的default_search对应的解析器
- 索引设置中的default对应的解析器
- 节点上default_search对应的解析器
- 节点上default对应的解析器
- standard解析器
现在新版删除index_analyzer,具体功能由analyzer关键字承担,analyzer关键字生效与index时和search时(除非search_analyzer已经被显性定义)。
3. _timestamp在2.0弃用
_timestamp官方建议自定义一个字段,自己赋值用来表示时间戳。
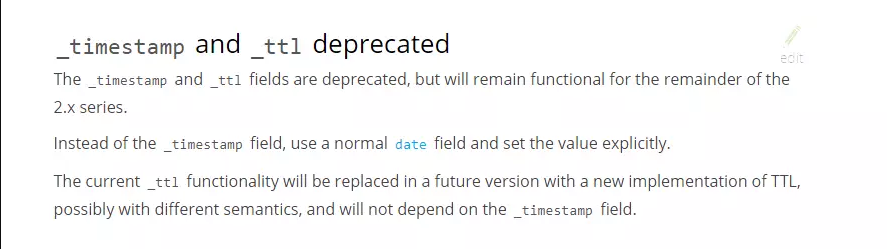
4. 嵌套字段排序时字段名称调整
对于如下的数据:
1 | PUT /my_index/blogpost/2 |
老版本中,对stars字段进行排序时,直接可以
1 | "sort" : [ |
但在新版中,上述报文会报
1 | No mapping found for [stars] in order to sort on |
需要改成:
1 | "sort" : [ |
5. _script脚本参数名变更
老版中,_script可以这样定义
1 | "sort" : [ |
新版中,对于params的参数paramsMap必须用params.paramsMap
1 | "sort" : [ |
注意:es 5.2.0默认禁用了动态语言,所以lang为painless之外的语言,默认情况下会报
1 | ScriptException[scripts of type [inline], operation [update] and lang [groovy] are disabled]; |
需要在yml文件中添加配置(如groovy):
1 | script.engine.groovy.inline:true |
6 .获取特定字段返回
在旧版本中,获取特定文档特定字段返回,可以使用stored_fields:
1 | { |
新版本中,引入了更为强大的_source过滤器
1 | { |
或者
1 |
|
java的api主要调用SearchRequestBuilder的setFetchSource方法
7. date字段的format定义
改版后,date字段最好再mapping时定义好format信息,以防止在请求前后因为格式转换问题报错:
1 | ElasticsearchParseException[failed to parse date field [Thu Jun 18 00:00:00 CST 2015] with format [strict_date_optional_time||epoch_millis]]; nested: IllegalArgumentException[Parse failure at index [0] of [Thu Jun 18 00:00:00 CST 2015]]; } |
[strict_date_optional_time||epoch_millis]是es默认的date字段解析格式
8. UncategorizedExecutionException
改版前,transport client发送数据之前将java代码中的字段序列化成了json然后进行传输和请求,而在5.x以后,es改用使用的内部的transport protocol,这时候,如果定义一个比如bigDecimal类型,es不支持bigDecimal,数据类型不匹配会抛错误。
1 | UncategorizedExecutionException[Failed execution]; nested: IOException[can not write type [class java.math.BigDecimal]]; |
es支持的格式如下
1 | static { |