导航栏位于右侧,只收录常用命令,按字母表排序
A
alias-设置指令的别名
简介:
别名就是一种便捷方式,可以为用户省去输入一长串命令序列的麻烦。Linux alias命令用于设置指令的别名。用户可利用alias,自定指令的别名。若仅输入alias,则可列出目前所有的别名设置。alias的效力仅及于该次登入的操作。若要每次登入是即自动设好别名,可在.profile或.bashrc中设定指令的别名。
语法:
alias[别名]=[指令名称]代码示例
1
2
3
4
5
6
7
8
9
10//为apt-get install创建别名。
$ alias install='sudo apt-get install'
//alias命令的效果只是暂时的。一旦关闭当前终端,所有设置过的别名就失效了。
//为了使别名在所有的shell中都可用,可以将其定义放入~/.bashrc文件中。
//每当一个新的交互式shell进程生成时,都会执行 ~/.bashrc中的命令。
$ echo 'alias cmd="command seq"' >> ~/.bashrc
//我们可以创建一个别名rm,它能够删除原始文件,同时在backup目录中保留副本。
$ alias rm='cp $@ ~/backup && rm $@'注意事项
alias命令若不加任何参数,则列出目前所有的别名设置。
如果需要删除别名,只需将其对应的定义(如果有的话)从~/.bashrc中删除,或者使用unalias命令。也可以使用alias example=,这会取消别名example。
创建别名时,如果已经有同名的别名存在,那么原有的别名设置将被新的
设置取代。如果我们遇到别名和原生命令同名的情况,我们可以转义要使用的命令,忽略当前定义的别名:
$ \command
字符\可以转义命令,从而执行原本的命令。在不可信环境下执行特权命令时,在命令前加上\来忽略可能存在的别名总是一种良好的安全实践。这是因为攻击者可能已经将一些别有用心的命令利用别名伪装成了特权命令,借此来盗取用户输入的重要信息。
awk——把文件逐行的读入,以分隔符将其切片,再进行处理。
简介:
- awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大。简单来说awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。
- awk有3个不同版本: awk、nawk和gawk,未作特别说明,一般指gawk,gawk 是 AWK 的 GNU 版本。
- 之所以叫AWK是因为其取了三位创始人 Alfred Aho,Peter Weinberger, 和 Brian Kernighan 的 Family Name 的首字符。
语法:
awk [选项参数] '{pattern + action}' {filenames}- 尽管操作可能会很复杂,但语法总是这样,其中 pattern 表示 AWK 在数据中查找的内容,而 action 是在找到匹配内容时所执行的一系列命令。花括号({})不需要在程序中始终出现,但它们用于根据特定的模式对一系列指令进行分组。 pattern就是要表示的正则表达式,用斜杠括起来。
- awk语言的最基本功能是在文件或者字符串中基于指定规则浏览和抽取信息,awk抽取信息后,才能进行其他文本操作。完整的awk脚本通常用来格式化文本文件中的信息。
- 通常,awk是以文件的一行为处理单位的。awk每接收文件的一行,然后执行相应的命令,来处理文本。
选项值:
-F fs or –field-separator fs
- 指定输入文件折分隔符,fs是一个字符串或者是一个正则表达式。在awk中,文件的每一行中,由域分隔符分开的每一项称为一个域。通常,在不指名-F域分隔符的情况下,默认的域分隔符是空格。
-v var=value or –asign var=value
- 赋值一个用户定义变量。
-f scripfile or –file scriptfile
- 从脚本文件中读取awk命令。
-mf nnn and -mr nnn
- 对nnn值设置内在限制,-mf选项限制分配给nnn的最大块数目;-mr选项限制记录的最大数目。这两个功能是Bell实验室版awk的扩展功能,在标准awk中不适用。
-W compact or –compat, -W traditional or –traditional
- 在兼容模式下运行awk。所以gawk的行为和标准的awk完全一样,所有的awk扩展都被忽略。
-W copyleft or –copyleft, -W copyright or –copyright
- 打印简短的版权信息。
-W help or –help, -W usage or –usage
- 打印全部awk选项和每个选项的简短说明。
-W lint or –lint
- 打印不能向传统unix平台移植的结构的警告。
-W lint-old or –lint-old
- 打印关于不能向传统unix平台移植的结构的警告。
内建变量
如下变量在awk中具有特定含义。
- $n 当前记录的第n个字段,字段间由FS分隔
- $0 完整的输入记录
- ARGC 命令行参数的数目
- ARGIND 命令行中当前文件的位置(从0开始算)
- ARGV 包含命令行参数的数组
- CONVFMT 数字转换格式(默认值为%.6g)ENVIRON环境变量关联数组
- ERRNO 最后一个系统错误的描述
- FIELDWIDTHS 字段宽度列表(用空格键分隔)
- FILENAME 当前文件名
- FNR 各文件分别计数的行号
- IGNORECASE 如果为真,则进行忽略大小写的匹配
- NF 一条记录的字段的数目
- NR 已经读出的记录数,就是行号,从1开始
- OFMT 数字的输出格式(默认值是%.6g)
- OFS 输出记录分隔符(输出换行符),输出时用指定的符号代替换行符
- ORS 输出记录分隔符(默认值是一个换行符)
- RLENGTH 由match函数所匹配的字符串的长度
- RS 记录分隔符(默认是一个换行符)
- RSTART 由match函数所匹配的字符串的第一个位置
- SUBSEP 数组下标分隔符(默认值是/034)
代码示例
awk工作流程是这样的:读入有’\n’换行符分割的一条记录,然后将记录按指定的域分隔符划分域,填充域,$0则表示所有域,$1表示第一个域,$n表示第n个域。默认域分隔符是”空白键” 或 “[tab]键”,所以$1表示登录用户,$3表示登录用户ip,以此类推。
action的使用示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49//假设last -n 5的输出如下
$ last -n 5 <==仅取出前五行
> root pts/1 192.168.1.100 Tue Feb 10 11:21 still logged in
> root pts/1 192.168.1.100 Tue Feb 10 00:46 - 02:28 (01:41)
> root pts/1 192.168.1.100 Mon Feb 9 11:41 - 18:30 (06:48)
> dmtsai pts/1 192.168.1.100 Mon Feb 9 11:41 - 11:41 (00:00)
> root tty1 Fri Sep 5 14:09 - 14:10 (00:01)
//使用awk显示最近登录的5个帐号
$ last -n 5 | awk '{print $1}'
> root
> root
> root
> dmtsai
> root
//如果只是显示/etc/passwd文件中的账户信息
$ awk -F ':' '{print $1}' /etc/passwd
> root
> daemon
> bin
> sys
//显示/etc/passwd文件中的账户和账户对应的shell信息,而账户与shell之间以tab键分割
$ awk -F ':' '{print $1"\t"$7}' /etc/passwd
> root /bin/bash
> daemon /bin/sh
> bin /bin/sh
> sys /bin/sh
//格式化输出
$ awk '{printf "%-8s %-10s\n",$1,$7}' /etc/passwd
> root /bin/bash
> daemon /bin/sh
> bin /bin/sh
> sys /bin/sh
//显示/etc/passwd的账户和账户对应的shell,而账户与shell之间以逗号分割
//而且在所有行添加列名name,shell,在最后一行添加"blue,/bin/nosh"。
// 遇到BEGIN和END关键字,则二者分别在 读取文件之前 和 所有记录读完之后 执行
$ awk -F ':' 'BEGIN {print "name,shell"} {print $1","$7} END {print "blue,/bin/nosh"}' /etc/passwd
> name,shell
> root,/bin/bash
> daemon,/bin/sh
> bin,/bin/sh
> sys,/bin/sh
> blue,/bin/noshpattern使用示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30// 搜索/etc/passwd有root关键字的所有行,
$ awk -F: '/root/' /etc/passwd
> root:x:0:0:root:/root:/bin/bash
// 匹配了pattern(这里是root)的行才会执行action(本例未指定action,默认输出每行的内容,即$0,下例指定action)。
// 搜索支持正则,例如找root开头的: awk -F: '/^root/' /etc/passwd
//指定action{print $7}。搜索/etc/passwd有root关键字的所有行,并显示对应的shell
$ awk -F: '/root/{print $7}' /etc/passwd
> /bin/bash
//过滤第一列大于2的行(action就不指定了)
$ awk '$1>2' /etc/passwd
//过滤第一列等于2的行(action就不指定了)
$ awk '$1=2' /etc/passwd
//过滤第一列大于2并且第二列等于'Are'的行(action就不指定了)
$ awk '$1>2 && $2=="Are"' /etc/passwd
//过滤第一列包含 "th"的行(action就不指定了)
$ awk '$1 ~ /th/' /etc/passwd
//过滤第一列包含 "th"的行,忽略大小写(action就不指定了)
$ awk 'BEGIN{IGNORECASE=1} $1 ~ /th/' /etc/passwd
//过滤第一列不包含 "th"的行,忽略大小写(action就不指定了)
$ awk 'BEGIN{IGNORECASE=1} $1 !~ /th/' /etc/passwd
//过滤整行不包含 "th"的行,忽略大小写(action就不指定了)
$ awk 'BEGIN{IGNORECASE=1} !/th/' /etc/passwd变量赋值和使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22// 内建变量赋值。使用BEGIN替代-F,其中FS是awk内建变量
$ awk 'BEGIN{FS=":"} {print $1}' /etc/passwd
> root
> daemon
> bin
> sys
// 内建变量使用。使用BEGIN替代-F,其中FS是awk内建变量,并且打印文件名,使用FILENAME内建变量
$ awk 'BEGIN{FS=":"} {print FILENAME,$1}' /etc/passwd
> /etc/passwd root
> /etc/passwd daemon
> /etc/passwd bin
> /etc/passwd sys
//-v变量赋值用法
$ awk -F: -va=1 -vb=s '/root/{print $7,$7+a,$7b}' /etc/passwd
> /bin/bash 1 /bin/bashs
> /bin/false 1 /bin/falses
//BEGIN同理
$ awk -F: 'BEGIN {a=1;b=s} /root/{print $7,$7+a,$7b}' /etc/passwd
> /bin/bash 1 /bin/bashs
> /bin/false 1 /bin/falses其他一些实例
1
2
3
4
5//计算文件大小
$ ls -l *.txt | awk '{sum+=$6} END {print sum}'
//从文件中找出长度大于80的行
$ awk 'length>80' /etc/passwdawk还支持条件语句和循环,使用较少,本文不再展开。
B
C
cat-连接文件或标准输入至标准输出
简介:
cat命令是linux下的一个文本输出命令,其功能是连接文件或标准输入至标准输出,常用于显示文件内容 。cat是concatenate(串联)的缩写。
语法:
cat [选项参数] [--help] [--version] fileName
选项值:
-n 或 –number
- 由 1 开始对所有输出的行数编号。
-b 或 –number-nonblank
- 和 -n 相似,只不过对于空白行不编号。
-s 或 –squeeze-blank
- 当遇到有连续两行以上的空白行,就代换为一行的空白行。
-v 或 –show-nonprinting
- 以^和M-显示不可打印字符,除LFD与TAB
-E 或 –show-ends
- 在每行结束处显示 $。
-T 或 –show-tabs
- 将 TAB 字符显示为 ^I。这有助于排查缩进错误。
-A, –show-all
- 等价于-vET显示所有,以$结尾。
-e
- 在每行行尾添加$,用以标记
-t
- 等价于”-vT”选项;
代码示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25//打印多个文件的内容
cat one.txt two.txt
This line is from one.txt
This line is from two.txt
//将stdin和另一个文件中的数据组合在一起,其中-被作为stdin文本的文件名。
echo 'Text through stdin' | cat - file.txt
//把 textfile1 的文档内容加上行号后输入 textfile2 这个文档里:
cat -n textfile1 > textfile2
//把 textfile1 和 textfile2 的文档内容加上行号(空白行不加)之后将内容附加到 textfile3 文档里:
cat -b textfile1 textfile2 >> textfile3
//有时候,我们只希望抓取文件中感兴趣的关键字
cat fileName | grep keyword
//清空某个文件内容
cat /dev/null > /test.txt
//创建文件,并把标准输入输出到filename文件中
cat>filename,
//以EOF作为输入结束,将输入流重定向覆盖filename文件,可用于创建文件,追加使用>>
cat>filename<<EOF注意事项
现在我们知道cat << EOF语句表示 打印以EOF输入字符为标准输入结束的流内容,EOF是“end of file”, 表示文本结束符。用在这里起到什么作用?首先必须要说明的是EOF在这里没有特殊的含义,你可以使用FOE或 OOO等(当然也不限制在三个字符或大写字符)可以把EOF替换成其他东西。cat << OOF的含义即为打印以OOF输入字符为标准输入结束的流内容,代码如下图
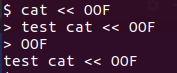
cat>filename,创建文件,并把标准输入输出到filename文件中,以ctrl+d作为输入结束。
cat>filename<<EOF等价于cat<
filename,执行顺序固定是输入早于输出 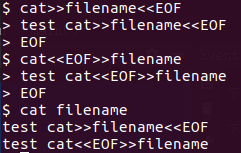
cd——切换当前工作目录
简介:
- Linux cd命令用于切换当前工作目录至 dirName(目录参数)。
- 其中 dirName 表示法可为绝对路径或相对路径。若目录名称省略,则变换至使用者的 home 目录 (也就是刚 login 时所在的目录)。
- 另外,”~” 也表示为 home 目录 的意思,”.” 则是表示目前所在的目录,”..” 则表示目前目录位置的上一层目录;”-“表示上次所在目录
语法:
cd [dirName]- dirName:要切换的目标目录。
选项值:
- 代码示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14//跳到 /usr/bin/
$ cd /usr/bin
//跳到自己的 home 目录
$ cd ~
//跳到目前目录的上层
$ cd ..
//跳到目前目录的上上两层
$ cd ../..
//返回之前的目录
$ cd -
chmod-设置文件权限
简介:
Linux/Unix 的文件调用权限分为三级:用户,用户组,其他用户。利用 chmod 可以藉以控制文件如何被他人所调用。
语法:
chmod [选项参数] mode filename- 其中mode为权限设定字串,格式如下
[ugoa...][[+-=][rwxX]...][,...]- u 表示该文件的拥有者,g 表示与该文件的拥有者属于同一个用户组(group)者,o 表示其他用户,a 表示这三者皆是。
- +表示增加权限、- 表示取消权限、= 表示唯一设定权限。
- r 表示可读取,w 表示可写入,x 表示可执行,X 表示只有当该文件是个子目录或者该文件已经被设定过为可执行。
- x 权限的位置上还可能出现t表示文件有执行权限并设置了粘滞位权限、T表示文件没有执行权限并设置了粘滞位权限、S表示setuid(S)的特殊权限,setuid权限允许可执行文件以其拥有者的权限来执行,即使这个可执行文件是由其他用户运行的。
- 同时,mode也可以使用3位八进制数来表示,每一位按顺序分别对应用户、用户组和其他用户。其中r=4,w=2,x=1。所以:
- rwx属性:4+2+1=7;
- rw-属性:4+2=6;
- r-x属性:4+1=5;
- 以此类推…
选项值:
-c
- 若该文件权限确实已经更改,才显示其更改动作
-f
- 若该文件权限无法被更改也不要显示错误讯息
-v
- 显示权限变更的详细资料
-R
- 对目前目录下的所有文件与子目录进行相同的权限变更(即以递回的方式逐个变更)
–help
- 显示辅助说明
–version
- 显示版本
代码示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30//将文件 file1.txt 设为所有人皆可读取
$ chmod ugo+r file1.txt
或
$ chmod a+r file1.txt
//将 file1.txt 设定为只有该文件拥有者可以执行 :
$ chmod u+x file1.txt
//将文件 file1.txt 与 file2.txt 设为该文件拥有者,与其所属同一用户组的用户可写入,但其他以外的人则不可写入
$ chmod ug+w,o-w file1.txt file2.txt
//将目前目录下的所有文件与子目录皆设为任何人可读取 :
$ chmod -R a=rwx *
或
$ chmod 777 . -R
或
$ chmod 777 "$(pwd)" -R
//给所有用户赋值读写执行权限
$ chmod a=rwx file
或
$ chmod 777 file
//给文件拥有用户和其相同用户组用户读写执行权限,其他用户可执行权限。
$ chmod ug=rwx,o=x file
或
$ chmod 771 file
//给特定目录加粘滞位权限(设置粘滞位后,只有目录的所有者才能够删除目录中的文件,即使其他人有该目录的写权限也无法执行删除操作。)
$ chmod a+t directoryName注意事项
chmod 4755 filename 使此程序具有root的权限
chown-更改文件或目录的所有权
- 简介:
- Linux/Unix 是多人多工操作系统,所有的文件皆有拥有者。利用 chown 将指定文件的拥有者改为指定的用户或组,用户可以是用户名或者用户ID;组可以是组名或者组ID;文件是以空格分开的要改变权限的文件列表,支持通配符。
- 一般来说,这个指令只有是由系统管理者(root)所使用,一般使用者没有权限可以改变别人的文件拥有者,也没有权限可以自己的文件拥有者改设为别人。只有系统管理者(root)才有这样的权限。语法:
chown [选项参数] [--help] [--version] user[:group] file...- 其中user表示新的文件拥有者的使用者 ID。group表示新的文件拥有者的使用者组(group)
选项值:
-c
- 显示更改的部分的信息
-f
- 忽略错误信息
-h
- 修复符号链接
-v
- 显示详细的处理信息
-R
- 处理指定目录以及其子目录下的所有文件
–help
- 显示辅助说明
–version
- 显示版本
代码示例
1
2
3
4
5//将文件 file1.txt 的拥有者设为 runoob,群体的使用者 runoobgroup :
$ chown runoob:runoobgroup file1.txt
//将目前目录下的所有文件与子目录的拥有者皆设为 runoob,群体的使用者 runoobgroup:
$ chown -R runoob:runoobgroup *注意事项
cp-于复制文件或目录
简介:
Linux cp命令主要用于复制文件或目录。
语法:
cp [options] source dest 或 cp [options] source... directory
选项值:
-a
- 此选项通常在复制目录时使用,它保留链接、文件属性,并复制目录下的所有内容。其作用等于dpR参数组合。
-d
- 复制时保留链接。这里所说的链接相当于Windows系统中的快捷方式。
-f
- 覆盖已经存在的目标文件而不给出提示。
-i
- 与-f选项相反,在覆盖目标文件之前给出提示,要求用户确认是否覆盖,回答”y”时目标文件将被覆盖。
-p
- 除复制文件的内容外,还把修改时间和访问权限也复制到新文件中。
-r
- 若给出的源文件是一个目录文件,此时将复制该目录下所有的子目录和文件。
-l
- 不复制文件,只是生成链接文件。
代码示例
1
2//使用指令"cp"将当前目录"test/"下的所有文件复制到新目录"newtest"下
$ cp –r test/ newtest注意事项
用户使用该指令复制目录时,必须使用参数”-r”或者”-R”。
curl——发送各种HTTP请求
简介:
- curl命令的用途广泛,其功能包括下载、发送各种HTTP请求以及指定HTTP头部。
- cURL默认会将下载文件输出到stdout,将进度信息输出到stderr。如果不想显示进度信息,可以使用–silent选项
- cURL可以使用HTTP、HTTPS、FTP协议在客户端与服务器之间传递数据。它支持POST、cookie、认证、从指定偏移处下载部分文件、参照页(referer)、用户代理字符串、扩展头部、限速、文件大小限制、进度条等特性。cURL可用于网站维护、数据检索以及服务器配置核对。
语法:
curl [选项] url
选项值:
–silent
- 不显示进度信息
-O
- 指明将下载数据写入文件,采用从URL中解析出的文件名。注意,其中的URL必须是完整的,不能仅是站点的域名
$ curl www.knopper.net/index.htm -O
-o
- 指明将下载数据写入文件,可以指定输出文件名。如果使用了该选项,只需要写明站点的域名就可以下载其主页了
$ curl www.knopper.net -o knoppix_index.html
–progress
- 在下载过程中显示形如#的进度条
$ curl http://knopper.net -o index.html --progress
################################## 100.0%
-C
- 够从特定的文件偏移处继续下载,偏移量是以字节为单位的整数。
$ curl URL/file -C offset- 如果只是想断点续传,那么cURL不需要指定准确的字节偏移。要是你希望cURL推断出正确的续传位置,请使用选项-C -。cURL会自动计算出应该从哪里开始续传
$ curl -C - www.xxx.com
–referer
- 指定参照页字符串。参照页(referer)①是位于HTTP头部中的一个字符串,用来标识用户是从哪个页面到达当前页面的。如果用户通过点击页面A中的某个链接跳转到了页面B,那么页面B头部的参照页字符串就会包含页面A的URL。
- 一些动态页面会在返回HTML数据前检测参照页字符串。例如,如果用户是通过Google搜索来到了当前页面,那么页面上就可以显示一个Google的logo;
$ curl --referer Referer_URL target_URL 如 $ curl --referer http://google.com http://knopper.org
–cookie
- 指定储HTTP操作过程中使用到的cookie,cookies需要以name=value的形式来给出。多个cookie之间使用分号分隔
$ curl http://example.com --cookie "user=username;pass=hack"
–cookie-jar
- 可以将cookie另存为文件
$ curl URL --cookie-jar cookie_file
-b
- 指定以一个存储了Cookie值的本地文件内容作为cookie
$ curl -b stored_cookies_in_file www.baidu.com
–user-agent或-A
- 设置用户代理字符串,如果不指定用户代理(user agent),一些需要检验用户代理的页面就无法显示。例如,有些旧网站只能在Internet Explorer(IE)下正常工作。如果使用其他浏览器,则会提示只能用IE访问。这是因为这些网站检查了用户代理。
$ curl URL --user-agent "Mozilla/5.0"
-H
- 发送HTTP头部信息
$ curl -H "Host: www.knopper.net" -H "Accept-language: en" URL
–limit-rate
- 如果多个用户共享带宽有限,我们可以用–limit-rate限制cURL的下载速度。在命令中用k(千字节)和m(兆字节)指定下载速度限制
$ curl URL --limit-rate 20k
–max-filesize
- 指定可下载的最大文件大小。如果文件大小超出限制,命令返回一个非0的退出码。如果文件下载成功,则返回0。
$ curl URL --max-filesize bytes
-u
- 指定用户名和密码完成HTTP或FTP认证
$ curl -u user:pass http://test_auth.com- 如果你喜欢经提示后输入密码,只需要使用用户名即可
$ curl -u user http://test_auth.com
-I 或–head
- 只打印HTTP头部信息,无须下载远程文件。只检查头部信息就足以完成很多检查或统计。例如,如果要检查某个页面是否能够打开,并不需要下载整个页面内容。只读取HTTP响应头部就足够了。
$ curl -I http://knopper.net
-E或–cert
- 指定本地证书
$ curl -E mycert.pem https:/itbilu.com
-T 或–upload-file
- 上传文件
$ curl -T ./index.html www.uploadhttp.com/receive.cgi
-d 或–data
- POST提交表单数据
$ curl -X POST --data 'keyword=linux' itbilu.com
-X
- 拓展http请求方法,使curl支持put,delete等
$ curl -X DELETE itbilu.com/examlple.html$ curl -X PUT --data 'keyword=linux' itbilu.com
代码示例
1
2
3
4
5//访问一个网页时,可以使用curl命令后加上要访问的网址
$ curl www.baidu.com
> <!DOCTYPE html>
> <!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;...
//我们就看到所访问网址的页面源码。注意事项
cut——按列切分文件
简介:
- cut命令能够提取指定位置或列之间的字符。你可以指定每列的分隔符。在cut的术语中,每列被称为一个字段。
- cut命令可以按列,而不是按行来切分文件。该命令可用于处理使用固定宽度字段的文件、CSV文件或是由空格分隔的文件(例如标准日志文件)。
- cut 命令从文件的每一行剪切字节、字符和字段并将这些字节、字符和字段写至标准输出。如果不指定 File 参数,cut 命令将读取标准输入。必须指定 -b、-c 或 -f 标志之一。
语法:
cut [选项参数] [file]
选项值:
-b
- 以字节为单位进行分割。这些字节位置将忽略多字节字符边界,除非也指定了 -n 标志。
- range可以为如下格式,如cut -b 2-5 file
- N-:从第N个字节、字符、字段到结尾;
- N-M:从第N个字节、字符、字段到第M个(包括M在内)字节、字符、字段;
- -M:从第1个字节、字符、字段到第M个(包括M在内)字节、字符、字段。
-c
- 以字符为单位进行分割。
- range可以为如下格式,如cut -c 2-5 file
- N-:从第N个字节、字符、字段到结尾;
- N-M:从第N个字节、字符、字段到第M个(包括M在内)字节、字符、字段;
- -M:从第1个字节、字符、字段到第M个(包括M在内)字节、字符、字段。
-d
- 自定义分隔符,默认为制表符。
-f
- 指定要提取的列。FIELD_LIST是需要显示的列。它由列号组成,彼此之间用逗号分隔。
-n
- 取消分割多字节字符。仅和 -b 标志一起使用。如果字符的最后一个字节落在由 -b 标志的 List 参数指示的范围之内,该字符将被写出;否则,该字符将被排除
–complement
- 显示出没有被-f指定的那些字段。
–output-delimiter
- 指定输出分隔符。在显示多组数据时,该选项尤为有用
代码示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46//从使用制表符作为分隔符的文件中提取列
$ cat student_data.txt
> No Name Mark Percent
> 1 Sarath 45 90
> 2 Alex 49 98
> 3 Anu 45 90
$ cut -f 1 student_data.txt
> No
> 1
> 2
> 3
//要想提取多个字段,就得给出由逗号分隔的多个字段编号
$ cut -f 2,4 student_data.txt
> Name Percent
> Sarath 90
> Alex 98
> Anu 90
//使用cut处理由分号分隔的字段
$ cat delimited_data.txt
> No;Name;Mark;Percent
> 1;Sarath;45;90
> 2;Alex;49;98
> 3;Anu;45;90
$ cut -f2 -d";" delimited_data.txt
> Name
> Sarath
> Alex
> Anu
//打印第2个到第5个字符
$ cat range_fields.txt
> abcdefghijklmnopqrstuvwxyz
> abcdefghijklmnopqrstuvwxyz
> abcdefghijklmnopqrstuvwxyz
//打印第2个到第5个字符
$ cut -c2-5 range_fields.txt
> ab
> ab
> ab
//--output-delimiter指定输出分隔符
$ cut range_fields.txt -c1-3,6-9 --output-delimiter ","
> abc,fghi
> abc,fghi
> abc,fghi
D
date-显示或设定系统的日期与时间
简介:
Linux date命令可以用来显示或设定系统的日期与时间,在显示方面,使用者可以设定欲显示的格式,格式设定为一个加号后接数个标记。
语法:
date [-u] [-d datestr] [-s datestr] [--utc] [--universal] [--date=datestr] [--set=datestr] [--help] [--version] [+FORMAT] [MMDDhhmm[[CC]YY][.ss]]
选项值:
-d datestr
- 显示 datestr 中所设定的时间 (非系统时间)
–help
- 显示辅助讯息
-s datestr 或 –set
- 将系统时间设为 datestr 中所设定的时间
-u 或 –utc
- 显示目前的格林威治时间
–version
- 显示版本编号
–date
- 显示该选项指定的输入日期所设定的时间
注意事项
格式字段datestr必须以+号开头
当您不希望出现无意义的 0 时(比如说 1999/03/07),则可以在标记中插入 - 符号,比如说 date ‘+%-H:%-M:%-S’ 会把时分秒中无意义的 0 给去掉,像是原本的 08:09:04 会变为 8:9:4。
date命令的最小精度是秒
只有取得权限者(比如说 root)才能设定系统时间。当您以 root 身分更改了系统时间之后,请记得以 clock -w 来将系统时间写入 CMOS 中,这样下次重新开机时系统时间才会持续抱持最新的正确值。
datestr的值有如下这些可选:
%
- 印出 %
%n
- 下一行
%t
- 跳格,一个tab
%H
- 小时(00-23)
%I
- 小时(01-12)
%k
- 小时(0-23)
%l
- 小时(1-12)
%M
- 分钟(00-59)
%p
- 显示本地 AM 或 PM
%S
- 秒(00-61)
%T
- 直接显示时间 (24 小时制)
%Z
- 显示时区
%a
- 星期几 (Sun-Sat)
%A
- 星期几 (Sunday-Saturday)
%b
- 月份 (Jan-Dec)
%B
- 月份 (January-December)
%c
- 直接显示日期与时间
%d
- 日 (01-31)
%D
- 直接显示日期 (mm/dd/yy)
%h
- 同 %b
%j
- 一年中的第几天 (001-366)
%m
- 月份 (01-12)
%U
- 一年中的第几周 (00-53) (以 Sunday 为一周的第一天的情形)
%w
- 一周中的第几天 (0-6)
%W
- 一年中的第几周 (00-53) (以 Monday 为一周的第一天的情形)
%x
- 直接显示日期 (mm/dd/yy)
%y
- 年份的最后两位数字 (00-99)
%Y
- 完整年份 (0000-9999)
- 代码示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27//读取当前时间
$ date
> Thu May 20 23:09:04 IST 2010
//打印unix时间
$ date +%s
> 1290047248
//将输入的时间转换成unix时间
$ date --date "Wed mar 15 08:09:16 EDT 2017" +%s
> 1489579718
//读取当前时间
$ date "+%d %B %Y"
> 20 May 2010
//设置日期和时间
$ date -s "21 June 2009 11:01:22"
//显示时间后换行,再显示目前日期
$ date '+%T%n%D'
>23:09:00
>07/09/19
//按自己的格式输出
$ date '+usr_time: $1:%M %P -hey'
> usr_time: $1:16 下午 -hey
E
echo-打印内容
简介:
echo命令是linux中最基础的命令,也是很常用的命令,功能说明用以显示文字。
语法:
echo [-ne][字符串]或 echo [--help][--version]
选项值:
-n
- echo会在输出文本的尾部追加一个换行符。可以使用选项-n来禁止这种行为。
-e
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16激活转义字符。使用-e选项时,若字符串中出现以下字符,则特别加以处理,而不会将它当成一般文字输出:
\a 发出警告声;
\b 删除前一个字符;
\c 最后不加上换行符号;
\f 换行但光标仍旧停留在原来的位置;
\n 换行且光标移至行首;
\r 光标移至行首,但不换行;
\t 插入tab;
\v 与\f相同;
\\ 插入\字符;
\e 打印彩色文本
文本颜色是由对应的色彩码来描述的。其中包括:重置=0,黑色=30,红色=31,绿色=32,黄色=33,蓝色=34,洋红=35,青色=36,白色=37。
对于彩色背景,经常使用的颜色码是:重置=0,黑色=40,红色=41,绿色=42,黄色=43,蓝色=44,洋红=45,青色=46,白色=47。
用法:echo -e "\e[1;31m This is red text \e[0m"
其中\e[1;31m是一个转义字符串,可以将颜色设为红色,\e[0m将颜色重新置回。
\nnn 插入nnn(八进制)所代表的ASCII字符;
注意事项
echo的单引号不会解释文本中的特殊字符,双引号会。
代码示例
1
2
3
4
5$ a=1;
- echo '$a+1'
> a+1
$ echo "$a+1"
> 1+1
F
find-查找文件
简介:
- find命令的工作方式如下:沿着文件层次结构向下遍历,匹配符合条件的文件,执行相应
的操作。默认的操作是打印出文件和目录,这也可以使用-print选项来指定。
- find命令的工作方式如下:沿着文件层次结构向下遍历,匹配符合条件的文件,执行相应
语法:
find path -option [ -print ] [ -exec -ok command ] {} \;
选项值:
-mount或 -xdev
- 只检查和指定目录在同一个文件系统下的文件,避免列出其它文件系统中的文件
-newer file
- 找出比file文件更新的(更近的修改时间)所有文件。
-anewer file
- 查找比文件 file 更晚被读取过的文件
-cnewer file
- 查找比文件 file 更新的文件
-amin n
- 根据用户最近一次访问文件的时间查找,查找在过去 n 分钟内被读取过的文件,数字n前面可以加上-或+。-表示小于,+表示大于。
-atime n
- 根据用户最近一次访问文件的时间查找,查找在过去 n 天内被读取过的文件,数字n前面可以加上-或+。-表示小于,+表示大于。
-cmin n
- 根据文件元数据(例如权限或所有权)最后一次改变的时间查找,查找在过去 n 分钟内被修改过,数字n前面可以加上-或+。-表示小于,+表示大于。
-ctime n
- 根据文件元数据(例如权限或所有权)最后一次改变的时间查找,查找在过去 n 天内被修改过,数字n前面可以加上-或+。-表示小于,+表示大于。
-mtime n
- 根据文件内容最后一次被修改的时间查找,查找在过去 n 分钟内被修改过,数字n前面可以加上-或+。-表示小于,+表示大于。
-mmin n
- 根据文件内容最后一次被修改的时间查找,查找在过去 n 天内被修改过,数字n前面可以加上-或+。-表示小于,+表示大于。
-ipath p, -path p
- 查找路径名称符合 p 的文件,ipath 会忽略大小写。p一般可以为通配符如’/slynux/‘
-regex r,-iregex r
- 查找路径名称符合 r 的文件。r 一般可以为正则表达式
-name name, -iname name
- 查找文件名称符合 name 的文件。iname 会忽略大小写。这个模式可以是通配符,也可以是正则表达式。如’*.txt’能够匹配所有名字以.txt结尾的文件或目录
-size n
- 可以根据文件的大小展开搜索,n可以为+2k,数字前面可以加上-或+。-表示小于,+表示大于。单位取值可以为
- b:块(512字节)。
- c:字节。
- w:字(2字节)。
- k:千字节(1024字节)。
- M:兆字节(1024K字节)。
- G:吉字节(1024M字节)。
- 可以根据文件的大小展开搜索,n可以为+2k,数字前面可以加上-或+。-表示小于,+表示大于。单位取值可以为
-maxdepth n,–mindepth n
- -maxdepth和–mindepth选项可以限制find命令遍历的目录深度。这可以避免find命令没完没了地查找。
–user USER
- 找出由某个特定用户权限下所拥有的文件。参数USER可以是用户名或UID。
-prune n
- 在搜索时排除某些文件或目录,一般与其他选项一起使用,如.git目录应该被排除在外:
$ find devel/source_path -name '.git' -prune -o -type f -print
- 在搜索时排除某些文件或目录,一般与其他选项一起使用,如.git目录应该被排除在外:
-perm n
- 指明find应该只匹配具有特定权限值的文件。n为文件权限
$ find devel/source_path -name '.git' -prune -o -type f -print
- 指明find应该只匹配具有特定权限值的文件。n为文件权限
pid n
- process id 是 n 的文件
-type t
类Unix系统将一切都视为文件。文件具有不同的类型,例如普通文件、目录、字符设备、块
设备、符号链接、硬链接、套接字以及FIFO等。可以使用-type选项对文件搜索进行过滤。借助这个选项,我们可以告诉find命令只匹配指定类型的文件。t的取值可以是d:目录
c: 字符设备
b: 块设备
p: FIFO具名贮列
f: 一般文件
l: 符号链接
s: socket套接字
代码示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50//列出给定目录下所有的文件和子目录 find base_path
$ find . -print
> .history
> Downloads
> Downloads/tcl.fossil
//够匹配所有名字以.txt结尾的文件或目录。
$ find /home/slynux -name '*.txt' -print
//find命令支持逻辑操作符。-a和-and选项可以执行逻辑与(AND)操作,-o和-or选项可以执行逻辑或(OR)操作。
$ find . \( -name '*.txt' -o -name '*.pdf' \) -print
> ./text.pdf
> ./new.txt
//使用-and操作符选择名字以s开头且其中包含e的文件
$ find . \( -name '*e*' -and -name 's*' \)
> ./some.jpg
//匹配.py或.sh文件
$ find . -regex '.*\.(py\|sh\)$'
//find也可以用!排除匹配到的模式,匹配所有不以.txt结尾的文件
$ find . ! -name "*.txt" -print
>
//打印出在最近7天内被访问过的所有文件
$ find . -type f -atime -7 -print
//打印出访问时间超过7天的所有文件。
$ find . -type f -atime +7 -print
//找出比file.txt修改时间更近的所有文件
$ find . -type f -newer file.txt -print
//打印出用户slynux拥有的所有文件
$ find . -type f -user slynux -print
//利用find执行相应操作
//删除匹配的文件
//find命令的-delete选项可以删除所匹配到的文件。下面的命令能够从当前目录中删除.swp文件:
$ find . -type f -name "*.swp" -delete
/利用find执行相应操作
//执行命令,利用-exec选项,find命令可以结合其他命令使用。
//将某位用户(比如root)所拥有的全部文件的所有权更改成另一位用户(比如用户www-data)
//那么可以用-user找出root拥有的所有文件,然后用-exec更改所有权。
//在下面的例子中,对于每一个匹配的文件,find命令会将{}替换成相应的文件名并更改该文件的所有权。
$ find . -type f -user root -exec chown slynux {} \;
//find命令使用一对花括号{}代表文件名。注意事项
注意 find . -type f -user root -exec chown slynux {} ; 该命令结尾的;。必须对分号进行转义,否则shell会将其视为find命令的结束,而非chown命令的结束。
为每个匹配到的文件调用命令可是个不小的开销。如果指定的命令接受多个参数(如chown),你可以换用加号(+)作为命令的结尾。这样find会生成一份包含所有搜索结果的列表,然后将其作为指定命令的参数,一次性执行。
我们无法在-exec选项中直接使用多个命令。该选项只能够接受单个命令,不过我们可以耍一个小花招。把多个命令写到一个 shell脚本中(例如command.sh),然后在-exec中使用这个脚本:
-exec ./commands.sh {} ;
ftp/lftp——使用ftp协议共享文件
简介:
- 文件传输协议(File Transfer Protocol,FTP)是一个古老的协议,在很多公共站点上用于文件共享。
- FTP服务器通常运行在端口21上。远程主机上必须安装并运行FTP服务器才能使用FTP。
- 我们可以使用传统的ftp命令或更新的lftp命令访问FTP服务器。两者都支持下面要讲到的命令。很多公共网站都是用FTP共享文件
使用步骤
- 要连接FTP服务器传输文件,可以使用
$ lftp username@ftphost- 它会提示你输入密码,然后显示一个像下面这样的登录提示符
lftp username@ftphost:~>
- 你可以在提示符后输入各种命令,如下所示
- cd directory:更改远程主机目录。
- lcd:更改本地主机目录。
- mkdir:在远程主机上创建目录。
- ls:列出远程主机当前目录下的文件。
- get FILENAME:将文件下载到本地主机的当前目录中。
lftp username@ftphost:~> get filename
- put filename:将文件从当前目录上传到远程主机。
lftp username@ftphost:~> put filename
- quit命令可以退出lftp会话
- 要连接FTP服务器传输文件,可以使用
注意事项
lftp提示符支持命令自动补全。
G
grep——在文件中搜索文本
简介:
Linux grep命令用于查找文件里符合条件的字符串。
grep指令用于查找内容包含指定的范本样式的文件,如果发现某文件的内容符合所指定的范本样式,预设grep指令会把含有范本样式的那一行显示出来。
若不指定任何文件名称,或是所给予的文件名为”-“,则grep指令会从标准输入设备读取数据。
语法:
grep [选项参数][范本样式][文件或目录...]
选项值:
-a 或 –text
- 不要忽略二进制的数据。
-A<显示行数> 或 –after-context=<显示行数>
- 除了显示符合范本样式的那一行之外,并显示该行之后的内容。
-b 或 –byte-offset
- 可以打印出匹配出现在行中的偏移。字符在行中的偏移是从0开始计数,不是1。
-B<显示行数> 或 –before-context=<显示行数>
- 除了显示符合样式的那一行之外,并显示该行之前的内容。
-c 或 –count
- 计算符合样式的行数。需要注意的是-c只是统计匹配行的数量,并不是匹配的次数
-C<显示行数> 或 –context=<显示行数>或-<显示行数>
- 除了显示符合样式的那一行之外,并显示该行之前和之后的内容。
-d <动作> 或 –directories=<动作>
- 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep指令将回报信息并停止动作。
-e<范本样式> 或 –regexp=<范本样式>
- 指定字符串做为查找文件内容的样式。可以指定多个匹配模式。
-E 或 –extended-regexp
- 将样式为延伸的普通表示法来使用。grep命令默认使用基础正则表达式。这是先前描述的正则表达式的一个子集。选项-E可以使grep使用扩展正则表达式。也可以使用默认启用扩展正则表达式的egrep命令。
-f<规则文件> 或 –file=<规则文件>
- 指定规则文件,其内容含有一个或多个规则样式,让grep查找符合规则条件的文件内容,格式为每行一个规则样式。
-F 或 –fixed-regexp
- 将样式视为固定字符串的列表。
-G 或 –basic-regexp
- 将样式视为普通的表示法来使用。
-h 或 –no-filename
- 在显示符合样式的那一行之前,不标示该行所属的文件名称。
-H 或 –with-filename
- 在显示符合样式的那一行之前,表示该行所属的文件名称。
-i 或 –ignore-case
- 忽略字符大小写的差别。
-l 或 –file-with-matches
- 列出文件内容符合指定的样式的文件名称。
-L 或 –files-without-match
- 列出文件内容不符合指定的样式的文件名称。
-n 或 –line-number
- 在显示符合样式的那一行之前,标示出该行的列数编号。
-o 或 –only-matching
- 只显示匹配PATTERN 部分。
-q 或 –quiet或–silent
- 不显示任何信息。
-r 或 –recursive
- 此参数的效果和指定”-d recurse”参数相同。
-s 或 –no-messages
- 不显示错误信息。
-v 或 –revert-match
- 显示不包含匹配文本的所有行。
-V 或 –version
- 显示版本信息。
-w 或 –word-regexp
- 只显示全字符合的列。
-x –line-regexp
- 只显示全列符合的列。
-y
- 此参数的效果和指定”-i”参数相同。
–color
- 在输出行中着重标记出匹配到的模式,一般为–color=auto。
–include
- 在搜索过程中使用通配符指定(include)某些文件
–exclude
- 在搜索过程中使用通配符排除(exclude)某些文件
–exclude-dir
- 在搜索过程中使用通配符以排除目录
代码示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84//在当前目录中,查找有 file 字样的文件中包含 test 字符串的文件,并打印出该字符串的行。
$ grep test *file*
> file1:This a Linux testfile! #列出file1 文件中包含test字符的行
> file_2:This is a linux testfile! #列出file_2 文件中包含test字符的行
> file_2:Linux test #列出file_2 文件中包含test字符的行
//以递归的方式查找符合条件的文件。
//例如,查找指定目录/etc/acpi 及其子目录(如果存在子目录的话)下所有文件中包含字符串"update"的文件
//并打印出该字符串所在行的内容
$ grep -r update /etc/acpi
> /etc/acpi/ac.d/85-anacron.sh:# (Things like the slocate updatedb cause a lot of IO.) Rather than
> /etc/acpi/resume.d/85-anacron.sh:# (Things like the slocate updatedb cause a lot of IO.) Rather than
> /etc/acpi/events/thinkpad-cmos: action=/usr/sbin/thinkpad-keys--update
//反向查找。前面各个例子是查找并打印出符合条件的行,通过"-v"参数可以打印出不符合条件行的内容。
//查找文件名中包含 file 的文件中不包含test 的行,
$ grep -v test *file*
//在stdin中搜索匹配特定模式的文本行
$ $ echo -e "this is a word \n next line" | grep word
> this is a word
//使用扩展正则,只输出匹配到的文本,
$ echo this is a line. | grep -o -E "[a-z]+\."
> line
//统计出匹配模式的文本行数,-c只是统计匹配行的数量,并不是匹配的次数
$ grep -c "text" filename
> 10
//统计文件中匹配项的数量,可以使用下面的技巧
$ echo -e "1 2 3 4\nhello\n5 6" | egrep -o "[0-9]" | wc -l
> 6
//打印多个文件包含Linux的行,输出行号
$ grep linux -n sample1.txt sample2.txt
> sample1.txt:2:linux is fun
> sample2.txt:2:planetlinux
//选项-b可以打印出匹配出现在行中的偏移。配合选项-o可以打印出匹配所在的字符或字节偏移
$ echo gnu is not unix | grep -b -o "not"
> 7:not
//列出匹配模式所在的文件
$ grep -l linux sample1.txt sample2.txt
> sample1.txt
> sample2.txt
//对当前目录中对文本进行递归搜索
$ grep "text" . -R -n
//在匹配模式时不考虑字符的大小写
$ echo hello world | grep -i "HELLO"
> hello
//使用-e指定多个匹配模式,打印出匹配任意一种模式的行,每个匹配对应一行输出。
$ echo this is a line of text | grep -o -e "this" -e "line"
> this
> line
//可以将多个模式定义在文件中。选项-f可以读取文件并使用其中的模式(一个模式一行)
$ cat pat_file
> hello
> cool
$ echo hello this is cool | grep -f pat_file
> hello this is cool
//使用--include选项在目录中递归搜索所有的 .c和 .cpp文件。
//注意,some{string1,string2,string3}会被扩展成somestring1 somestring2 somestring3。
$ grep "main()" . -r --include *.{c,cpp}
>
//使用选项--exclude在搜索过程中排除所有的README文件
$ grep "main()" . -r --exclude "README"
>
//选项--exclude-dir可以排除目录:
$ grep main . -r -exclude-dir CVS
>
//grep的静默输出。可以通过设置grep的静默选项(-q)来实现。
//在静默模式中,grep命令不会输出任何内容。它仅是运行命令,然后根据命令执行成功与否返回退出状态。
//0表示匹配成功,非0表示匹配失败。
$ grep -q word file
H
head-打印文件的前n行
简介:
head命令用于显示文件的开头的内容。在默认情况下,head命令显示文件的头10行内容。
语法:
head [选项] fileName
选项值:
-n<数字>
- 指定显示头部内容的行数,负数时表示倒数n行
-c<字符数>
- 指定显示头部内容的字符数;
-v
- 总是显示文件名的头信息;
-q
- 不显示文件名的头信息。
代码示例
1
2
3
4
5
6
7//显示 test.log 文件中前 20 行
$ head -n 20 test.log
//显示 test.log 文件中前 20 字节
$ head -c 20 test.log
//显示 test.log 文件中除了最后20行之外的所有行
$ head -n -20 test.log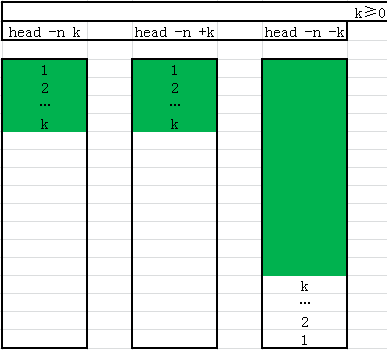
I
ifconfig——配置和展示网络信息
简介:
ifconfig可设置网络设备的状态,或是显示目前的设置。注意和Windows的命令ipconfig区分。
语法:
ifconfig [选项参数]
选项值:
add<地址>
- 设置网络设备IPv6的IP地址。
del<地址>
- 删除网络设备IPv6的IP地址。
down
- 关闭指定的网络设备。
<hw<网络设备类型><硬件地址>
- 设置网络设备的类型与硬件地址。
io_addr<I/O地址>
- 设置网络设备的I/O地址。
irq<IRQ地址>
- 设置网络设备的IRQ。
media<网络媒介类型>
- 设置网络设备的媒介类型。
mem_start<内存地址>
- 设置网络设备在主内存所占用的起始地址。
metric<数目>
- 指定在计算数据包的转送次数时,所要加上的数目。
mtu<字节>
- 设置网络设备的MTU。
netmask<子网掩码>
- 设置网络设备的子网掩码。
tunnel<地址>
- 建立IPv4与IPv6之间的隧道通信地址。
up
- 启动指定的网络设备。
-broadcast<地址>
- 将要送往指定地址的数据包当成广播数据包来处理。
-pointopoint<地址>
- 与指定地址的网络设备建立直接连线,此模式具有保密功能。
-promisc
- 关闭或启动指定网络设备的promiscuous模式。
[IP地址]
- 指定网络设备的IP地址。
[网络设备]
- 指定网络设备的名称。
代码示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14//显示网络设备信息,ifconfig输出的最左边一列是网络接口名,右边的若干列显示对应的网络接口的详细信息。
$ ifconfig
> eth0 Link encap:Ethernet HWaddr 00:50:56:0A:0B:0C
> .....以下省略
//ifconfig会显示系统中所有活动网络接口的详细信息。不过,我们可以限制它只显示某个特定接口的信息
$ ifconfig wlan0
> wlan0 Link encap:EthernetHWaddr 00:1c:bf:87:25:d2
//设置网络接口的IP地址
$ ifconfig wlan0 192.168.0.80
//设置此IP地址的子网掩码
$ ifconfig wlan0 192.168.0.80 netmask 255.255.252.0注意事项
J
K
L
less——对文件或其它输出进行分页显示
简介:
- 对文件或其它输出进行分页显示。缓冲加载。
- less 与 more 类似,但使用 less 可以随意浏览文件,而 more 仅能向前移动,却不能向后移动,而且 less 在查看之前不会加载整个文件。
语法:
less [参数] 文件
选项值:
-e
- 当文件显示结束后,自动离开
-f
- 强迫打开特殊文件,例如外围设备代号、目录和二进制文件
-g
- 只标志最后搜索的关键词
-i
- 忽略搜索时的大小写
-m
- 显示类似more命令的百分比
-N
- 显示每行的行号
-Q
- 不使用警告音
-s
- 显示连续空行为一行
-S
- 行过长时间将超出部分舍弃
快捷键
/<字符串>
- 向下搜索”字符串”的功能
?<字符串>
- 向上搜索”字符串”的功能
n
- 针对 / 或 ?的结果,重复前一个搜索
N
- 针对 / 或 ?的结果,反向重复前一个搜索
b
- 向后翻一页
d
- 向后翻半页
h
- 显示帮助界面
u
- 向前滚动半页
y
- 向前滚动一行
空格键
- 滚动一页
回车键
- 滚动一行
q / ZZ
- 退出 less 命令
v
- 使用配置的编辑器编辑当前文件
- 对于提示的^X等操作,^X即为CTRL+X。
h
- 显示 less 的帮助文档
F
- 类似 tail -f 的效果,读取写入文件的最新内容, 按 ctrl+C 停止。
&
- 开启模式匹配模式,可继续键入正则匹配,使得less仅显示匹配模式的行,而不是整个文件
m
- mark的意思,开启mark模式,让你键入一个字符,比如我们键入了a,那么less会使用 a 标记文本的当前位置。当使用 less 查看大文件时,可以在任何一个位置作标记,可以通过命令导航到标有特定标记的文本位置
‘
- 单引号,开启goto mark模式,让你键入一个字符,到达你键入字符标记的位置,比如你键入啊,那么导航到你标记的 a 处
代码示例
1
2
3
4
5
6
7
8
9
10
11//查看文件
$ less log.log
//ps查看进程信息并通过less分页显示
$ ps -ef |less
//查看命令历史使用记录并通过less分页显示
$ history | less
//浏览多个文件,输入 ":n" (n=next) 后,切换到 log2.log;输入":p" (p=preview)后,切换到log1.log
$ less log1.log log2.log
ls———显示指定工作目录下之内容
简介:
Linux ls命令用于显示指定工作目录下之内容(列出目前工作目录所含之文件及子目录)。它是list的简写。
语法:
ls [选项参数] [name...]
选项值:
-a
- 显示所有文件及目录(ls内定将文件名或目录名称开头为”.”的视为隐藏档,不会列出)
-l
- 除文件名称外,亦将文件型态、权限、拥有者、文件大小等资讯详细列出
-r
- 将文件以相反次序显示(原定依英文字母次序)
-t
- 将文件依建立时间之先后次序列出
-A
- 同-a,但不列出”.”(目前目录)及”..”(父目录)
-R
- 若目录下有文件,则以下之文件亦皆依序列出
代码示例
1
2
3
4
5
6
7
8//列出目前工作目录下所有名称是 s 开头的文件,越新的排越后面
$ ls -ltr s*
//将 /bin 目录以下所有目录及文件详细资料列出
$ ls -lR /bin
//列出目前工作目录下所有文件及目录;目录于名称后加 "/", 可执行档于名称后加 "*"
$ ls -AF
M
N
O
P
paste——合并文件的列
简介:
paste指令会把每个文件以列对列的方式,一列列地加以合并。
语法:
paste [选项参数][文件...]
选项值:
-d<间隔字符>或–delimiters=<间隔字符>
- 用指定的间隔字符取代跳格字符。
-s或–serial
- 串列进行而非平行处理。
–help
- 在线帮助。
–version
- 显示帮助信息。
代码示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33//合并file1.txt 和file2.txt,先看看这两个文件的内容
$ cat file1.txt
> 1
> 2
> 3
> 4
> 5
$ cat file2.txt
> slynux
> gnu
> bash
> hack
//使用paste合并
$ paste file1.txt file2.txt
> 1 slynux
> 2 gnu
> 3 bash
> 4 hack
> 5
//默认的分隔符是制表符,也可以用-d指定分隔符
$ paste file1.txt file2.txt -d ","
> 1,slynux
> 2,gnu
> 3,bash
> 4,hack
> 5,
//若使用paste指令的参数"-s",则可以将一个文件中的多行数据合并为一行进行显示。
//例如,将文件"file"中的3行数据合并为一行数据进行显示,输入如下命令
$ paste -s file
> xiongdan 200 lihaihui 233 lymlrl 231注意事项
参数”-s”只是将testfile文件的内容调整显示方式,并不会改变原文件的内容格式。
printf-打印内容
简介:
- printf命令接受引用文本或由空格分隔的参数。我们可以在printf中使用格式化字符串来指定字符串的宽度、左右对齐方式等。
代码示例
1
2
3
4
5
6
7
8
9printf "%-5s %-10s %-4s\n" No Name Mark ;
- printf "%-5s %-10s %-4.2f\n" 1 Sarath 80.3456 11 ;
- printf "%-5s %-10s %-4.2f\n" 2 James 90.9989 ;
- printf "%-5s %-10s %-4.2f\n" 3 Jeff 77.564
No Name Mark
1 Sarath 80.35
2 James 91.00 14
3 Jeff 77.56注意事项
%s、%c、%d和%f都是格式替换符(format substitution character),它们定义了该如何打印后续参数。%-5s指明了一个格式为左对齐且宽度为5的字符串替换(-表示左对齐)。如果不指明-,字符串就采用右对齐形式。
宽度指定了保留给某个字符串的字符数量。对Name而言,其保留宽度是10。因此,任何Name字段的内容都会被显示在10字符宽的保留区域内,如果内容不足10个字符,余下的则以空格填充。
对于浮点数,可以使用其他参数对小数部分进行舍入(round off)。 对于Mark字段,我们将其格式化为%-4.2f,其中.2指定保留两位小数。注意,在每行的格式字符串后都有一个换行符(\n)。
Q
R
read-从键盘或标准输入中读取文本
简介:
我们可以使用read以交互的形式读取用户输入,不过read能做的可远不止这些。编程语言的大多数输入库都是从键盘读取输入,当回车键按下的时候,标志着输入完毕。
但有时候是没法按回车键的,输入结束与否是由读取到的字符数或某个特定字符来决定的。例如在交互式游戏中,当按下 + 键时,小球就会向上移动。那么若每次都要按下 + 键,然后再按回车键来确认已经按过 + 键,这就显然太低效了。
read命令提供了一种不需要按回车键就能够搞定这个任务的方法。
语法:
read [-ers] [-a aname] [-d delim] [-i text] [-n nchars] [-N nchars] [-p prompt] [-t timeout] [-u fd] [name ...]
选项值:
- -a
后跟一个变量,该变量会被认为是个数组,然后给其赋值,默认是以空格为分割符。
-d
- 用特定的定界符delim_char作为输入行的结束,结果存入var变量(不包括边界符):
read -d delim_char var1
2
3
4
5$ read -d ":" var
$ hello:
$ echo $var
> hello
- 用特定的定界符delim_char作为输入行的结束,结果存入var变量(不包括边界符):
-p
- 后面跟提示信息,即在输入前打印提示信息。
1
2
3
4#!/bin/bash
read -p "输入网站名:" website
echo "你输入的网站名是 $website"
exit 01
2$ 输入网站名:www.cherish.com
> 你输入的网站名是 www.cherish.com1
- 后面跟提示信息,即在输入前打印提示信息。
-e
- 在输入的时候可以使用命令补全功能。
1
2
3
4
5//以下实例输入字符 a 后按下 Tab 键就会输出相关的文件名(该目录存在的):
$ read -e -p "输入文件名:" str
$ 输入文件名:a
a.out a.py a.pyc abc.txt
> 输入文件名:a1
- 在输入的时候可以使用命令补全功能。
-n
- 后跟一个数字,定义输入文本的长度,很实用。
例如:下面的语句从输入中读取n个字符并存入变量variable_name:read -n number_of_chars variable_name1
2
3
4#!/bin/bash
read -n 2 -p "请随便输入两个字符: " any
echo "\n您输入的两个字符是:$any"
exit 01
2$ 请随便输入两个字符: 12
> 您输入的两个字符是:121
- 后跟一个数字,定义输入文本的长度,很实用。
-s
安静模式,在输入字符时不再屏幕上显示,例如login时输入密码。
-t
后面跟秒数,定义输入字符的等待时间。
1
2
3
4
5
6
7
8#!/bin/bash
if read -t 5 -p "输入网站名:" website
then
echo "你输入的网站名是 $website"
else
echo "\n抱歉,你输入超时了。"
fi
exit 01
2//执行程序不输入,等待 5 秒后:
$ 输入网站名:抱歉,你输入超时了
1
-u
- 后面跟fd,从文件描述符中读入,该文件描述符可以是exec新开启的。
注意事项
代码示例
1
2
3
4
5
6
7
8#!/bin/bash
#这里默认会换行
echo "输入网站名: "
#读取从键盘的输入
read website
echo "你输入的网站名是 $website"
exit 0 #退出1
2
3
4
5//常规用法
$ ./testcat.sh
> 输入网站名:
$ www.baidu.com
> 你输入的网站名是 www.baidu.com
rm-删除一个文件或者目录
简介:
rm [options] filename…
语法:
Linux rm命令用于删除一个文件或者目录。
选项值:
-i
- 删除前逐一询问确认。
-f
- 即使原档案属性设为只读,亦直接删除,无需逐一确认。
-r
- 将目录及以下之档案逐一删除。
代码示例
1
2
3
4//删除文件可以直接使用rm命令,若删除目录则必须配合选项"-r"
$ rm test.txt
//删除当前目录下的所有文件及目录
$ rm -r *注意事项
文件一旦通过rm命令删除,则无法恢复,所以必须格外小心地使用该命令。
rsync——数据远程同步工具
简介:
- rsync命令广泛用于网络文件复制以及备份。
- rsync可以在最小化数据传输量同时,同步不同位置上的文件和目录。
- 相较于cp命令,rsync的优势在于比较文件修改日期,仅复制较新的文件。另外,它还支持远程数据传输以及压缩和加密。
语法:
rsync [选项参数] [源文件路径] [目标文件路径]
选项值:
-a
- 进行归档操作
-v
- 表示在stdout上打印出细节信息或进度
-z
- 指定在传输时压缩数据
-r
- 强制rsync以递归方式复制目录中所有的内容
–exclude
- 指定不需要传输的文件,可以使用通配符指定需要排除的文件
$ rsync -avz /home/code/app /mnt/disk/backup/code --exclude "*.o"
–exclude-from
- 我们也可以通过一个列表文件指定需要排除的文件
$ rsync -avz /home/code/app /mnt/disk/backup/code --exclude-from FILEPATH
–delete
- 在更新rsync备份时,删除不存在的文件。默认情况下,rsync并不会在目的端删除那些在源端已不存在的文件。如果要删除这类文件,可以使用rsync的–delete选项:
代码示例
1
2
3
4
5
6
7
8
9
10
11
12//将源目录(本地路径)复制到目的路径(远程路径)
$ rsync -av /home/slynux/data slynux@192.168.0.6:/home/backups/data
// 上面的命令会以递归的方式将所有的文件从源路径复制到目的路径。源路径和目的路径既可以是远程路径,也可以是本地路径。
//以将远程主机上的数据恢复到本地
$ rsync -av slynux@192.168.0.6:/home/backups/data /home/slynux/data
//将一个目录中的内容同步到另一个目录,这条命令将源目录(/home/test)中的内容(不包括目录本身)复制到现有的backups目录中。
$ rsync -av /home/test/ /home/backups
//将包括目录本身在内的内容复制到另一个目录中,将包括源目录本身(/home/test)在内的内容复制到新的backups目录中
$ rsync -av /home/test /home/backups注意事项
rsync命令用SSH连接远程主机,因此必须使用username@host:PATH 这种形式设定远程主机的地址,其中user代表用户名,host代表远程主机的IP地址或主机名。而PATH指定了远程主机中待复制数据所在的路径。
S
scp——安全复制工具
简介:
- SCP是一个安全的文件复制命令,和旧式的、不安全的远程复制命令rcp类似。文件均通过SSH加密通道进行传输。
- 因为是基于ssh,远程地址格式同样为
username@host:/path
语法:
scp [选项参数] [源文件路径] [目标文件路径]
选项值:
-oPort=PORTNO
- SSH服务器有时候并不在默认的端口22上运行。如果它在其他端口运行,我们可以在scp中用选项-oPort=PORTNO来指定端口号。
-1
- 强制scp命令使用协议ssh1
-2
- 强制scp命令使用协议ssh2
-4
- 强制scp命令只使用IPv4寻址
-6
- 强制scp命令只使用IPv6寻址
-B
- 使用批处理模式(传输过程中不询问传输口令或短语)
-C
- 允许压缩。(将-C标志传递给ssh,从而打开压缩功能)
-p
- 保留原文件的修改时间,访问时间和访问权限。
-q
- 不显示传输进度条。
-r
- 递归复制整个目录。
-v
- 详细方式显示输出。scp和ssh(1)会显示出整个过程的调试信息。这些信息用于调试连接,验证和配置问题。
-c cipher
- 以cipher将数据传输进行加密,这个选项将直接传递给ssh。
-F ssh_config
- 指定一个替代的ssh配置文件,此参数直接传递给ssh。
-i identity_file
- 从指定文件中读取传输时使用的密钥文件,此参数直接传递给ssh。
-l limit
- 限定用户所能使用的带宽,以Kbit/s为单位。
-o ssh_option
- 如果习惯于使用ssh_config(5)中的参数传递方式,
-P port
- 注意是大写的P, port是指定数据传输用到的端口号
-S program
- 指定加密传输时所使用的程序。此程序必须能够理解ssh(1)的选项。
代码示例
1
2//将远程主机中的文件复制到当前目录并使用给定的文件名
$ scp user@remotehost:/home/path/filename filename注意事项
sed——对文本进行编辑
简介:
sed是stream editor(流编辑器)的缩写。sed 可依照脚本的指令来处理、编辑文本文件。主要用来自动编辑一个或多个文件、简化对文件的反复操作、编写转换程序等。
语法:
sed [选项参数][文本文件]
选项值:
-e
或–expression= 以选项中指定的action动作来处理输入的文本文件。-e可省略,sed默认为该模式
action动作包括:
- a :新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)~
- c :取代行, c 的后面可以接字串,这些字串可以取代指定的行!
- d :删除,因为是删除啊,所以 d 后面通常不接任何字符
- i :插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);
- p :打印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行~
- s :取代部分数据,可以直接进行取代的工作!通常s的动作可以搭配正规表示法!例如 1,20s/old/new/g
注意动作符号后面,需要使用\符号分隔开动作与字符
-f<script文件>或–file=<script文件>
以选项中指定的script文件(文件内容为action)来处理输入的文本文件。
-h或–help
显示帮助。
-n或–quiet或–silent
仅显示script处理后的结果。
-V或–version
- 显示版本信息。
-i
- in place的意思,在参数为文件时,选项-i会使得sed用修改后的数据替换原始文件,相当于直接修改文件
$ sed -i 's/text/replace/' file
直接修改文件十分危险,我们可以使用如下命令,这时的sed不仅替换文件内容,还会创建一个名为file.bak的文件,其中包含着原始文件内容的副本。sed -i.bak 's/text/replace/' file
- in place的意思,在参数为文件时,选项-i会使得sed用修改后的数据替换原始文件,相当于直接修改文件
代码示例
a 添加
1
2
3
4
5
6
7
8
9
10
11//在testfile文件的第一行后添加一行,并将结果输出到标准输出
$ cat testfile #查看testfile 中的内容
> HELLO LINUX!
> Linux is a free unix-type opterating system.
$ sed -e 1a\newLine testfile
或
$ sed -e '1a newLine' testfile
> HELLO LINUX! #testfile文件原有的内容
> newline
> Linux is a free unix-type opterating system.d 添加
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24//将 /etc/passwd 的内容列出,同时,请将第 2~5 行删除!(nl命令,给文本内容添加行号)
$ nl /etc/passwd | sed '2,5d'
> 1 root:x:0:0:root:/root:/bin/bash
> 6 sync:x:5:0:sync:/sbin:/bin/sync
> 7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
> .....(后面省略).....
//将 /etc/passwd 的内容列出,同时,请将第 2 行删除!
$ nl /etc/passwd | sed '2d'
//将 /etc/passwd 的内容列出,同时,要删除第 3 到最后一行
$ nl /etc/passwd | sed '3,$d'
//将 /etc/passwd 的内容列出,要在第二行前加上drink tea
$ cat /etc/passwd | sed '2i drink tea'
//删除/etc/passwd所有包含root的行,其他行输出
$ nl /etc/passwd | sed '/root/d'
> 2 daemon:x:1:1:daemon:/usr/sbin:/bin/sh
> 3 bin:x:2:2:bin:/bin:/bin/sh
> ....下面忽略,第一行的匹配root已经删除了
//删除空行
$ sed '/^$/d' filec 替换
1
2
3
4
5
6//将第2-5行的内容取代成为No 2-5 number
$ nl /etc/passwd | sed '2,5c No 2-5 number'
> 1 root:x:0:0:root:/root:/bin/bash
> No 2-5 number
> 6 sync:x:5:0:sync:/sbin:/bin/sync
> .....(后面省略).....p 打印
1
2
3
4
5
6
7
8
9//仅列出 /etc/passwd 文件内的第 5-7 行
$ nl /etc/passwd | sed -n '5,7p'
> 5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
> 6 sync:x:5:0:sync:/sbin:/bin/sync
> 7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
//搜索 /etc/passwd有root关键字的行
$ nl /etc/passwd | sed -n '/root/p'
> 1 root:x:0:0:root:/root:/bin/bashs 取代(语法:
sed 's/正则表达式/新的字串/')1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33//替换第一个出现的this
$ echo thisthisthisthis | sed 's/this/THIS/'
> THISthisthisthis
//g标记可以使sed执行全局替换。
$ echo thisthisthisthis | sed 's/this/THIS/g'
> THISTHISTHISTHIS
///#g标记可以使sed替换第N次起出现的匹配
$ echo thisthisthisthis | sed 's/this/THIS/2g'
> thisTHISTHISTHIS
$ echo thisthisthisthis | sed 's/this/THIS/3g'
> thisthisTHISTHIS
//g标记可以使sed执行全局替换。
$ echo thisthisthisthis | sed 's/this/THIS/g'
> THISTHISTHISTHIS
//搜索/etc/passwd,找到root对应的行,执行后面花括号中的一组命令。
//每个命令之间用分号分隔,这里把bash替换为blueshell,再输出这行
$ nl /etc/passwd | sed -n '/root/{s/bash/blueshell/;p;q}' #s为替换,p为打印,最后的q是退出。
> 1 root:x:0:0:root:/root:/bin/blueshell
//sed命令会将s之后的字符视为命令分隔符。这允许我们更改默认的分隔符/:
$ sed 's:text:replace:g' #此时分隔符是:
//如果作为分隔符的字符出现在模式中,必须使用\对其进行转义。\|是出现在模式中被转义的分隔符
$ sed 's|te\|xt|replace|g'
//在sed中,我们可以用&指代模式所匹配到的字符串,这样就能够在替换字符串时使用已匹配的内容
//在这个例子中,正则表达式\w\+匹配每一个单词,然后我们用[&]替换它。&对应于之前所匹配到的单词。
$ echo this is an example | sed 's/\w\+/[&]/g'
> [this] [is] [an] [example]
注意事项
可以利用管道组合多个sed命令,多个模式之间可以用分号分隔,或是使用选项-e PATTERN ;如下命令都是等价的:
sed 'expression' | sed 'expression'sed 'expression; expression'sed -e 'expression' -e 'expression'如果想在sed表达式中使用变量,双引号就能派上用场了。
$ text=hello
$ echo hello world | sed “s/$text/HELLO/“
HELLO world
set-调试执行命令
简介:
set命令能设置所使用shell的执行方式,可依照不同的需求来做设置。
语法:
set [+-abCdefhHklmnpPtuvx]
选项值:
-a
- 标示已修改的变量,以供输出至环境变量。
-b
- 使被中止的后台程序立刻回报执行状态。
-C
- 转向所产生的文件无法覆盖已存在的文件。
-d
- Shell预设会用杂凑表记忆使用过的指令,以加速指令的执行。使用-d参数可取消。
-e
- 若指令传回值不等于0,则立即退出shell。
-f
- 取消使用通配符。
-h
- 自动记录函数的所在位置。
-k
- 指令所给的参数都会被视为此指令的环境变量。
-l
- 记录for循环的变量名称。
-m
- 使用监视模式。
-n
- 只读取指令,而不实际执行。
-p
- 启动优先顺序模式。
-P
- 启动-P参数后,执行指令时,会以实际的文件或目录来取代符号连接。
-t
- 执行完随后的指令,即退出shell。
-u
- 当执行时使用到未定义过的变量,则显示错误信息。
-v
- 显示shell所读取的输入值。
-x
- 执行指令后,会先显示该指令及参数。
+<参数>
- 取消某个set曾启动的参数。
注意事项
+<参数>:取消某个set曾启动的参数。
set命令不带任何参数时,为打印所有环境变量
代码示例
1
2
3
4
5//执行指令后,会先显示该指令及参数。
$ #!/bin/bash
- #文件名: debug.sh
- for i in {1..2};
- doset -x
echo $i
- set +x
- done
- echo 1
1 - set +x
- echo 2
2 - set +x
1
sftp——运行在SSH连接之上并模拟了FTP接口的文件传输系统
简介:
- 它不需要远端运行FTP服务器来进行文件传输,但必须要有SSH服务器。sftp是一个交互式命令,提供了命令提示符。
- sftp支持与ftp和lftp相同的命令。不赘述。
语法:
xxxxxxxxxxxxxxxxx
选项值:
- -oPort=PORTNO
- SSH服务器有时候并不在默认的端口22上运行。如果它在其他端口运行,我们可以在sftp中用选项-oPort=PORTNO来指定端口号。
$ sftp -oPort=422 user@slynux.org- -oPort应该作为sftp命令的第一个参数。
- -oPort=PORTNO
代码示例
1
2
3//启动sftp会话
$ sftp user@domainname
>注意事项
sleep-命令延迟一段时间执行。
简介:
Linux sleep命令可以用来将目前动作延迟一段时间。
语法:
sleep [--help] [--version] number[smhd]
选项值:
–help
- 显示辅助讯息
–version
- 显示版本编号
number
- 时间长度,后面可接 s、m、h 或 d。其中 s 为秒,m 为 分钟,h 为小时,d 为日数
代码示例
1
2//显示目前时间后延迟 1 分钟,之后再次显示时间
$ date;sleep 1m;date
ssh——远程连接工具
简介:
- SSH代表的是Secure Shell(安全shell)。它使用加密隧道连接两台计算机。
- SSH能够让你访问远程计算机上的shell,从而在其上执行交互命令并接收结果,或是启动交互会话。
- GNU/Linux发布版中默认并不包含SSH,需要使用软件包管理器安装openssh-server和openssh-client。SSH服务默认运行在端口22之上。
语法:
ssh [选项参数] [user@]hostname] [command]
选项值:
-p <端口号>
- SSH服务器默认在端口22上运行。但有些SSH服务器并没有使用这个端口。针对这种情况,可以用ssh命令的-p <端口号>来指定端口
ssh user@locahost -p 422
- -C
- SSH协议也支持对数据进行压缩传输。当带宽有限时,这一功能很方便。
ssh -C user@hostname COMMANDS
代码示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20//连接运行了SSH服务器的远程主机
$ ssh mec@192.168.0.1
//mec是远程主机上的用户,192.168.0.1是IP地址,这里也可以是域名
//SSH会询问用户密码,一旦认证成功,就会连接到远程主机上的登录shell
//在远程执行命令whoami
$ ssh mec@192.168.0.1 'whoami'
> mec
//可以输入多条命令,命令之间用分号分隔
$ ssh mec@192.168.0.1 "echo user: $(whoami);echo OS: $(uname)"
> user: mec
> OS: Linux
//将数据重定向至远程shell命令的stdin
$ echo 'text' | ssh user@remote_host 'echo'
> text
//将本地主机上的tar存档文件传给远程主机
$ > tar -czf - LOCALFOLDER | ssh 'tar -xzvf-'注意事项
T
tar——归档或者压缩,解压文件
简介:
tar命令可以归档文件。它最初是设计用来将数据存储在磁带上,因此其名字也来源于TapeARchive。tar可以将多个文件和文件夹打包为单个文件,同时还能保留所有的文件属性,如所有者、权限等。
语法:
tar [选项参数]
选项值:
-A或–catenate
- 新增文件到已存在的备份文件。
-b<区块数目>或–blocking-factor=<区块数目>
- 设置每笔记录的区块数目,每个区块大小为12Bytes。
-B或–read-full-records
- 读取数据时重设区块大小。
-c或–create
- 建立新的备份文件。
-C<目的目录>或–directory=<目的目录>
- 切换到指定的目录。
-d或–diff或–compare
- 对比备份文件内和文件系统上的文件的差异。
-f<备份文件>或–file=<备份文件>
- 指定备份文件。
-F<Script文件>或–info-script=<Script文件>
- 每次更换磁带时,就执行指定的Script文件。
-g或–listed-incremental
- 处理GNU格式的大量备份。
-G或–incremental
- 处理旧的GNU格式的大量备份。
-h或–dereference
- 不建立符号连接,直接复制该连接所指向的原始文件。
-i或–ignore-zeros
- 忽略备份文件中的0 Byte区块,也就是EOF。
-k或–keep-old-files
- 解开备份文件时,不覆盖已有的文件。
-K<文件>或–starting-file=<文件>
- 从指定的文件开始还原。
-l或–one-file-system
- 复制的文件或目录存放的文件系统,必须与tar指令执行时所处的文件系统相同,否则不予复制。
-m或–modification-time
- 还原文件时,不变更文件的更改时间。
-M或–multi-volume
- 在建立,还原备份文件或列出其中的内容时,采用多卷册模式。
-N<日期格式>或–newer=<日期时间>
- 只将较指定日期更新的文件保存到备份文件里。
-o或–old-archive或–portability
- 将资料写入备份文件时使用V7格式。
-O或–stdout
- 把从备份文件里还原的文件输出到标准输出设备。
-p或–same-permissions
- 用原来的文件权限还原文件。
-P或–absolute-names
- 文件名使用绝对名称,不移除文件名称前的”/“号。
-r或–append
- 新增文件到已存在的备份文件的结尾部分。
-R或–block-number
- 列出每个信息在备份文件中的区块编号。
-s或–same-order
- 还原文件的顺序和备份文件内的存放顺序相同。
-S或–sparse
- 倘若一个文件内含大量的连续0字节,则将此文件存成稀疏文件。
-t或–list
- 列出备份文件的内容。
-T<范本文件>或–files-from=<范本文件>
- 指定范本文件,其内含有一个或多个范本样式,让tar解开或建立符合设置条件的文件。
-u或–update
仅置换较备份文件内的文件更新的文件。追加选项(-r)可以将指定的任意文件加入到归档文件中。如果同名文件已经存在,那么归档文件中就会包含两个名字一样的文件。我们可以用更新选项-u指明:只添加比归档文件中的同
名文件更新(newer)的文件。$ tar -uf archive.tar filea#如果两个filea的时间戳相同,则什么都不会发生。
-U或–unlink-first
- 解开压缩文件还原文件之前,先解除文件的连接。
-v或–verbose
- 显示指令执行过程。
-V<卷册名称>或–label=<卷册名称>
- 建立使用指定的卷册名称的备份文件。
-w或–interactive
- 遭遇问题时先询问用户。
-W或–verify
- 写入备份文件后,确认文件正确无误。
-x或–extract或–get
- 从备份文件中还原文件。
-X<范本文件>或–exclude-from=<范本文件>
- 指定范本文件,其内含有一个或多个范本样式,让ar排除符合设置条件的文件。
-z或–gzip或–ungzip
- 通过gzip指令处理备份文件。
-Z或–compress或–uncompress
- 通过compress指令处理备份文件。
-<设备编号><存储密度>
- 设置备份用的外围设备编号及存放数据的密度。
–after-date=<日期时间>
- 此参数的效果和指定”-N”参数相同。
–atime-preserve
- 不变更文件的存取时间。
–backup=<备份方式>或–backup
- 移除文件前先进行备份。
–checkpoint
- 读取备份文件时列出目录名称。
–concatenate
- 此参数的效果和指定”-A”参数相同。
–confirmation
- 此参数的效果和指定”-w”参数相同。
–delete
- 从备份文件中删除指定的文件。
–exclude=<范本样式>
- 排除符合范本样式的文件。
–group=<群组名称>
- 把加入设备文件中的文件的所属群组设成指定的群组。
–help
- 在线帮助。
–ignore-failed-read
- 忽略数据读取错误,不中断程序的执行。
–new-volume-script=<Script文件>
- 此参数的效果和指定”-F”参数相同。
–newer-mtime
- 只保存更改过的文件。
–no-recursion
- 不做递归处理,也就是指定目录下的所有文件及子目录不予处理。
–null
- 从null设备读取文件名称。
–numeric-owner
- 以用户识别码及群组识别码取代用户名称和群组名称。
–owner=<用户名称>
- 把加入备份文件中的文件的拥有者设成指定的用户。
–posix
- 将数据写入备份文件时使用POSIX格式。
–preserve
- 此参数的效果和指定”-ps”参数相同。
–preserve-order
- 此参数的效果和指定”-A”参数相同。
–preserve-permissions
- 此参数的效果和指定”-p”参数相同。
–record-size=<区块数目>
- 此参数的效果和指定”-b”参数相同。
–recursive-unlink
- 解开压缩文件还原目录之前,先解除整个目录下所有文件的连接。
–remove-files
- 文件加入备份文件后,就将其删除。
–rsh-command=<执行指令>
- 设置要在远端主机上执行的指令,以取代rsh指令。
–same-owner
- 尝试以相同的文件拥有者还原文件。
–suffix=<备份字尾字符串>
- 移除文件前先行备份。
–totals
- 备份文件建立后,列出文件大小。
–use-compress-program=<执行指令>
- 通过指定的指令处理备份文件。
–version
- 显示版本信息。
–volno-file=<编号文件>
- 使用指定文件内的编号取代预设的卷册编号。
注意事项
tar命令默认只归档文件,并不对其进行压缩。不过tar支持用于压缩的相关选项。我们日常理解的tar能压缩,其实都并非其命令的本意。压缩能够显著减少文件的体积。
归档文件通常被压缩成下列格式之一。
gzip格式:file.tar.gz或file.tgz。
bzip2格式:file.tar.bz2。
Lempel-Ziv-Markov格式:file.tar.lzma。不同的tar选项可以用来指定不同的压缩格式
-j 指定bunzip2格式;
-z 指定gzip格式;
–lzma 指定lzma格式。不明确指定上面那些特定的选项也可以使用压缩功能。tar能够基于输出或输入文件的扩展名来进行压缩。为了让tar支持根据扩展名自动选择压缩算法,使用-a或–auto-compress选项
$ tar -acvf archive.tar.gz filea fileb filec代码示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60//归档文件,选项-c表示创建新的归档文件。选项-f表示归档文件名,该选项后面必须跟一个或多个文件
$ tar -cf output.tar file
$ $ tar -cf archive.tar file1 file2 file3 folder1
//列出归档文件内容
$ tar -tf archive.tar
> file1
> file2
//列出压缩文件内容,而且还要展示更多的细节,使用v选项表示冗长模式,vv为非常冗长模式;
$ tar -tvf archive.tar
> -rw-rw-r-- shaan/shaan 0 2013-04-08 21:34 file1
> -rw-rw-r-- shaan/shaan 0 2013-04-08 21:34 file2
// 向归档文件中追加文件,选项-r可以将新文件追加到已有的归档文件末尾
$ tar -tf archive.tar
> hello.txt
$ tar -rf archive.tar world.txt
$ tar -tf archive.tar
> hello.txt
> world.txt
//提取文件,-x可以将归档文件的内容提取到当前目录
$ tar -xf archive.tar
//解压文件
$ tar -xzf archive.tar
//我们也可以用选项-C来指定将文件提取到哪个目录:
$ tar -xf archive.tar -C /path/to/extraction_directory
//上述命令将归档文件的内容提取到指定目录中。它提取的是归档文件中的全部内容。
//我们可以通过将文件名作为命令行参数来提取特定的文件,下述命令只提取file1和file4,忽略其他文件
$ tar -xvf file.tar file1 file4
//在归档时,我们可以将stdout指定为输出文件,这样另一个命令就可以通过管道来读取(作为stdin)并进行其他处理。
//当通过安全shell(Secure Shell,SSH)传输数据时,这招很管用。
$ tar cvf - files/ | ssh user@example.com "tar xv -C Documents/"
//在上面的例子中,对files目录中的内容进行了归档并将其输出到stdout(由-指明),然后提取到远程系统中的Documents目录中。
//我们可以用选项-A合并多个tar文件。
//假设我们现在有两个tar文件:file1.tar和file2.tar。下面的命令可以将file2.tar的内容合并到file1.tar中
$ tar -Af file1.tar file2.tar
//从归档中删除文件
$ tar -f archive.tar --delete file1 file2
或
$ tar --delete --file archive.tar [FILE LIST]
//在归档过程中排除部分文件
//选项--exclude [PATTERN]可以将匹配通配符模式的文件排除在归档过程之外。例如,排除所有的.txt文件
//注意,模式应该使用双引号来引用,避免shell对其进行扩展。
$ tar -cf arch.tar * --exclude "*.txt"
//可以配合选项-X将需要排除的文件列表放入文件中
$ cat list
> filea
> fileb
$ tar -cf arch.tar * -X list
//这样就把filea和fileb排除了。
tail–打印文件尾部内容
简介:
tail命令用于输入文件中的尾部内容。tail命令默认在屏幕上显示指定文件的末尾10行。如果给定的文件不止一个,则在显示的每个文件前面加一个文件名标题。如果没有指定文件或者文件名为“-”,则读取标准输入。
语法:
tail [选项][参数]
选项值:
–retry
- 即是在tail命令启动时,文件不可访问或者文件稍后变得不可访问,都始终尝试打开文件。使用此选项时需要与选项“——follow=name”连用;
-c
或–bytes=N - 输出文件尾部的N(N为整数)个字节内容;N值之前有一个”+”号,则从文件开头的第N项开始显示,而不是显示文件的最后N项。N值后面可以有后缀:b表示512,k表示1024,m表示1 048576(1M)。
-f <name/descriptor>或;–follow <name/descript>
- 显示文件最新追加的内容。“name”表示以文件名的方式监视文件的变化。“-f”与“-fdescriptor”等效;
-F
- 与选项“-follow=name”和“–retry”连用时功能相同;
-n
或–line=N - 输出文件的尾部N(N位数字)行内容。N值之前有一个”+”号,则从文件开头的第N项开始显示,而不是显示文件的最后N项。
–pid=<进程号>
- 与“-f”选项连用,当指定的进程号的进程终止后,自动退出tail命令;
-q或–quiet或–silent
- 当有多个文件参数时,不输出各个文件名;
-s<秒数>或–sleep-interal=<秒数>
- 与“-f”选项连用,指定监视文件变化时间隔的秒数;
-v或–verbose
- 当有多个文件参数时,总是输出各个文件名;
–help
- 显示指令的帮助信息;
–version
- 显示指令的版本信息。
代码示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14//显示文件file的最后10行
$ tail file
//显示文件file的内容,从第20行至文件末尾
$ tail +20 file
//显示文件file的最后10个字符
$ tail -c 10 file
//实时查看file追加的内容
$ tail -f file
//间隔五秒刷新file追加的内容
$ tail -f -s 5 file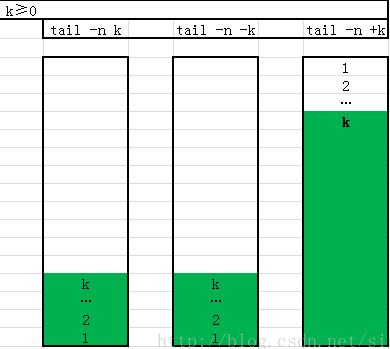
time-量测命令执行消耗的时间
简介:
Linux time命令的用途,在于量测特定指令执行时所需消耗的时间及系统资源等资讯。例如 CPU 时间、记忆体、输入输出等等。
语法:
time [options] COMMAND [arguments]
选项值:
-o 或 –output=FILE
- 设定结果输出档。这个选项会将 time 的输出写入 所指定的档案中。如果档案已经存在,系统将覆写其内容。
-a 或 –append
- 配合 -o 使用,会将结果写到档案的末端,而不会覆盖掉原来的内容。
-f
或 –format=FORMAT - 以 FORMAT 字串设定显示方式。当这个选项没有被设定的时候,会用系统预设的格式。不过你可以用环境变数 time 来设定这个格式,如此一来就不必每次登入系统都要设定一次。
代码示例
1
2
3
4
5
6
7
8//检测date命令运行时间和资源
$ time date
> real 0m0.136s
> user 0m0.010s
> sys 0m0.070s
//在以上实例中,执行命令"time date"。系统先执行命令"date",第2行为命令"date"的执行结果。
//第3-6行为执行命令"date"的时间统计结果,其中第4行"real"为实际时间,
//第5行"user"为用户CPU时间,第6行"sys"为系统CPU时间。以上三种时间的显示格式均为MMmNN[.FFF]s。
tr-转换或删除文件中的字符。
简介:
tr 可以对来自标准输入的内容进行字符替换、字符删除以及重复字符压缩,将结果输出到标准输出设备。tr是translate(转换)的简写,因为它可以将一组字符转换成另一组字符。
语法:
tr [选项参数][--help][--version][第一字符集][第二字符集] 或 tr [OPTION] SET1[SET2]来自stdin的输入字符会按照位置从set1映射到set2(set1中的第一个字符映射到set2中的第一个字符,以此类推),然后将输出写入stdout(标准输出)。
set1和set2是字符类或字符组。如果两个字符组的长度不相等,那么set2会不断复制其最后一个字符,直到长度与set1相同。如果set2的长度大于set1,那么在set2中超出set1长度的那部分字符则全部被忽略。
选项值:
-c, –complement
- 反选设定字符。也就是符合 SET1 的部份不做处理,不符合的剩余部份才进行转换
-d, –delete
- 删除指令字符
-s, –squeeze-repeats
- 缩减连续重复的字符成指定的单个字符
-t, –truncate-set1
- 削减 SET1 指定范围,使之与 SET2 设定长度相等
–help
- 显示程序用法信息
–version
- 显示程序本身的版本信息
字符集合的范围
\NNN
- 八进制值的字符 NNN (1 to 3 为八进制值的字符)
\a Ctrl-G
- 铃声
\b Ctrl-H
- 退格符
\f Ctrl-L
- 走行换页
\n Ctrl-J
- 新行
\r Ctrl-M
- 回车
\t Ctrl-I
- tab键
\v Ctrl-X
- 水平制表符
CHAR1-CHAR2
- 字符范围从 CHAR1 到 CHAR2 的指定,范围的指定以 ASCII 码的次序为基础,只能由小到大,不能由大到小。
‘ABD-}’、’aA.,’、’a-ce-x’以及’a-c0-9’等均是合法的集合。
定义集合也很简单,不需要书写一长串连续的字符序列,只需要使用“起始字符-终止字符”这种格式就行了。
- 字符范围从 CHAR1 到 CHAR2 的指定,范围的指定以 ASCII 码的次序为基础,只能由小到大,不能由大到小。
[CHAR*]
- 这是 SET2 专用的设定,功能是重复指定的字符到与 SET1 相同长度为止
[CHAR*REPEAT]
- 这也是 SET2 专用的设定,功能是重复指定的字符到设定的 REPEAT 次数为止(REPEAT 的数字采 8 进位制计算,以 0 为开始)
[:alnum:]
- 所有字母字符与数字
[:alpha:]
- 所有字母字符
[:blank:]
- 所有水平空格
[:cntrl:]
- 所有控制(非打印)字符
[:digit:]
- 所有数字
[:graph:]
- 所有可打印的字符(不包含空格符)
[:lower:]
- 所有小写字母
[:print:]
- 所有可打印的字符(包含空格符)
[:punct:]
- 所有标点字符
[:space:]
- 所有水平与垂直空格符
[:upper:]
- 所有大写字母
[:xdigit:]
- 所有 16 进位制的数字
代码示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37//文件testfile中的小写字母全部转换成大写字母,然后输出
$ cat testfile |tr a-z A-Z
或反过来
$ echo "HELLO WHO IS THIS" |tr [:upper:] [:lower:]
> hello who is this
//用tr进行数字加密和解密
//加密
$ echo 12345 | tr '0-9' '9876543210'
> 87654 # 已加密
//解密
$ echo 87654 | tr '9876543210' '0-9'
> 12345 # 已解密
//将制表符转换成单个空格
$ tr '\t' ' ' < file.txt
//用tr删除字符,语法上只使用set1,不使用set2
//将stdin中的数字删除并打印删除后的结果
$ echo "Hello 123 world 456" | tr -d '0-9'
>
//从输入文本中删除不在补集中的所有字符
$ echo hello 1 char 2 next 4 | tr -d -c '0-9 \n'
> 124
//将不在set1中的字符替换成空格
$ echo hello 1 char 2 next 4 | tr -c '0-9' ' '
> 1 2 4
//如果你习惯在点号后面放置两个空格,你需要在不删除重复字母的情况下去掉多余的空格(-s 缩减连续重复的字符成指定的单个字符)
$ echo "GNU is not UNIX. Recursive right ?" | tr -s ' '
> GNU is not UNIX. Recursive right ?
//文件中的数字进行相加,先删除字母,再将' '替换成+号,得到 $[ 1+2+3+4+5 ],$[ operation ]执行算术运算,得出结果
$ cat test.txt | tr -d [a-z] | echo "total: $[$(tr ' ' '+')]"注意事项
tr只能通过stdin(标准输入)接收输入(无法通过命令行参数接收)
U
V
W
which-查找并显示给定命令的绝对路径
简介:
环境变量PATH中保存了查找命令时需要遍历的目录。which指令会在环境变量$PATH设置的目录里查找符合条件的文件。也就是说,使用which命令,就可以看到某个系统命令是否存在,以及执行的到底是哪一个位置的命令。
语法:
which cmdName
选项值:
注意事项
which是根据使用者所配置的 PATH 变量内的目录去搜寻可运行档的!所以,不同的 PATH 配置内容所找到的命令当然不一样的!
cd 这种常用的命令找不到,因为 cd 是bash 内建的命令! 但是 which 默认是找 PATH 内所规范的目录,所以找不到的!
代码示例
1
2
3// 查找文件、显示命令路径
$ which pwd
> /bin/pwd
X
xargs-参数传递过滤器
简介:
- xargs 是给命令传递参数的一个过滤器,也是组合多个命令的一个工具。
- xargs 可以将管道或标准输入(stdin)数据转换成命令行参数,也能够从文件的输出中读取数据。
- xargs 也可以将单行或多行文本输入转换为其他格式,例如多行变单行,单行变多行。
- xargs 默认的命令是 echo,这意味着通过管道传递给 xargs 的输入将会包含换行和空白,不过通过 xargs 的处理,换行和空白将被空格取代。
- xargs 是一个强有力的命令,它能够捕获一个命令的输出,然后传递给另外一个命令。
- 之所以能用到这个命令,关键是由于很多命令不支持|管道来传递参数,而日常工作中有有这个必要,所以就有了 xargs 命令,例如:
1
2find /sbin -perm +700 |ls -l #这个命令是错误的
find /sbin -perm +700 |xargs ls -l #这样才是正确的
语法:
somecommand |xargs -item command
选项值:
-a file
- 从文件中读入作为sdtin
-e flag 或 -E flag
- flag必须是一个以空格分隔的标志,当xargs分析到含有flag这个标志的时候就停止。
-p
- 当每次执行一个argument的时候询问一次用户。
-n num
- 后面加次数,表示命令在执行的时候一次用的argument的个数,默认是用所有的。如果用在输出场景,那就是一行有n个
-t
- 表示先打印命令,然后再执行。
-i 或-I
- 可以用于指定替换字符串,这个字符串会在xargs解析输入时被参数替换掉。如 复制所有图片文件到/data/images 目录下:-I 指定替换符号是{},那么xargs每个输出,都会替换cp后面的{}
ls *.jpg | xargs -n1 -I {} cp {} /data/images
- 可以用于指定替换字符串,这个字符串会在xargs解析输入时被参数替换掉。如 复制所有图片文件到/data/images 目录下:-I 指定替换符号是{},那么xargs每个输出,都会替换cp后面的{}
-r no-run-if-empty
- 当xargs的输入为空的时候则停止xargs,不用再去执行了。
-s num
- 命令行的最大字符数,指的是 xargs 后面那个命令的最大命令行字符数。
-L num
- 从标准输入一次读取 num 行送给 command 命令。
-l
- 同 -L。
-d delim
- xargs对于输入的默认分隔符是空格,-d选项可以为输入数据指定自定义的分隔符
-x
- exit的意思,主要是配合-s使用。。
-P
- 修改最大的进程数,默认是1,为0时候为as many as it can
代码示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20//多行输入单行输出
$ cat test.txt
> a b c d e f g
> h i j k l m n
$ cat test.txt | xargs
> a b c d e f g h i j k l m n
//-n 选项多行输出,每行三个元素
$ cat test.txt | xargs -n 3
> a b c
> d e f
> g h i
//stdin中是一个包含了多个X字符的字符串。我们可以用–d选项将X定义为输入分隔符。
$ echo "splitXsplit2Xsplit3Xsplit4" | xargs -d X
> Split1 split2 split3 split4
//在系统中搜索.docx文件,这些文件名中通常会包含大写字母和空格。其中使用了grep找出内容中不包含image的文件
$ find /smbMount -iname '*.docx' -print0 | xargs -0 grep -L image注意事项
xargs 一般是和管道一起使用。
xargs命令可以同find命令很好地结合在一起。find的输出可以通过管道传给xargs,由后者执行-exec选项所无法处理的复杂操作。如果文件系统的有些文件名中包含空格,find命令的-print0选项可以使用0(NULL)来分隔查找到的元素,然后再用xargs对应的-0选项进行解析。
Y
Z
xxx
简介:
- xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
语法:
xxxxxxxxxxxxxxxxx
选项值:
代码示例
1
2
3//
$
>注意事项