前言
在了解Ratf算法前,我们需要了解如下的一些概念名词:
状态机复制 (State Machine Replication)
- 在分布式系统设计中,需要遵循CAP理论,如果我们要让一个服务具有容错能力,那么会让一个服务的多个副本同时运行在不同的节点上。此时,状态的改变就需要在各个副本之间做同步,实现这种同步方法就是所谓的状态机复制(State Machine Replication)。
- 状态机复制的理论基础是:如果集群里的每一个节点上都运行着相同的确定性状态机S,并且所有的状态机刚开始都处于同样的初始状态s0,那么给予这些状态机相同的输入序列: {i1, i2, i3, i4, i5, i6, …, in}, 这些状态机必然会经过相同的状态转换路径: s0->s1->s2->s3->…->sn最终达到相同的状态sn, 同时生成相同的输出序列 {o1(s1), o2(s2), o3(s3), …, on(sn)}。(典型的例子就是Redis的AOF和MySQL集群的binlog)
- 在执行输入序列I的过程中,根据同步方式的不同,系统就有了强一致性和最终一致性。如果我们要求对于序列I中的每一个in, 都需要所有的服务副本确认执行了in,才能执行in+1,那么这个系统就是强一致性的系统。如果我们取消掉这个限制,仅仅要求所有的服务副本执行相同的输入序列I,但是完全各自独立执行,而不需要在中间同步,那么就有了最终一致性(各服务都会达到相同的最终状态,但是达到的时间不确定)。
拜占庭将军问题
- 问题很简单,拜占庭帝国要攻打一个城池,兵分多路,城池很难攻下,要多路军队同时进攻才能攻下,为了完成目标,各路的将军需要通过信使来约定一个攻打的时间,而信使有可能死亡或者叛变(传递假消息)。
- 基于以上的问题,我们需要在行动时达成共识。互联网上,每台计算机都是一个个完全相等的节点,只能靠通信来协调,没有权威背书或信任,是一个急需解决的问题。
拜占庭将军问题的本质:如何让众多完全平等的节点针对某一状态达成共识。
Raft算法
拜占庭将军问题是分布式领域最复杂、最严格的容错模型。但在日常工作中使用的分布式系统面对的问题不会那么复杂,更多的是计算机故障挂掉了,或者网络通信问题而没法传递信息,这种情况不考虑计算机之间互相发送恶意信息,极大简化了系统对容错的要求,最主要的是达到一致性。
所以将拜占庭将军问题根据常见的工作上的问题进行简化:假设将军中没有叛军,信使的信息可靠但有可能被暗杀的情况下,将军们如何达成一致性决定?
对于这个简化后的问题,有许多解决方案,第一个被证明的共识算法是 Paxos,由拜占庭将军问题的作者 Leslie Lamport 在1990年提出,最初以论文难懂而出名,后来这哥们在2001重新发了一篇简单版的论文 Paxos Made Simple,然而还是挺难懂的。
因为 Paxos 难懂,难实现,所以斯坦福大学的教授在2014年发表了新的分布式协议 Raft。与 Paxos 相比,Raft 有着基本相同运行效率,但是更容易理解,也更容易被用在系统开发上。paxos见我的另一篇文章分布式一致性理论和paxos算法
Raft算法主要分为如下几个关键步骤:
- leader选举:
- Raft开始时在集群中选举出Leader负责日志复制的管理;
- 日志复制:
- Leader接受来自客户端的事务请求(日志),并将它们复制给集群的其他节点,然后负责通知集群中其他节点提交日志,Leader负责保证其他节点与他的日志同步。
- 故障转移:
- 当Leader宕掉后集群其他节点会发起选举选出新的Leader;
raft算法有如下特点:
- 强leader语义:
- 相比其他一致性算法,Raft使用增强形式的leader语义。举个例子,日志只能由leader复制给其它节点。这简化了日志复制需要的管理工作,使得Raft易于理解。
- leader的选择:
- Raft使用随机计时器来选择leader,它的实现只是在心跳机制(任何一致性算法中都必须实现)上多做了一点“文章”,不会增加延迟和复杂性。
- 关系改变:
- Raft使用了一个新机制joint consensus允许集群动态在线扩容,保障Raft的可持续服务能力。
1 Ratf名词速览
1.1 Raft节点状态
从拜占庭将军的故事映射到分布式系统上,每个将军相当于一个分布式网络节点,每个节点有三种状态:Follower(跟随者),Candidate(候选者),Leader(领导者),状态之间是互相转换的,可以参考下图,具体的后面说。

1.2 term任期
从上面可以看出,哪个节点做leader是大家投票选举出来的,每个leader工作一段时间,然后选出新的leader继续负责。这和民选社会的选举很像,每一届新的履职期称之为一届任期,在raft协议中,也是这样的,对应的术语叫term。
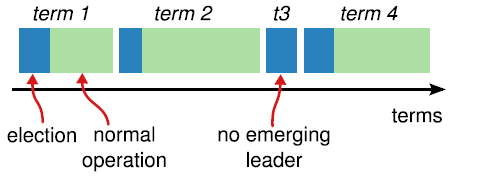
上图蓝色表示选举期,绿色表示履职期。
每个任期都有一个对应的整数与之关联,称为“任期号”,任期号用单词“Term”表示,这个值是一个严格递增的整数值。
如果一个candidate在一次选举中赢得leader,那么这个节点将在这个任期中担任leader的角色。但并不是每个任期都一定对应有一个leader的,比如上面的t3中,可能在选举超时到来之前都没有产生一个新的leader,那么此时将递增任期号开始一次新的选举。
2. Raft算法流程
2.1 leader选举
2.1.1 心跳机制
raft算法是使用心跳机制来触发leader选举的。
在节点刚开始启动时,初始状态是follower状态。一个follower状态的节点,只要一直收到来自leader或者candidate的正确RPC消息的话,将一直保持在follower状态。
leader节点通过周期性的发送心跳请求(一般使用带有空数据的AppendEntries RPC来进行心跳)来维持着leader节点状态。
2.1.2 选举超时(election timeout)
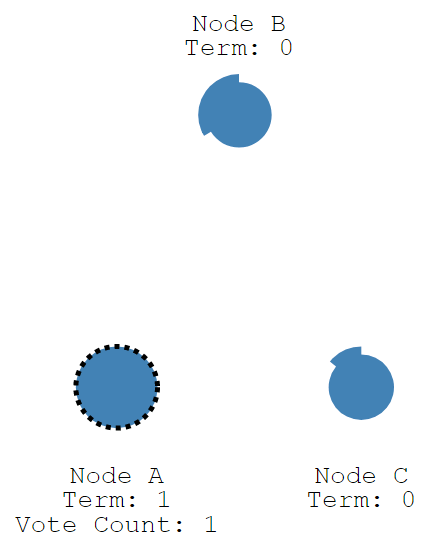
每个follower有一个选举超时(election timeout)定时器,这个定时器的值,对于每个节点都是不同的,其值在150ms到300ms之前随机。
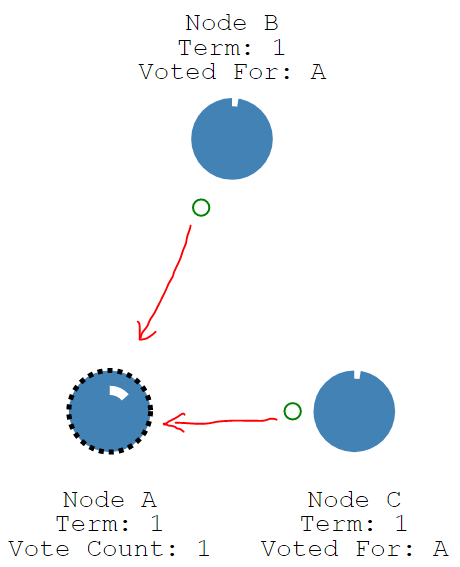
如果某个节点在这个定时器超时之前都没有收到来自leader的心跳请求,那么该follower将认为当前集群中没有leader了,它会改变自己的状态为candidate,如下图Node A。然后开启一个新的term,节点本地的任期号term+1。
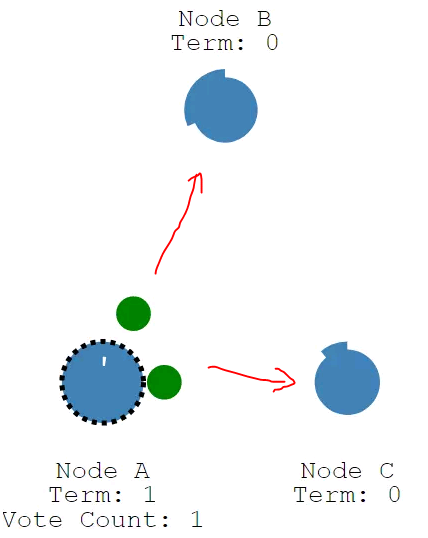
2.1.3 请求投票(RequestVote)
成为candidate的节点,会先投自己一票,然后并行给其他节点发送请求投票的消息RequestVote RPCs
那么一个节点在接收到RequestVote RPCs时,它会遵循以下约束来决定是否将票投给请求的发送者。
- 在任一任期内,单个节点最多只能投一票
- 候选人知道的信息不能比自己的少(这一部分,后面介绍log replication和safety的时候会详细介绍)
- first-come-first-served 先来先得
如果一个节点在接收到RequestVote RPCs时,上述约束都满足,那么他将投发送者一票,重置自己的election timeout,并给予响应。
2.1.4 票仓分布
对于一个candidate而言,它发出了请求RequestVote RPCs后,就开始等待其他节点的回复,这时可能会有三种结果:
全局就它一个candidate,其他的节点election timeout还没结束就接到了它的RequestVote RPCs,那么这时,这个candidate无疑会获得大多数票,成为新的leader。

有多个节点或先后或同时成为了candidate,但基于“每个节点一个任期内只能投一票”和“先到先得”的约束,以及请求的通信时间的随机性,还是有一个candidate运气好,获得了超过半数的票。
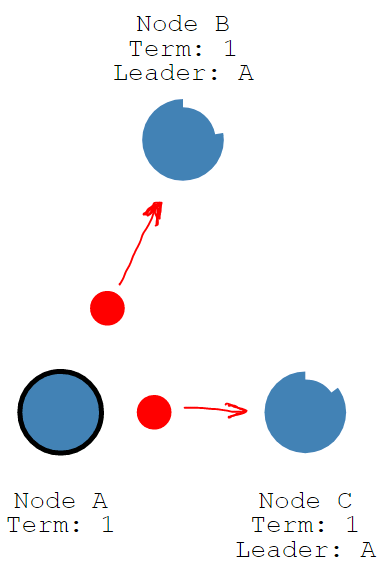
- 那么这个新的leader胜选后,会广播心跳,其他candidate发现心跳中携带的term信息不低于自己,知道有已经有leader被选举出来了,于是放弃选举,转换成follower。
- 有多个节点或先后或同时成为了candidate,但票数分布均匀,没有任何节点获得超过半数的票(这种情况称作split vote)。

- 此时所有的candidate都在等待能使自己选票超过半数的响应,等啊等,直到超时后重新发起选举。
- 如果出现split vote的情况,那么就延长了系统不可用的时间(没有leader是不能处理客户端写请求的),因此raft才引入randomized election timeouts来尽量避免平票情况。同时,leader-based 共识算法中,节点的数目都是奇数个,尽量保证majority的出现。
2.1.5 诞生leader
一个leader诞生以后,就像我们在前文2.1.1 心跳机制所述的那样,在这个新的任期内每隔heartBeat timeout时间,不停的向follower发送心跳请求(append entries)。
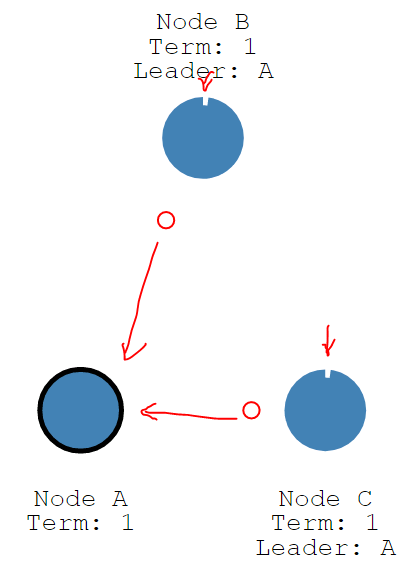
而每个follower则维持着自己的election timeout计时器,如果election timeout时间内没有收到来自leader的心跳,那么说明leader故障。将自己变成candidate,并开始下次选举。
2.2 日志复制(Log Replication)
前文我们说过了状态机复制(State Machine Replication),状态机复制有多种实现,在Raft中,也有一套基于Append-Only Log的状态机复制实现。
Raft 是分布式一致性算法,保证的实际上是多台机器上数据的一致性。前面讨论的 leader 选举,其实都是为了保证日志复制的一致性而做的前提。Raft的状态机复制实现,我们称作日志复制(Log Replication)。
Leader 选举只是为了保证日志相同的辅助工作。实际上,在更为学术的 Paxos 里面,是没有 leader 的概念的(大部分 Paxos 的实现通常会加入 leader 机制提高性能)。
这里的日志,指的是命令日志,对于客户端发来的命令请求,leader会将其封装成一个Log Entry作为传输的载体。
在 Raft 中,leader会接收客户端的所有需求(follower会将写请求转发给leader),leader会将数据以Log Entry的方式通过AppendEntries RPC同步给所有followers
只要超过半数以上的follower反馈成功(返回ack),这条日志就成功提交了。如果RPC请求超时,leader就不停的进行AppendEntries RPC重试。
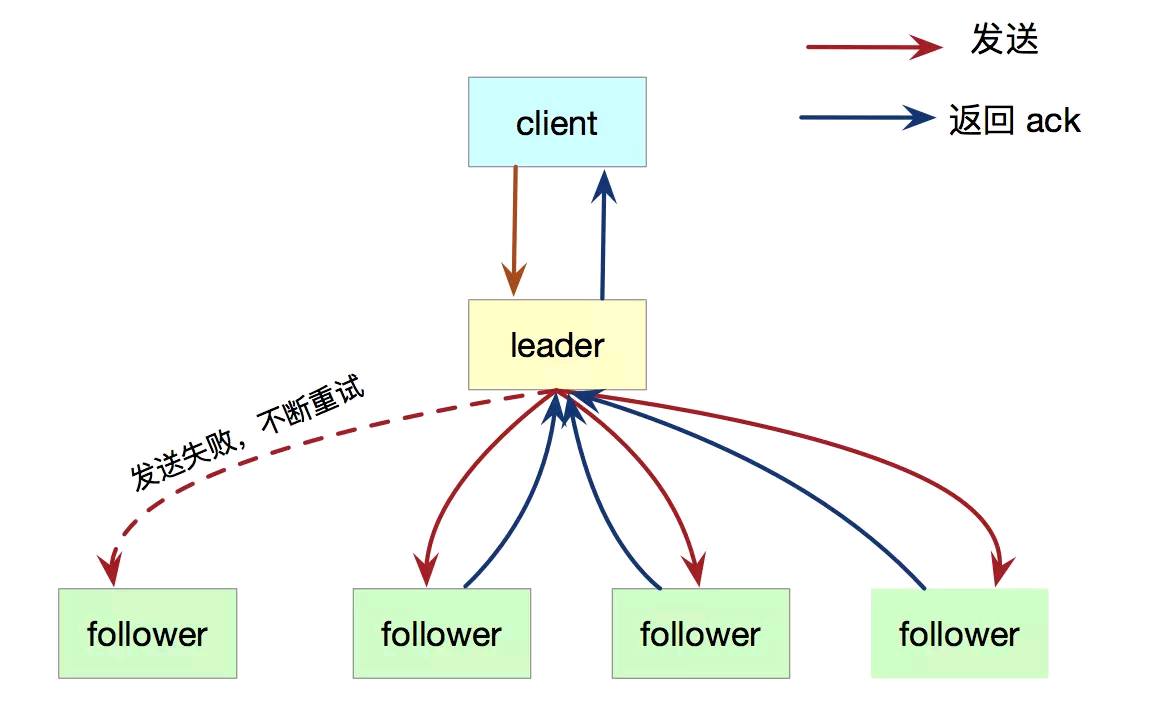
简单来说,保证复制日志相同,才是分布式一致性算法的最终任务。
2.2.1 Log和Log Entry
Raft中每个节点,都会维护一个本地Log数组,其数据结构如下图:
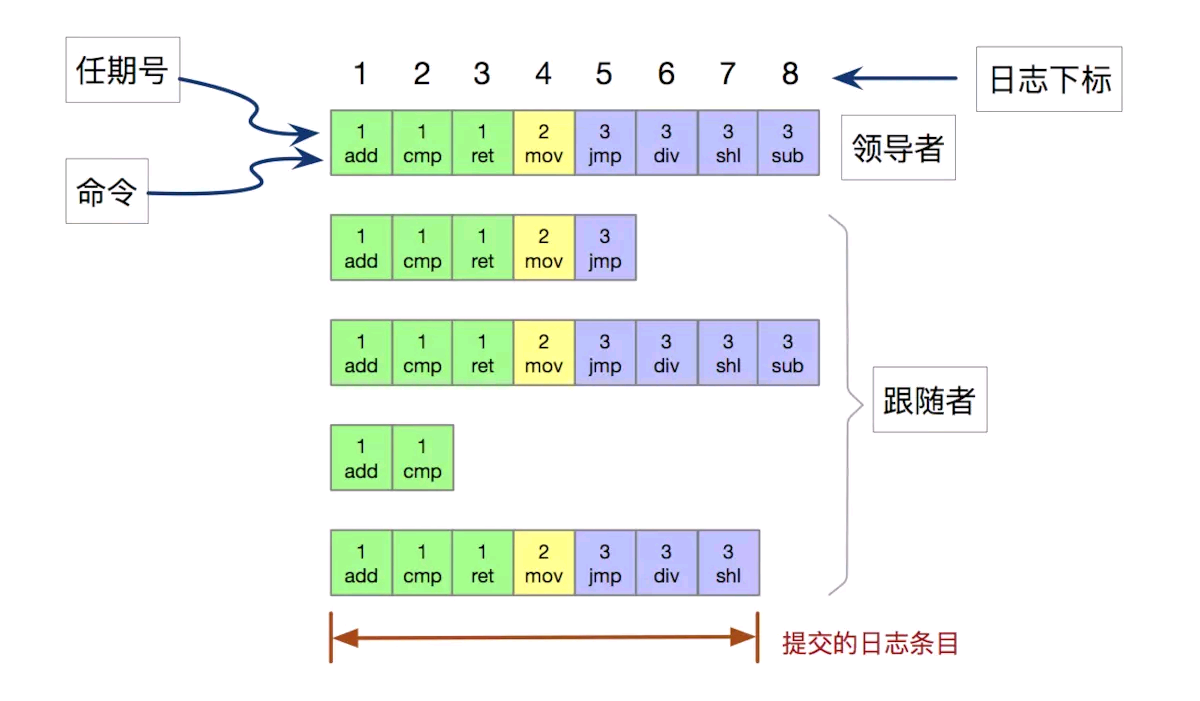
其构成有:
- 创建日志时的任期号(用来检查节点日志是否出现不一致的情况)
- 状态机需要执行的指令(真正的内容)
- 索引:整数索引,表示日志条目在日志数组中位置
上图显示,共有 8 条日志,提交了 7 条。提交的日志都将通过状态机持久化到磁盘中,防止宕机。
2.2.2 一致性校验
然后谈谈主从日志的一致性问题,这个是分布式一致性算法要解决的根本问题。
Raft 主从日志的一致性,这个最终的目标,可以分解成一个假设和一个充分条件。
我们可以假设:如果在不同的日志中的两个日志条目的
任期号和索引下标相同,那么他们的指令就是相同的。leader 最多在一个任期里的一个日志索引位置创建一条日志条目,而所有follower的日志来源都是leader,日志条目在日志的位置从来不会改变,所以基本上可以用任期号和索引下标当做Log Entry的主键
那么,主从日志一致性的充分条件可以是:如果在不同节点的日志里, 任意2个拥有相同的任期号和索引的日志条目,他们之前的日志项都是相同的,那么这些节点的日志就都是一致的。
达成了上述的这个充分条件,就达成了主从日志一致的最终条件,那如何达成这个充分条件呢?Raft引入了一种一致性校验约束。
每次 RPC 发送附加日志时,leader 会把当前这条日志Entry的前一个日志Entry的下标和任期号一起发送给 follower,如果 follower 发现发来前一个日志Entry的下标和任期号和自己队尾的日志Entry不匹配,那么就拒绝接受这条日志,这个称之为一致性校验
如果每一步都严格遵守该校验,就达成了主从日志一致的最终条件。
2.2.3 日志复制过程
有了这个一致性校验,我们再反过头来看下日志复制的过程。
在Raft协议中有两个主要的消息,一个是在第二节讲到的RequestVote RPC,用于选主投票时leader发出的消息。一个就是AppendEntries RPC,用于心跳和日志复制。对于心跳,只需要发送空内容的AppendEntries RPC就可以了,我们主要关注日志复制的消息,看看Raft是怎么操作的。
leader接受客户端的操作请求,如“将X赋值为3”。
- 假如leader当前的任期为term1,那么leader就会向自己本地log的最后添加一个entry,比如索引为K,内容为“term1:X赋值为3”。
leader向集群中其他follower并行发送AppendEntries RPC消息。这个消息里面包含:
- 这个新的entry和索引,即“term1:X赋值为3”和K。
- 前一个entry的内容和索引,比如“term1:Y赋值为2”和K-1。
当一个follower收到一个AppendEntries RPC消息时,会查看自己本地的log中的K-1位置的entry的内容。(一致性校验)
假如本地log中K-1位置的entry内容与接收到的来自leader的K-1的entry内容一致(下标和任期号一致),那么就将leader发来的K位置的entry保存在自己的K位置(当然要做并发控制),并返回true,告诉leader保存成功了
假如本地log中K-1位置的entry内容与接收到的来自leader的K-1的entry内容不一致(下标和任期号不一致),那么就返回false,告诉leader不一致。
leader收到消息。
- 如果得到的反馈为true,即某个follower保存成功了,那么这个Log Entry的复制完成。
- 否则,见下文2.2.4 特殊情况的日志复制过程。
leader得到了超过半数的follower反馈的true消息,leader会执行这条Log Entry中的命令,并反馈客户端该命令已经提交,同时向其他follower广播这条Log Entry被commit的消息。
follower接收到Log Entry被commit的消息,执行该Log Entry中的命令。在当前日志被提交的过程中,如果leader先前的某些日志还没有被提交,则将会一同提交。
在Raft中,一切以leader为主。因此本地日志不是最新的话,就不能成为leader。因此在选主的时候,会进行日志比较。假如在投票阶段,一个follower收到的选主请求中,包含的日志信息比自己的要旧,那么也会拒绝给这个请求投赞成票。如何比较新旧呢?一是看任期term,一是看最后一个entry的索引号。任期大的新,任期相同的索引大的新。
2.2.4 特殊情况的日志复制过程
上面说的都是日志在正常情况下的表现,没有考虑到一些异常情况。
即,正常情况下,leader和follower的日志保持一致性,所以附加日志 RPC 的一致性检查从来不会失败。但如果我们将leader或者follower崩溃的情况考虑进来,那么将可能会出现三种情况:

- follower缺失当前leader上存在的日志条目。如a,b
- follower存在当前leader不存在的日志条目。如c,d(比如旧的leader仅仅将AppendEntries RPC消息发送到一部分follower就崩溃掉,然后新的当选leader的服务器恰好是没有收到该AppendEntries RPC消息的服务器)
- 或者follower即缺失当前leader上存在的日志条目,也存在当前leader不存在的日志条目。如e,f
这种情况如何处理呢?
Raft 给出了一个方案(补丁)
强制follower直接复制leader的日志(意味着follower中的和leader冲突的日志将被覆盖)。
要使得follower的日志和leader进入一致状态,leader必须找到follower最后一条和leader匹配的日志,然后从这条日志开始,用leader的日志条目,覆盖follower的日志条目
依据这个方案,上图中的 a follower和b follower从队尾直接复制即可。c follower最后一个条目将被覆盖,d follower最后2个任期为7的条目将被覆盖,e最后2个任期为4的条目将被覆盖,f 则比较厉害,需要覆盖下标为3之后的所有条目。
实现逻辑如下:
leader向集群中的follower发送AppendEntries RPC,内容为最新的Log Entry和其索引K,以及前一个Log Entry及其索引K-1,这里不再赘述。
一致性检验失败,follower向leader反馈false。
leader会将K自减1,然后再次重新发AppendEntries RPC给失败的follower,直到follower返回true。那么此时的K,就是follower最后一条和leader匹配的日志的下标。
最坏的情况是K=0时才得到true回复,这表示follower的Log和leader完全不一致。K=0得到的回复一定是true,因为没有K-1了
- 此时leader将匹配的位置和最新的位置中间的内容都发送给follower,follower会将接收到的内容,并覆盖到对应的位置。
实际上leader对每个follower都维护了一个nextIndex字段,来存上述过程中一直递减的K值,描述中我没有引入nextIndex字段的概念,力求精简,以便理解。