前言
在ElasticSearch集群中,master负责处理集群层面配置的变更和同步工作,所有yml文件配置node.master: true的节点都有资格经过选举成为master节点
es集群的master选举采用Bully算法
Bully算法
Leader选举的基本算法之一。
它假定所有节点都有一个惟一的ID,该ID对节点进行排序。 任何时候的当前Leader都是参与集群的最高id节点。
具体来说,Bully算法要求每个节点都投票给ID最高的那个节点,通过这一强制性的条件,让集群非常简单的协调一致。
该算法的优点是易于实现,但是,当拥有最大ID的节点处于不稳定状态的场景下会有问题,例如Master负载过重而假死,集群拥有第二大ID的节点被选为新主,这时原来的Master恢复,再次被选为新主,然后又假死…
而且该算法会有脑裂的问题。
elasticsearch通过控制触发时机来解决反复去世的问题,即当前的Master失效才会触发选举。
同时es又要求法定得票人数过半才能选出master,以此来解决脑裂。
es实际上是从具有master资格的节点中选id最小的节点作为master,而不是id最大的节点
选举触发时机
- 集群启动:
- 后台启动线程去ping集群中的节点,按照上述策略从具有master资格的节点中选举出master
- Master失效
- 非Master节点运行的MasterFaultDetection检测到Master失效,在其注册的listener中执行handleMasterGone,执行rejoin操作,重新选主。注意,即使一个节点认为Master失效,也会进入选主流程。
我们需要在候选集群中的节点的配置文件中设置参数 discovery.zen.munimum_master_nodes的值,这个参数表示在选举主节点时需要参与选举的候选主节点的节点数,默认值是1,官方建议取值 (master_eligibel_nodes/2)+1,其中 master_eligibel_nodes为候选主节点的个数。
这样做既能防止脑裂现象的发生,也能最大限度地提升集群的高可用性,因为只要不少于discovery.zen.munimum_master_nodes个候选节点存活,选举工作就能正常进行。当小于这个值的时候,无法触发选举行为,集群无法使用,不会造成分片混乱的情况。
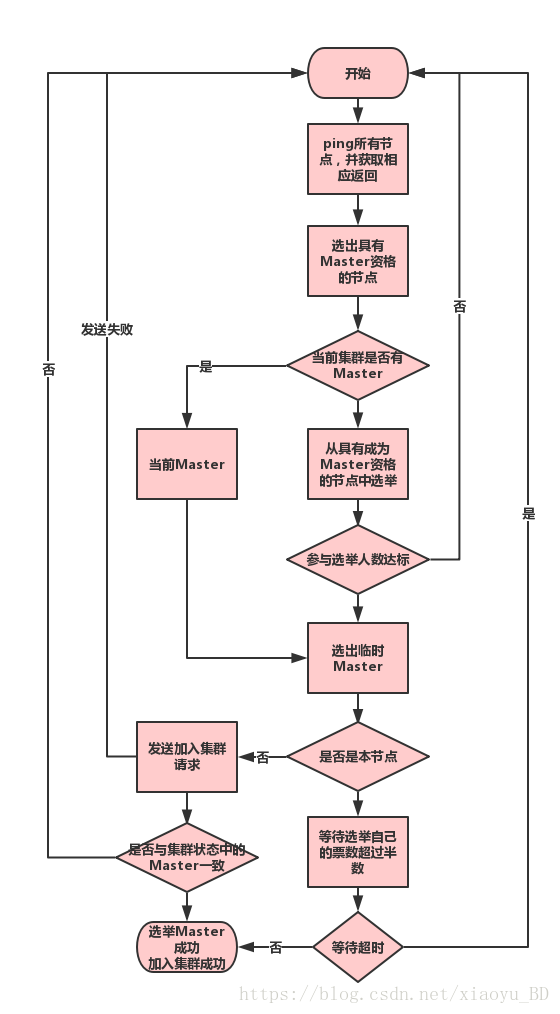
选举过程
Master选举主要逻辑在ZenDiscovery.findMaster(基于es 5.2版本)中:
开始
1
2private DiscoveryNode findMaster() {
logger.trace("starting to ping");每个节点ping集群下的其他节点,等待所有节点的返回。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29//pingAndWait用于获取其他节点的状态,这里只介绍下大致实现,不再展开具体源码:
//pingAndWait主要是使用上面介绍的ZenPing去ping配置中的所有host
//通过函数名称可以知道这是个同步调用,同步的具体实现和ElasticSearch大部分需要等待
//远程通信返回的行为类似,采用计数器记录发送的请求个数,每次有请求响应时递减计数器,
//当计数器递减为0时表示所有请求都得到了响应。
List<ZenPing.PingResponse> fullPingResponses = pingAndWait(pingTimeout).toList();
if (fullPingResponses == null) {
logger.trace("No full ping responses");
return null;
}
if (logger.isTraceEnabled()) {
StringBuilder sb = new StringBuilder();
if (fullPingResponses.size() == 0) {
sb.append(" {none}");
} else {
for (ZenPing.PingResponse pingResponse : fullPingResponses) {
sb.append("\n\t--> ").append(pingResponse);
}
}
logger.trace("full ping responses:{}", sb);
}
final DiscoveryNode localNode = clusterService.localNode();
// add our selves
assert fullPingResponses.stream().map(ZenPing.PingResponse::node)
.filter(n -> n.equals(localNode)).findAny().isPresent() == false;
//在获取的装填集中加入当前节点自己的状态,因为自己也需要加入选举,也可能被选举为主节点
fullPingResponses.add(new ZenPing.PingResponse(localNode, null, clusterService.state()));根据其他节点的返回,过滤掉没有资格参加选举的节点
1
2
3// filter responses
// 过滤PingResponse, 排除掉client节点,单纯的data节点
final List<ZenPing.PingResponse> pingResponses = filterPingResponses(fullPingResponses, masterElectionIgnoreNonMasters, logger);根据反馈,收集当前集群已经存在的master塞入activeMasters
1
2
3
4
5
6
7
8
9
10//activeMasters用来记录当前已经存在的主节点
List<DiscoveryNode> activeMasters = new ArrayList<>();
for (ZenPing.PingResponse pingResponse : pingResponses) {
// We can't include the local node in pingMasters list, otherwise we may up electing ourselves without
// any check / verifications from other nodes in ZenDiscover#innerJoinCluster()
//如果返回的信息表明自己当前已经是主节点,那么不会把自己加入到activeMasters中去
if (pingResponse.master() != null && !localNode.equals(pingResponse.master())) {
activeMasters.add(pingResponse.master());
}
}根据反馈,收集当前集群已经存在的具有选举资格的node塞入masterCandidates
1
2
3
4
5
6
7
8
9
10
11
// nodes discovered during pinging
//masterCandidates用来记录配置为可以成为主节点的候选节点
List<ElectMasterService.MasterCandidate> masterCandidates = new ArrayList<>();
//这里将返回节点中配置为可以作为主节点的节点加入候选节点中
for (ZenPing.PingResponse pingResponse : pingResponses) {
//这里要注意isMasterNode并不是说明该节点是不是主节点,而是表明该节点能不能成为主节点
if (pingResponse.node().isMasterNode()) {
masterCandidates.add(new ElectMasterService.MasterCandidate(pingResponse.node(), pingResponse.getClusterStateVersion()));
}
}如果集群中已经有master,那么加入它,否则,开始选举
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19//如果当前存在的主节点列表activeMasters为空,则从候选节点列表masterCandidates中选取主节点
if (activeMasters.isEmpty()) {
//判断是否有足够的候选节点
if (electMaster.hasEnoughCandidates(masterCandidates)) {
//进行节点选举
final ElectMasterService.MasterCandidate winner = electMaster.electMaster(masterCandidates);
logger.trace("candidate {} won election", winner);
return winner.getNode();
} else {
// if we don't have enough master nodes, we bail, because there are not enough master to elect from
logger.trace("not enough master nodes [{}]", masterCandidates);
return null;
}
} else {//activeMasters不为空,表示当前集群已经有master了
assert !activeMasters.contains(localNode) : "local node should never be elected as master when other nodes indicate an active master";
//如果当前存在的主节点列表activeMasters不为空,则从中选取主节点
// lets tie break between discovered nodes
return electMaster.tieBreakActiveMasters(activeMasters);
}如果集群中现在没有master,那么选出master
选举主要算法集中在electMaster.electMaster()方法中,我们来看下:
1
2
3
4
5
6
7
8
9
10
11
12
13/**
* Elects a new master out of the possible nodes, returning it. Returns <tt>null</tt>
* if no master has been elected.
*/
public MasterCandidate electMaster(Collection<MasterCandidate> candidates) {
//保证有足够的候选者,逻辑是判断有资格参选的node数量大于yml配置的minimumMasterNodes
assert hasEnoughCandidates(candidates);
List<MasterCandidate> sortedCandidates = new ArrayList<>(candidates);
//对候选者进行排序,
sortedCandidates.sort(MasterCandidate::compare);
//取队首的node即为master
return sortedCandidates.get(0);
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19/**
* compares two candidates to indicate which the a better master.
* A higher cluster state version is better
*
* @return -1 if c1 is a batter candidate, 1 if c2.
*/
public static int compare(MasterCandidate c1, MasterCandidate c2) {
// we explicitly swap c1 and c2 here. the code expects "better" is lower in a sorted
// list, so if c2 has a higher cluster state version, it needs to come first.
//先根据节点的clusterStateVersion比较,clusterStateVersion越大,优先级越高。
//这是为了保证新Master拥有最新的clusterState(即集群的meta),避免已经commit的meta变更丢失。
//因为Master当选后,就会以这个版本的clusterState为基础进行更新。
int ret = Long.compare(c2.clusterStateVersion, c1.clusterStateVersion);
if (ret == 0) {
//clusterStateVersion相同时,进入compareNodes,其内部按照节点的Id比较(Id为节点第一次启动时随机生成)
ret = compareNodes(c1.getNode(), c2.getNode());
}
return ret;
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
/** master nodes go before other nodes, with a secondary sort by id **/
private static int compareNodes(DiscoveryNode o1, DiscoveryNode o2) {
//isMasterNode方法是判断该节点yml文件是否配置了data.master=true,即是否有资格参选
//有资格参选的优先(其实从findMaster进入这里,所有的node都是有资格的)
if (o1.isMasterNode() && !o2.isMasterNode()) {
return -1;
}
if (!o1.isMasterNode() && o2.isMasterNode()) {
return 1;
}
//根据id排序升序排序
return o1.getId().compareTo(o2.getId());
}
如果集群中已经有master,找到这个master
1
2
3
4
5/** selects the best active master to join, where multiple are discovered */
public DiscoveryNode tieBreakActiveMasters(Collection<DiscoveryNode> activeMasters) {
//同理,也是默认id最小的node就是master
return activeMasters.stream().min(ElectMasterService::compareNodes).get();
}
选举过程简图