前言
我们平常采用的多进程方式实现的服务器端,即一次创建多个工作子进程来给客户端提供服务。其实这种方式是存在问题的。
可以打个比方:如果我们先前创建的几个进程承载不了目前快速发展的业务的话,是不是还得增加进程数?我们都知道系统创建进程是需要消耗大量资源的,多进程方式实现的服务器端会导致系统出现资源不足的情况。
那么有没有一种方式可以让一个进程同时为多个客户端端提供服务?
接下来要讲的IO多路复用技术就是对于上述问题的最好解答。即一个进程同时为多个客户端端提供服务。
对于IO复用,我们可以通过一个例子来很好的理解它。(例子来自于《TCP/IP网络编程》)
某教室有10名学生和1名老师,这些学生上课会不停的提问,所以一个老师处理不了这么多的问题。那么学校为每个学生都配一名老师,
也就是这个教室目前有10名老师。此后,只要有新的转校生,那么就会为这个学生专门分配一个老师,因为转校生也喜欢提问题。如果把以上例子中的学生比作客户端,那么老师就是负责进行数据交换的服务端。则该例子可以比作是多进程的方式。
后来有一天,来了一位具有超能力的老师,这位老师回答问题非常迅速,并且可以应对所有的问题。为了让这位老师更有效率的回答学生问题,老师让班长站在讲台边不停的扫视班级,如果有同学有问题举手了,那么班长就会提醒老师一下,老师这时候再扫视一下班上看谁举手,进而回答问题。
这就是IO复用,老师是应用程序进程,班长是多路复用的代理,学生是IO的流,在这种情况下,老师只需要关注班长就可以了,加入了班长这个角色,使得一个老师可以回答许多学生的问题。
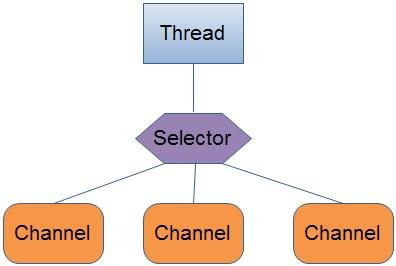
常规模型下,老师(应用进程)会阻塞在班长(代理)这里,直到班长反馈说有人举手,老师才会被唤醒,然后扫视班级回答问题。值得注意的是,班长每次只会反馈有人举手,不会反馈到底是谁举手。
目前的常用的IO复用模型有三种:select,poll,epoll。
在了解IO复用模型前,我们需要连接一些Linux操作系统中的前置知识。
1 前置知识
1.1 socket编程
socket编程内容繁多,具体详见该文章
1.2 用户空间 / 内核空间
现在操作系统都是采用虚拟存储器,那么对32位操作系统而言,它的寻址空间(虚拟存储空间)为4G(2的32次方)。
操作系统的核心是内核,独立于普通的应用程序,可以访问受保护的内存空间,也有访问底层硬件设备的所有权限。为了保证用户进程不能直接操作内核(kernel),保证内核的安全,操作系统将虚拟空间划分为两部分,一部分为内核空间,一部分为用户空间。
1.3 文件描述符
文件描述符(File descriptor)是计算机科学中的一个术语,是一个用于表述指向文件的引用的抽象化概念。
文件描述符在形式上是一个非负整数。实际上,它是一个索引值,指向内核为每一个进程所维护的该进程打开文件的记录表。
我们都知道在Linux下一切皆文件。当然设备也不例外,如果要对某个设备进行操作,就不得不打开此设备文件,打开文件就会获得该文件的文件描述符fd( file discriptor),它就是一个很小的整数。
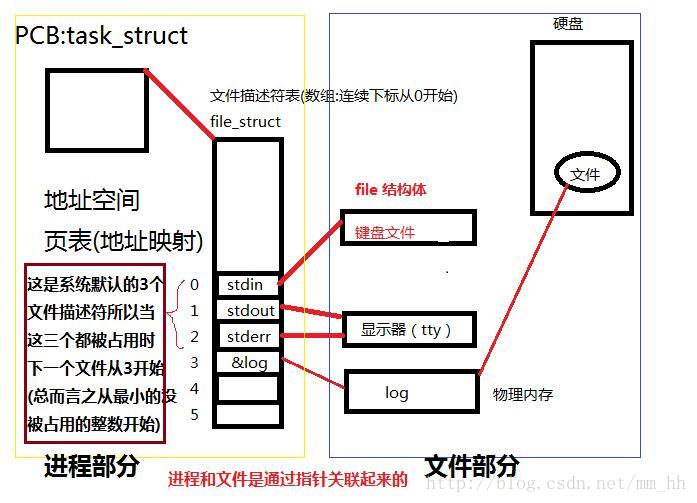
每个进程在PCB(Process Control Block,进程控制块)中保存着一份文件描述符表,文件描述符就是这个表的索引,文件描述符表中每个表项都有一个指向已打开文件的指针。现在我们明确一下:已打开的文件在内核中用file结构体表示,文件描述符表中的指针指向file结构体。file结构体才是内核中用来描述文件属性的结构体。
file结构体如下:
1 | struct FILE |
具体详见文章Linux下 文件描述符(fd)与 文件指针(FILE*)
2 select模式
select模型的原理,套用前言中的老师回答学生问题的例子,则是:老师仅仅知道有学生举手了,但是到底是哪些学生举手了,他需要用眼睛扫描一遍全班同学,找出举手的同学,然后倾听他的问题,并回答他的问题。
所以select具有O(n)的无差别轮询时间复杂度,同时处理的流越多,无差别轮询时间就越长。
2.1 select函数
Linux系统提供了一个函数来供开发者使用select多路复用机制:
int select(int maxfdp,fd_set *readfds,fd_set *writefds,fd_set *errorfds,struct timeval *timeout);
该函数的作用是:通过轮询,可以同时监视多个文件描述符是否发生了读/写/异常这三类IO变化,最后返回发生变化的文件描述符数量,以及读/写/异常这三种变化分别发生在哪些文件描述符中。
我们来看看它的参数的含义:
在看参数前,我们要了解:struct fd_set可以理解为一个集合,这个集合中存放的是文件描述符(file descriptor),即文件句柄。fd_set集合可以通过下列宏由人为来操作。
FD_ZERO(fd_set *fdset):清空fdset与所有文件句柄的联系。
FD_SET(int fd, fd_set *fdset):建立文件句柄fd与fdset的联系。
FD_CLR(int fd, fd_set *fdset):清除文件句柄fd与fdset的联系。
FD_ISSET(int fd, fdset *fdset):检查fdset联系的文件句柄fd是否可读写,>0表示可读写。
int maxfdp:是一个整数值,是指集合中所有文件描述符的范围,即所有文件描述符的最大值加1,不能错!在Windows中这个参数的值无所谓,可以设置不正确。
readfds:传入select函数的需要被监控读IO的fd_set文件描述符集合,select函数会负责监视readfds的读变化,如果readfds中的某个文件描述符指向的文件能读出数据,那么在返回的时候,select不仅会统计它的数量,而且还会改写readfds,以标出是它的位置。
writefds:传入select函数的需要被监控写IO的fd_set文件描述符集合,select函数会负责监视writefds的写变化,如果writefds中的某个文件描述符指向的文件能写入数据,那么在返回的时候,select不仅会统计它的数量,而且还会改写writefds,以标出是它的位置。
errorfds:传入select函数的需要被监控异常IO的fd_set文件描述符集合,select函数会负责监视errorfds的异常变化,如果readfds中的某个文件描述符指向的文件能读出异常数据,那么在返回的时候,select不仅会统计它的数量,而且还会改写errorfds,以标出是它的位置。
struct timeval:用来代表时间值,有两个成员,一个是秒数,另一个是毫秒数。
- 若将NULL以形参传入,即不传入时间结构,就是将select置于阻塞状态,一定等到监视文件描述符集合中某个文件描述符发生变化为止;
- 若将时间值设为0秒0毫秒,就变成一个纯粹的非阻塞函数,不管文件描述符是否有变化,都立刻返回继续执行,文件无变化返回0,有变化返回一个正值;
- timeout的值如果大于0,这就是等待的超时时间,即select在timeout时间内阻塞,超时时间之内有事件到来就返回了,否则在超时后不管怎样一定返回。
1
2
3
4
5
6
7struct timeval{
long tv_sec; /*秒 */
long tv_usec; /*微秒 */
}
2.2 select函数的使用
select函数用来验证3种读、写、异常三种监视项的变化情况。使用前,我们先声明3个fd_set变量,然后分别向其注册文件描述符信息,并把变量的地址传入到函数的readfds/writefds/errorfds参数上。
同时我们要明确要监控的文件描述符数量,原本这个数量不好计算,但好在每次新建文件描述符时,其值(文件描述符是非负整数)都会增1,故只需将最大的文件描述符值加1(因为文件描述符从0开始,所以要+1)再传递到select函数的maxfdp参数即可。
最后再设置一下超时时间(如果需要的话)到timeval参数即可。
2.3 select函数的返回
在超时时间之内,如果三个fd_set对应的文件描述符有变化,那么select会返回一个大于0的值,表示发生变化的文件描述符数量。如果没有变化,则在timeout的时间后select返回0,若发生错误返回负值。
那么问题来了,select函数只返回了变化的文件描述符数量,那么怎样获知哪些文件描述符发生了变化呢?
原来select函数还会改写传进去的readfds/writefds/errorfds集合,即将他们都用FD_ZERO(fd_set *fdset)清空,即fd_set中的所有位数都置为0,然后如果某个文件描述符有读IO,那么在其对应项上用FD_SET(int fd, fd_set *fdset)来设置1;
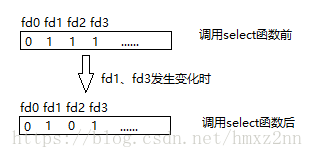
select函数调用完成后,向其传递的fd_set变量中将发生变化。发生变化的文件描述符对应位除外,其他原来为1的所有位均变为0。因此,可以认为readfds中值为1的位置上的文件描述符发生了读变化,writefds中值为1的位置上的文件描述符发生了写变化,errorfds中值为1的位置上的文件描述符发生了异常变化。
因为传入的三个fd_set会被改写,所以使用前记得备份原set。
2.4 select的实现机制
我们来简单了解一下select机制的源码:
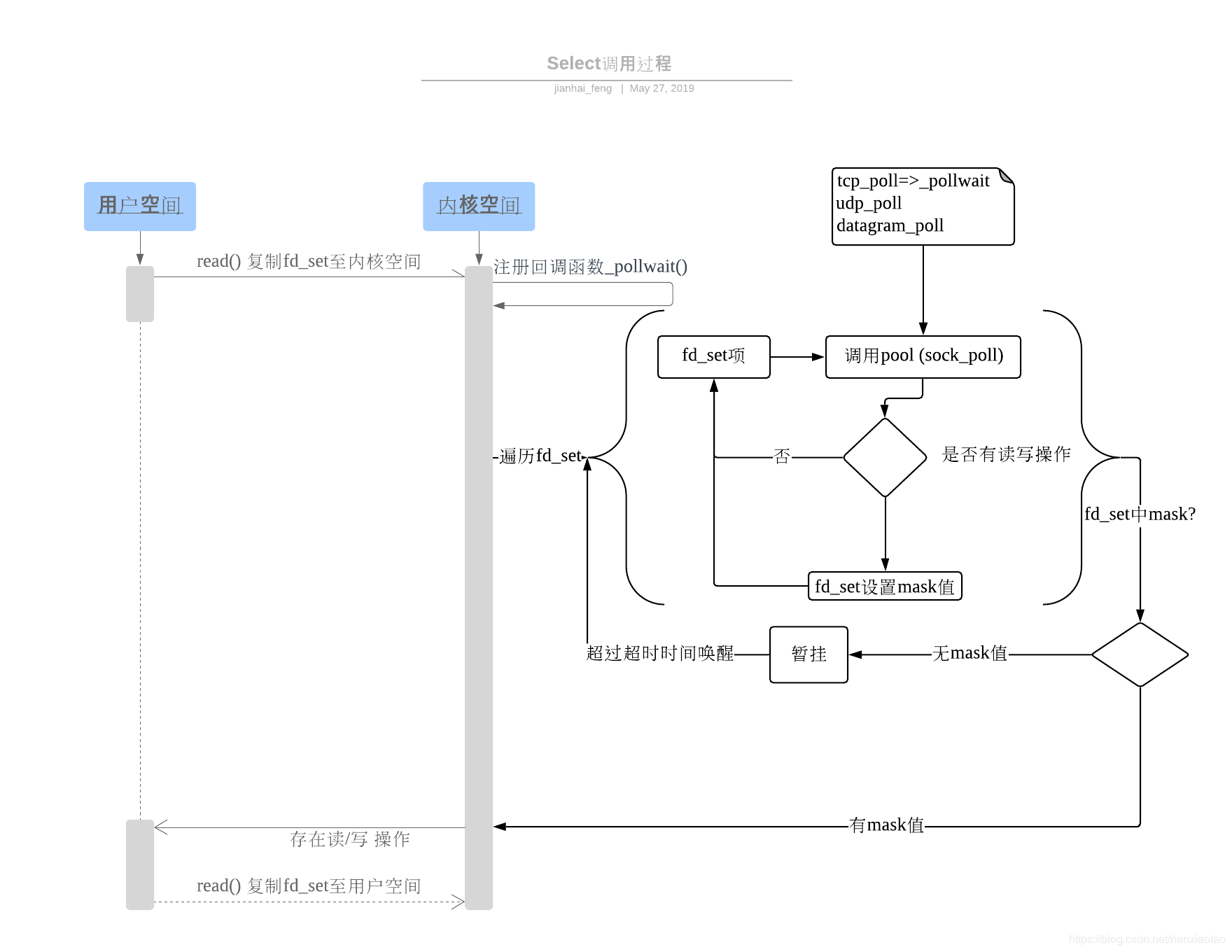
- 使用copy_from_user从用户空间拷贝fd_set到内核空间
- 注册回调函数__pollwait,__pollwait的主要工作就是把current进程(当前进程)挂到设备的等待队列中,不同的设备有不同的等待队列,对于tcp_poll来说,其等待队列是sk->sk_sleep(注意把进程挂到等待队列中并不代表进程已经睡眠了)。驱动程序在得知设备有IO事件时(通常是该设备上IO事件中断),会调用wakeup,wakeup –> _wake_up_common -> curr->func(即pollwake),pollwake函数里面调用_pollwake函数, 通过pwq->triggered = 1将进程标志为唤醒。再调用default_wake_function(&dummy_wait, mode, sync, key)这个默认的通用唤醒函数唤醒调用select的进程,这时current进程便被唤醒了。
- 遍历所有fd,依次调用其fd的poll方法(对于socket,这个poll方法是sock_poll,sock_poll根据情况会调用到tcp_poll,udp_poll或者datagram_poll),poll函数调用poll_wait函数,poll_wait函数调用__pollwait()。
- 以tcp_poll为例,tcp_poll的核心实现就是pollwait,也就是上面注册的回调函数。它调用pollwait检查是否有读写操作,并返回一个描述读写操作是否就绪的mask掩码(可以理解为我们上面说的fd_set对应项置为1的那个1),根据这个mask掩码给fd_set中当前fd的对应项赋值。
- 如果遍历完所有的fd,fd_set中还没有一个表示可读/写/异常的mask掩码(也就是三个fd_set还没有位置置1),则会调用schedule_timeout使调用select的进程(也就是current进程)进入睡眠。当设备驱动发生自身资源可读写后,会唤醒其等待队列上睡眠的进程。如果超过一定的超时时间(schedule_timeout指定),还是没人唤醒,则调用select的进程会重新被唤醒获得CPU,进而重新遍历fd,判断有没有就绪的fd。
- 重复直到要么超时,要么有就绪的fd,然后返回,并把fd_set从内核空间拷贝回用户空间。
2.5 select机制的缺点
- 每次调用select,都需要把fd_set集合从用户态拷贝到内核态,如果fd_set集合很大时,那这个开销也很大
- 同时每次调用select都需要在内核遍历传递进来的所有fd_set,如果fd_set集合很大时,那这个开销也很大
- 为了减少数据拷贝带来的性能损坏,内核对被监控的fd_set集合大小做了限制,并且这个是通过宏控制的,一般来说这个数目和系统内存关系很大,具体数目可以cat /proc/sys/fs/file-max察看。32位机默认是1024个。64位机默认是2048。
3 poll模式
poll的实现和select非常相似,只是描述fd集合的方式不同,poll使用pollfd结构而不是select的fd_set结构,pollfd结构使用链表而非数组,这导致pollfd的长度没有限制。除此之外,二者的原理基本一致,即对多个描述符也是进行轮询,根据描述符的状态进行处理。
3.1 poll函数
int poll (struct pollfd *fds, unsigned int nfds, int timeout);
不同与select使用三个位图来表示三个fdset的方式,poll使用一个 pollfd的指针实现。
同时也不需要三个fd_set来表示分别要监控哪些事件,poll定义的pollfd结构,就封装了该fd需要监控的事件:
1 | struct pollfd { |
和select函数一样,poll会改写pollfd,返回后,需要轮询pollfd来获取就绪的描述符。
3.2 poll函数的实现
poll本质上和select没有区别,它将用户传入的数组拷贝到内核空间,然后查询每个fd对应的设备状态,如果设备就绪则在设备等待队列中加入一项并继续遍历,如果遍历完所有fd后没有发现就绪设备,则挂起当前进程,直到设备就绪或者主动超时,被唤醒后它又要再次遍历fd。这个过程经历了多次无谓的遍历。
因为poll和select的区别不大,所以除了fd集合没有限制外(但是数量过大后性能也是会下降),select其他的缺点poll都有。
4 epoll模式
由于epoll的实现机制与select/poll机制完全不同,上面所说的 select的缺点在epoll上不复存在。
设想一下如下场景:有100万个客户端同时与一个服务器进程保持着TCP连接。而每一时刻,通常只有几百上千个TCP连接是活跃的(事实上大部分场景都是这种情况)。如何实现这样的高并发?
在select/poll时代,服务器进程每次都把这100万个连接告诉操作系统(从用户态复制句柄数据结构到内核态),让操作系统内核去查询这些套接字上是否有事件发生,轮询完后,再将句柄数据复制到用户态,让服务器应用程序轮询处理已发生的网络事件,这一过程资源消耗较大,因此,select/poll一般只能处理几千的并发连接。
4.1 epoll的设计
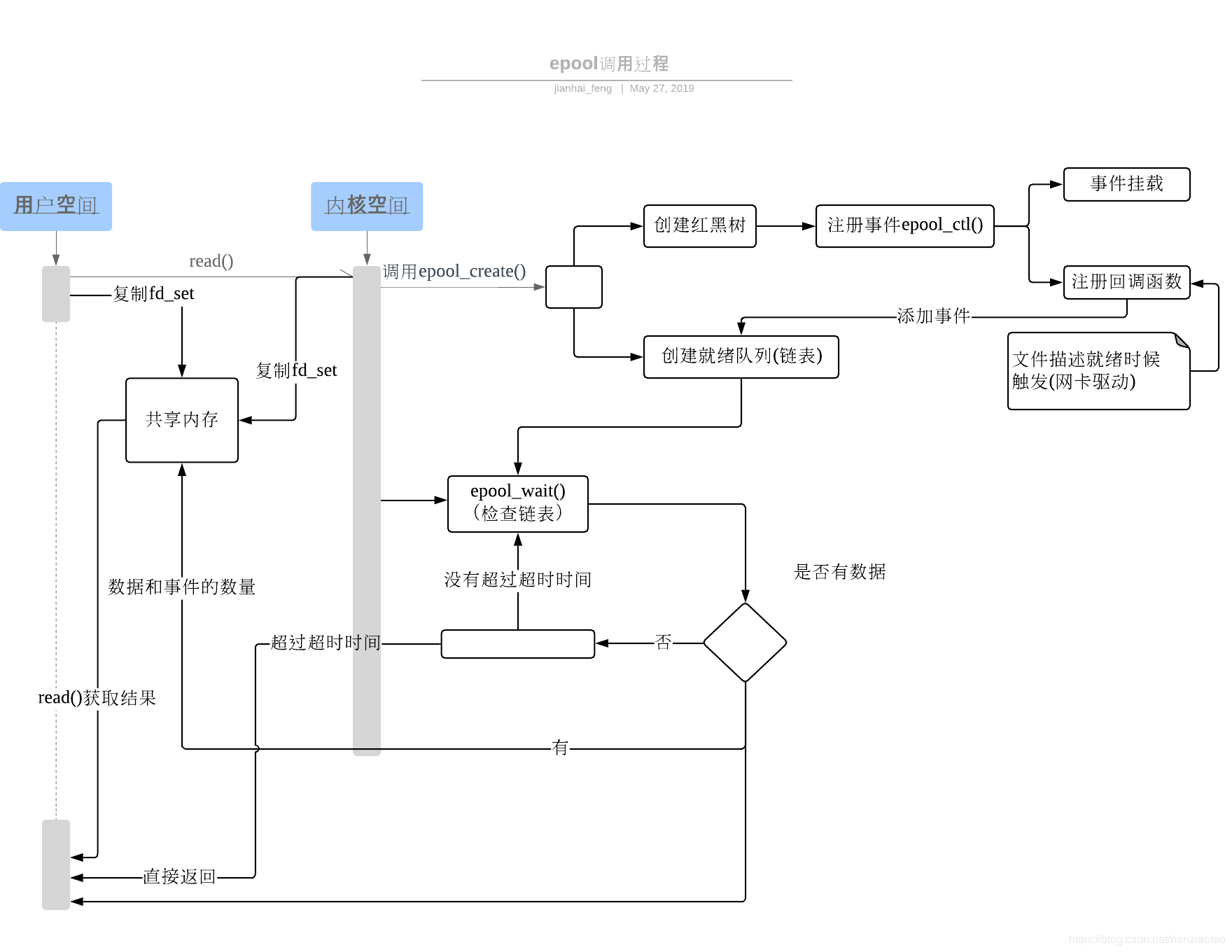
epoll的设计和实现与select完全不同。epoll通过在Linux内核中申请一个简易的文件系统,这个文件系统早期使用哈希表实现,后来改用红黑树来实现。
epoll把原先的select/poll调用分成了3个部分:
调用epoll_create()建立一个epoll句柄对象(在epoll文件系统中为这个句柄对象分配资源)
调用epoll_ctl向epoll对象中添加这100万个连接的套接字
调用epoll_wait收集发生的事件的连接
如此一来,要实现上面说是的场景,只需要在进程启动时建立一个epoll对象,然后在需要的时候向这个epoll对象中添加或者删除连接。同时,epoll_wait的效率也非常高,因为调用epoll_wait时,并没有一股脑的向操作系统复制这100万个连接的句柄数据,内核也不需要去遍历全部的连接(epoll通过内核和用户空间共享一块内存来实现共享句柄数据)。
4.2 epoll函数
epoll操作过程需要三个函数,分别如下:
int epoll_create(int size);- 创建一个epoll的句柄,size用来告诉内核这个监听的数目一共有多大,这个参数不同于select()中的第一个参数,给出最大监听的fd+1的值,参数size并不是限制了epoll所能监听的描述符最大个数,只是对内核初始分配内部数据结构的一个建议。
- 当创建好epoll句柄后,它就会占用一个fd值,在linux下如果查看/proc/进程id/fd/,是能够看到这个fd的,所以在使用完epoll后,必须调用close()关闭,否则可能导致fd被耗尽。
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);- 该函数是对指定描述符fd执行op操作,你可以理解为将套接字以及它要监控的事件,注册到epoll句柄中。通过此调用向epoll对象中添加、删除、修改感兴趣的事件,返回0标识成功,返回-1表示失败。其各参数含义如下
- epfd:是epoll_create()的返回值,可以理解为指向epoll句柄的指针。
- op:表示op操作,用三个宏来表示:添加EPOLL_CTL_ADD,删除EPOLL_CTL_DEL,修改EPOLL_CTL_MOD。分别添加、删除和修改对fd的监听事件。
- fd:是需要监听的fd(文件描述符)
- epoll_event:是告诉内核需要监听什么事,struct epoll_event结构如下:
1
2
3
4
5
6
7
8
9
10
11
12
13struct epoll_event {
__uint32_t events; /* Epoll events */
epoll_data_t data; /* User data variable */
};
//events可以是以下几个宏的集合:
EPOLLIN :表示对应的文件描述符可以读(包括对端SOCKET正常关闭);
EPOLLOUT:表示对应的文件描述符可以写;
EPOLLPRI:表示对应的文件描述符有紧急的数据可读(这里应该表示有带外数据到来);
EPOLLERR:表示对应的文件描述符发生错误;
EPOLLHUP:表示对应的文件描述符被挂断;
EPOLLET: 将EPOLL设为边缘触发(Edge Triggered)模式,这是相对于水平触发(Level Triggered)来说的。
EPOLLONESHOT:只监听一次,当监听完这次事件之后,如果还需要继续监听这个socket的话,需要再次把这个socket加入到EPOLL队列里epoll的全程是eventpoll,顾名思义,它的实现机制是基于event事件的,所以不同于select使用三个fd_set来对应读/写/异常的IO变化,也不同于poll只是在pollfd的结构体中使用short events来对应事件,epoll专门定义了一个epoll_event结构体,将其作为读/写/异常的IO变化的逻辑封装,称为事件(event)。
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);- 等待epfd上的io事件,最多返回maxevents个事件。
- epfd参数是epoll_create()的返回值,可以理解为指向epoll句柄的指针。
- events参数用来从内核得到事件的集合
- maxevents参数告知内核这个events有多大,这个maxevents的值不能大于创建epoll_create()时的size。
- timeout参数是超时时间(毫秒,0会立即返回,-1将不确定,也有说法说是永久阻塞)。该函数返回需要处理的事件数目,如返回0表示已超时。
4.3 epoll的两种工作模式
epoll对文件描述符的操作有两种模式:LT(level trigger)和ET(edge trigger)。LT模式是默认模式,LT模式与ET模式的区别如下:
- LT模式:当epoll_wait检测到描述符事件发生并将此事件通知应用程序,应用程序可以不立即处理该事件。下次调用epoll_wait时,会再次响应应用程序并通知此事件。
- LT(level triggered)是缺省的工作方式,并且同时支持block和no-block socket.在这种做法中,内核告诉你一个文件描述符是否就绪了,然后你可以对这个就绪的fd进行IO操作。如果你不作任何操作,内核还是会继续通知你的。
- ET模式:当epoll_wait检测到描述符事件发生并将此事件通知应用程序,应用程序必须立即处理该事件。如果不处理,下次调用epoll_wait时,不会再次响应应用程序并通知此事件。
- ET(edge-triggered)是高速工作方式,只支持no-block socket。在这种模式下,当描述符从未就绪变为就绪时,内核通过epoll告诉你。然后它会假设你知道文件描述符已经就绪,并且不会再为那个文件描述符发送更多的就绪通知,直到你做了某些操作导致那个文件描述符不再为就绪状态了(比如,你在发送或者接收请求,或者发送接收的数据少于一定量时导致了一个EWOULDBLOCK 错误)。但是请注意,如果一直不对这个fd作IO操作(从而导致它再次变成未就绪),内核也不会发送更多的通知(only once)
- ET模式在很大程度上减少了epoll事件被重复触发的次数,因此效率要比LT模式高。epoll工作在ET模式的时候,必须使用非阻塞套接口,以避免由于一个文件句柄的阻塞读/阻塞写操作,把处理多个文件描述符的任务饿死。
二者的区别举个一个例子:
- 我们已经把一个用来从管道中读取数据的文件句柄(RFD)添加到epoll描述符
- 这个时候从管道的另一端被写入了2KB的数据
- 调用epoll_wait(2),并且它会返回RFD,说明它已经准备好读取操作
- 然后我们读取了1KB的数据
- 调用epoll_wait(2)……
如果是LT模式,那么在第5步调用epoll_wait(2)之后,仍然能收到通知RFD有事件。因为第四步我们没有把RFD的数据读完,只读了1KB。
如果是ET模式,那么在第5步调用epoll_wait(2)之后,不会收到通知RFD有事件了,ET模式只会在第三步提醒一次。
4.4 epoll的实现机制
当某一进程调用epoll_create方法时,Linux内核会创建一个eventpoll结构体,这个结构体中有两个成员与epoll的使用方式密切相关。eventpoll结构体如下所示:
1 | struct eventpoll{ |
每一个epoll对象都有一个独立的eventpoll结构体,用于存放通过epoll_ctl方法向epoll对象中添加进来的事件。这些事件都会挂载在红黑树中,如此,重复添加的事件就可以通过红黑树而高效的识别出来(红黑树的插入时间效率是lgn,其中n为树的高度)。
而所有添加到epoll中的事件都会与设备(网卡)驱动程序建立回调关系,也就是说,当相应的事件发生时会调用这个回调方法。这个回调方法在内核中叫ep_poll_callback,它会将发生的event事件添加到rdlist双链表中。
在epoll中,对于每一个事件,都会建立一个epitem结构体,如下所示:
1 | struct epitem{ |
epitem可以理解为:事件逻辑结构体epoll_event与双向链表/红黑树之间的映射关系,其关系如下图所示:
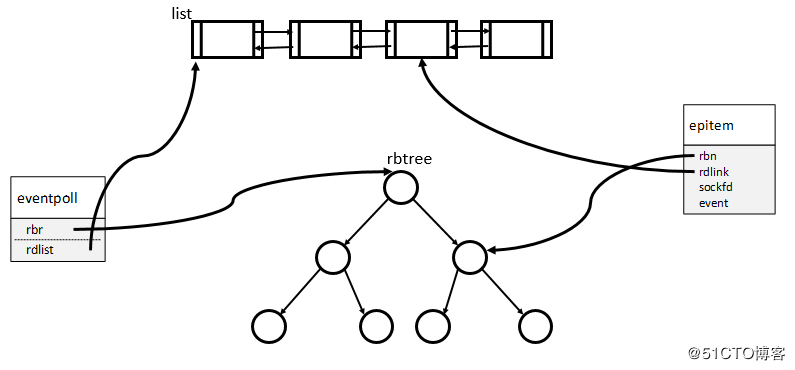
当调用epoll_wait检查是否有事件发生时,只需要检查eventpoll对象中的rdlist双链表中是否有元素即可。如果rdlist不为空,则把发生的事件复制到用户态,同时将事件数量返回给用户。
5 三种模型的区别和取舍
支持一个进程所能打开的最大连接数
- select:单个进程所能打开的最大连接数有FD_SETSIZE宏定义,其大小是32个整数的大小,当然我们可以对进行修改,然后重新编译内核,但是性能可能会受到影响,这需要进一步的测试。
- poll:poll本质上和select没有区别,但是它没有最大连接数的限制,原因是它是基于链表来存储的。
- epoll:虽然连接数有上限,但是很大,1G内存的机器上可以打开10万左右的连接,2G内存的机器可以打开20万左右的连接。
FD剧增后带来的IO效率问题
- select:因为每次调用时都会对连接进行线性遍历,所以随着FD的增加会造成遍历速度慢的“线性下降性能问题”。
- poll:同上
- epoll:因为epoll内核中实现是根据每个fd上的callback函数来实现的,只有活跃的socket才会主动调用callback,所以在活跃socket较少的情况下,使用epoll没有前面两者的线性下降的性能问题,但是所有socket都很活跃的情况下,可能会有性能问题。
消息传递方式
- select:内核需要将消息传递到用户空间,都需要内核拷贝动作
- poll:同上
- epoll:epoll通过内核和用户空间共享一块内存来实现的。
综上,在选择select,poll,epoll时要根据具体的使用场合以及这三种方式的自身特点。
表面上看epoll的性能最好,但是在连接数少并且连接都十分活跃的情况下,select和poll的性能可能比epoll好,毕竟epoll的通知机制需要很多函数回调。
select,poll实现需要自己不断轮询所有fd集合,直到设备就绪,期间可能要睡眠和唤醒多次交替。而epoll其实也需要调用epoll_wait不断轮询就绪链表,期间也可能多次睡眠和唤醒交替,但是它是设备就绪时,调用回调函数,把就绪fd放入就绪链表中,并唤醒在epoll_wait中进入睡眠的进程。虽然都要睡眠和交替,但是select和poll在“醒着”的时候要遍历整个fd集合,而epoll在“醒着”的时候只要判断一下就绪链表是否为空就行了,这节省了大量的CPU时间。这就是回调机制带来的性能提升。
select低效是因为每次它都需要轮询。但低效也是相对的,视情况而定,也可通过良好的设计改善
select,poll每次调用都要把fd集合从用户态往内核态拷贝一次,并且要把current往设备等待队列中挂一次,而epoll只要一次拷贝,而且把current往等待队列上挂也只挂一次(在epoll_wait的开始,注意这里的等待队列并不是设备等待队列,只是一个epoll内部定义的等待队列)。这也能节省不少的开销。