1 MySQL文件系统
本章节将分析构成MySQL数据库和InnoDB存储引擎表的各种类型文件。这些文件有以下这些。
- 参数文件∶告诉MySQL实例启动时在哪里可以找到数据库文件,并且指定某些初始化参数,这些参数定义了某种内存结构的大小等设置,还会介绍各种参数的类型。
- 日志文件∶用来记录MySQL实例对某种条件做出响应时写人的文件,如错误日志文件、二进制日志文件、慢查询日志文件、查询日志文件等。
- socket文件∶当用UNIX域套接字方式进行连接时需要的文件。
- pid文件∶MySQL实例的进程 ID文件。
- MySQL表结构文件∶用来存放 MySQL表结构定义文件。
- 存储引擎文件∶因为MySQL表存储引擎的关系,每个存储引擎都会有自己的文件来保存各种数据。这些存储引擎真正存储了记录和索引等数据。本章主要介绍与 InnoDB有关的存储引擎文件。
1.1 参数文件
当 MySQL实例启动时,数据库会先去读取一个配置参数文件,用来寻找数据库的各种文件所在位置以及指定某些初始化参数,这些参数通常定义了某种内存结构有多大等。
在默认情况下,MySQL实例会按照一定的顺序在指定的位置进行读取,用户只需通过命令mysql--help | grep my.cnf来寻找即可。
MySQL数据库参数文件的作用和Oracle数据库的参数文件极其类似,不同的是,Oracle实例在启动时若找不到参数文件,是不能进行装载(mount)操作的。MySQL稍微有所不同,MySQL实例可以不需要参数文件,这时所有的参数值取决于编译MySQL时指定的默认值和源代码中指定参数的默认值。
MySQL数据库的参数文件是以文本方式进行存储的。用户可以直接通过一些常用的文本编辑软件(如vi和emacs)进行参数的修改。
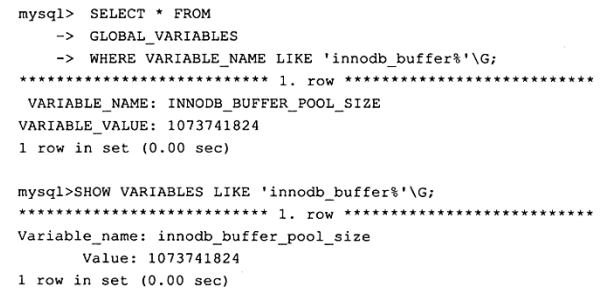
MySQL数据库参数是一个键/值(key/value)对。如innodb_buffer_pool_size=1G。
可以通过命令 SHOW VARIABLES查看数据库中的所有参数,也可以通过LIKE来过滤参数名。
1.1 参数的类型
MySQL数据库中的参数可以分为两类∶
- 动态(dynamic)参数
- 静态(static)参数
动态参数意味着可以在MySQL实例运行中进行更改,静态参数说明在整个实例生命周期内都不得进行更改,就好像是只读(read only)的。可以通过SET命令对动态的参数值进行修改,SET 的语法如下∶

这里可以看到global和session关键字,它们表明该参数的修改是基于当前会话还是整个实例的生命周期。
有些动态参数只能在会话中进行修改,如autocommit;
而有些参数修改完后,在整个实例生命周期中都会生效,如binlog_cache_size;
而有些参数既可以在会话中又可以在整个实例的生命周期内生效,如 read_buffer_size。
举例如下:
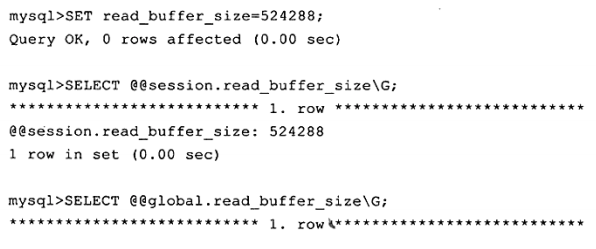

上述示例中将当前会话的参数read_buffer_size从2MB调整为了512KB,而用户可以看到全局的read_buffer_size的值仍然是2MB,也就是说如果有另一个会话登录到MySQL实例,它的read_buffer_size的值是2MB,而不是512KB。这里使用了set global | session来改变动态变量的值。用户同样可以直接使用SET@@global | @@session来更改,如下所示∶
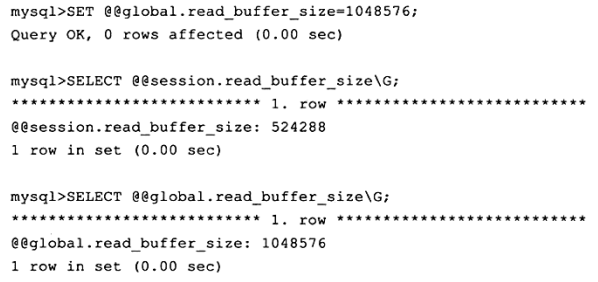
这次把read_buffer_size全局值更改为IMB,而当前会话的read bufer_size的值还是512KB。
这里需要注意的是,对变量的全局值进行了修改,仅在这次的实例生命周期内都有效,但MySQL实例本身并不会对参数文件中的该值进行修改。也就是说,在下次启动时MySQL实例还是会读取参数文件。若想在数据库实例下一次启动时该参数还是保留为当前修改的值,那么用户必须去修改参数文件。
1.2 日志文件
日志文件相关介绍详见本站文章《MySQL日志体系详解》
1.3 socket文件
之前的文章中我们提到过,在UNIX系统下本地连接MySQL可以采用UNIX域套接字方式,这种方式需要一个套接字(socket)文件。套接字文件可由参数socket控制。一般在/tmp 目录下,名为mysql.sock∶

1.4 pid文件
当MySQL实例启动时,会将自己的进程ID写入一个文件中——该文件即为pid文件。该文件可由参数pid_file控制,默认位于数据库目录下,文件名为主机名.pid∶

1.5 表结构定义文件
MySQL数据的存储是根据表进行的,但因为MySQL插件式存储引擎的体系结构的关系,所以MySQL要在存储引擎之上将表信息记录下来,于是,MySQL为每个表都定义与之对应的文件。不论表采用何种存储引擎,MySQL都有一个以frm为后缀名的文件,这个文件记录了该表的表结构定义。
frm还用来存放视图的定义,如用户创建了一个va视图,那么对应地会产生一个v_a.frm文件,用来记录视图的定义,该文件是文本文件,可以直接使用cat命令进行查看∶

1.6 InnoDB存储引擎文件
之前介绍的文件都是MySQL数据库本身的文件,和存储引擎无关。除了这些文件外,每个表存储引擎还有其自己独有的文件。本节将具体介绍与InnoDB存储引擎密切相关的文件,这些文件包括重做日志文件、表空间文件。
1.6.1 表空间文件
InnoDB采用将存储的数据按表空间(tablespace)进行存放的设计。在默认配置下会有一个初始大小为10MB,名为ibdata1的文件。该文件就是默认的表空间文件(tablespace file),又称作共享表空间,用户可以通过参数innodb_data_file_path对其进行设置,格式如下∶

用户可以通过多个文件组成一个表空间,同时制定文件的属性,如∶
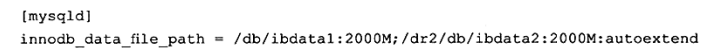
这里将/db/ibdata1和/dr2/db/ibdata2两个文件用来组成表空间。若这两个文件位于不同的磁盘上,磁盘的负载可能被平均,因此可以提高数据库的整体性能。同时,两个文件的文件名后都跟了属性,表示文件idbdata1的大小为2000MB,文件ibdata2的大小为2000MB,如果用完了这2000MB,该文件可以自动增长(autoextend)。
设置innodb_data_file_path参数后,所有基于InnoDB存储引擎的表的数据都会记录到该共享表空间中。若设置了参数innodb_file_per_table,则用户可以将每个基于InnoDB存储引擎的表产生一个独立表空间。独立表空间的命名规则为∶表名.ibd。通过这样的方式,用户不用将所有数据都存放于共享表空间中。
下面这台MySQL数据库服务器设置了innodb_file_per_table,故可以观察到∶
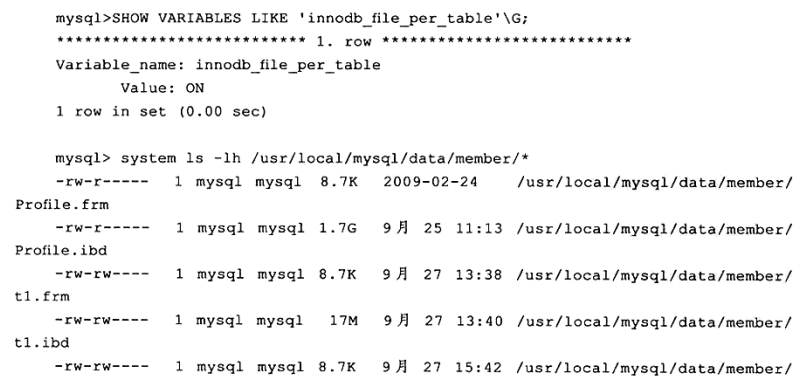
表Profile、t1和t2都是基于InnoDB存储的表,由于设置参数innodb_file_per_table=ON,因此产生了单独的.ibd独立表空间文件。
直到这里,我们知道了表空间有两种:
- 共享表文件:
innodb_data_file_path参数指向的ibdata1这种文件。 - 单独表文件:由于设置参数
innodb_file_per_table=ON,因此产生了单独的.ibd独立表空间文件。

需要注意的是,这些单独的表空间文件(tableName.ibd)仅存储该表的数据、索引和插入缓冲Bitmap等信息,其余信息,如回滚(undo)信息,插入缓冲索引页、系统事务信息,二次写缓冲(Double write buffer)等信息,还是存放在共享表空间(ibdata1文件)中。
下图显示了InnoDB存储引擎对于文件的存储方式
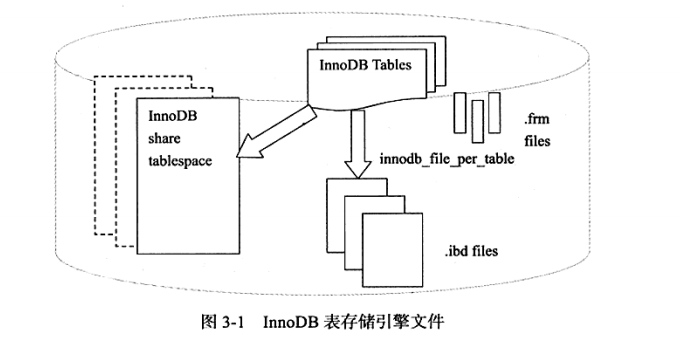
1.6.2 redo log文件
在默认情况下,在InnoDB存储引擎的数据目录下会有两个名为ib_logfile0和ib_logfile1的文件。在MySQL官方手册中将其称为InnoDB存储引擎的日志文件,不过更准确的定义应该是重做日志文件(redo log file)。为什么强调是重做日志文件呢?因为重做日志文件对于InnoDB存储引擎至关重要,它们记录了对于InnoDB存储引擎的事务日志。
当实例或介质失败(media failure)时,重做日志文件就能派上用场。例如,数据库由于所在主机掉电导致实例失败,InnoDB存储引擎会使用重做日志恢复到掉电前的时刻,以此来保证数据的完整性。
每个InoDB存储引擎至少有1个重做日志文件组(group),每个文件组下至少有2个重做日志文件,如默认的ib_logfile0和ib_logfile1。为了得到更高的可靠性,用户可以设置多个的镜像日志组(mirored log groups),将不同的文件组放在不同的磁盘上,以此提高重做日志的高可用性。在日志组中每个重做日志文件的大小一致,并以循环写入的方式运行。
InnoDB存储引擎先写重做日志文件1,当达到文件的最后时会切换至重做日志文件2,再当重做日志文件2也被写满时,会再切换到重做日志文件1中。
redo log文件详情,可见本站文章《【InnoDB详解四】redo log和undo log》
2 InnoDB存储结构
我们接下来将从InnoDB存储引擎表的逻辑存储及实现开始进行介绍,然后将重点分析表的物理存储特征,即数据在表中是如何组织和存放的。简单来说,表就是关于特定实体的数据集合,这也是关系型数据库模型的核心。
在InnoDB存储引擎中,表都是根据主键顺序组织存放的,这种存储方式的表称为索引组织表(index organized table)。在InnoDB存储引擎表中,每张表都有个主键(Primary Key),如果在创建表时没有显式地定义主键,则InnoDB存储引擎会按如下方式选择或创建主键∶
- 首先判断表中是否有非空的唯一索引(Unique NOTNULL),如果有,则该列即为主键。
- 如果不符合上述条件,InnoDB存储引擎自动创建一个6字节大小的指针。当表中有多个非空唯一索引时,InnoDB存储引擎将选择建表时第一个定义的非空唯一索引为主键。这里需要非常注意的是,主键的选择根据的是定义索引的顺序,而不是建表时列的顺序。
2.1 InnoDB逻辑存储结构
从 InnoDB存储引擎的逻辑存储结构看,所有数据都被逻辑地存放在一个空间中,称之为表空间(tablespace)。表空间又由段(segment)、区(extent)、页(page)组成。页在一些文档中有时也称为块(block),InnoDB存储引擎的逻辑存储结构大致如图4-1所示。
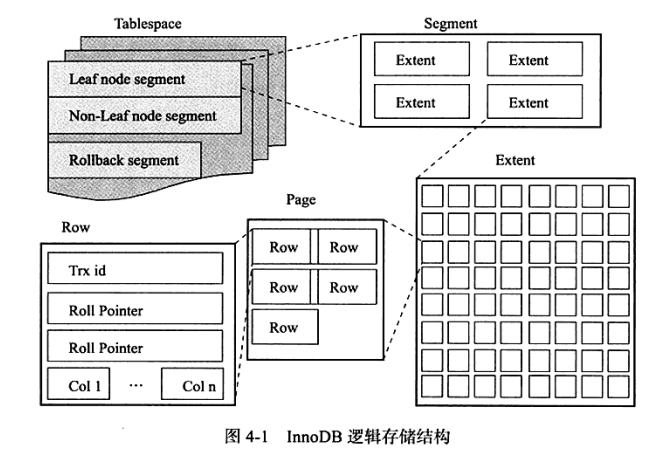
表空间可以看做是InnoDB存储引擎逻辑结构的最高层,所有的数据都存放在表空间中。前文我们已经介绍了表空间,并且知道了表空间分为共享表空间和独立表空间(若有),这里就不再赘述了。
2.1.1 段
图4-1中显示了表空间是由各个段组成的,常见的段有数据段、索引段、回滚段等。
因为前面已经介绍过了InnoDB存储引擎表是索引组织的(index organized),因此数据即索引,索引即数据。那么数据段即为B+树的叶子节点(图4-1的Leafnode segment),索引段即为B+树的非索引节点(图4-1的Non-leaf node segment)。
回滚段较为特殊,将会在后面的章节进行单独的介绍。
在InnoDB存储引擎中,对段的管理都是由引擎自身所完成,DBA不能也没有必要对其进行控制。这和Oracle数据库中的自动段空间管理(ASSM)类似,从一定程度上简化了DBA 对于段的管理。
2.1.2 区
区是由连续页组成的空间,在任何情况下每个区的大小都为1MB。为了保证区中页的连续性,InnoDB存储引擎一次从磁盘申请4~5个区。在默认情况下,InnoDB存储引擎页的大小为16KB,即一个区中一共有64个连续的页。
InnoDB1.0.x版本开始引入压缩页,即每个页的大小可以通过参数KEY_BLOCK_SIZE设置为2K、4K、8K,因此每个区对应页的数量就应该为512、256、128。
InnoDB 1.2.x版本新增了参数 innodb_page_size,通过该参数可以将默认页的大小设置为4K、8K,但是页中的数据库不是压缩。这时区中页的数量同样也为256、128。总之,不论页的大小怎么变化,区的大小总是为1M。
但是,这里还有这样一个问题∶在用户启用了参数innodb_file_per_talbe后,创建的表默认大小是96KB。区中是64个连续的页,创建的表的大小至少是1MB才对啊,这是什么原因呢?
其实这是因为在每个段开始时,先用32个页大小的碎片页(fragment page)来存放数据,在使用完这些页之后才是64个连续页的申请。这样做的目的是,对于一些小表,或者是undo这类的段,可以在开始时申请较少的空间,节省磁盘容量的开销。
2.1.3 页
同大多数数据库一样,InnoDB有页(Page)的概念(也可以称为块),页是InnoDB磁盘管理的最小单位。在InnoDB存储引擎中,默认每个页的大小为16KB。而从InnoDB 1.2.x版本开始,可以通过参数innodb_page_size将页的大小设置为4K、8K、16K。
若设置完成,则所有表中页的大小都为innodb_page_size,不可以对其再次进行修改。除非通过mysqldump导入和导出操作来产生新的库。
页是InnoDB磁盘管理的最小单位:
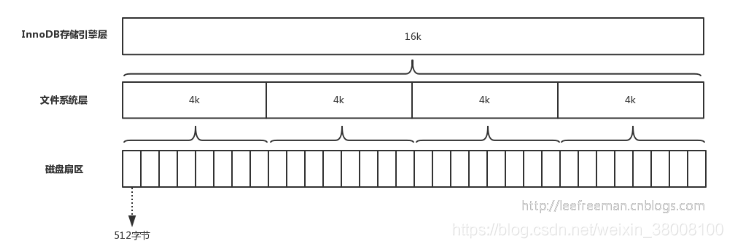
在计算机中磁盘存储数据最小单元是扇区,一个扇区的大小是512字节,而文件系统(例如XFS/EXT4)他的最小单元是块,一个块的大小是4k,InnoDB存储引擎一个页的大小是16K。
2.1.3.1 页的类型
在InnoDB存储引擎中,常见的页类型有∶
- 数据页(B-tree Node)
- undo页(undo Log Page)
- 系统页(System Page)
- 事务数据页(Transaction system Page)
- 插入缓冲bitmap页(Insert Buffer Bitmap)
- 插入缓冲空闲列表页(Insert Buffer Free List)
- 未压缩的二进制大对象页(Uncompressed BLOB Page)
- 压缩的二进制大对象页(compressed BLOB Page)
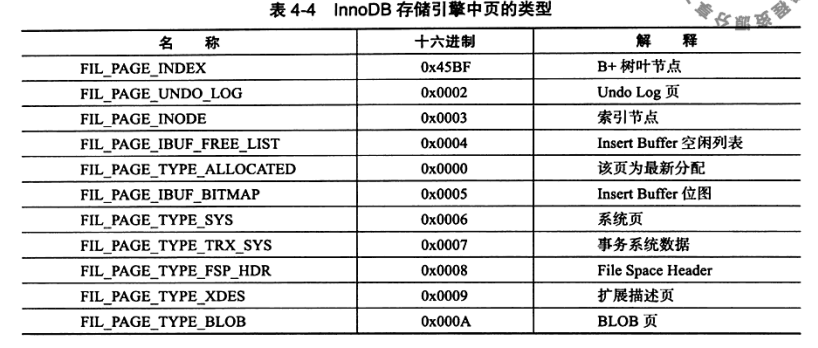
在页的File Header结构中,FIL_PAGE_TYPE字段被用来区分数据页的类型(后文会介绍),他们的值如下:
2.1.4 行
InnoDB存储引擎是面向列的(row-oriented),也就说数据是按行进行存放的。每个页存放的行记录也是有硬性定义的,最多允许存放16KB/2-200行的记录,即7992行记录。
这里提到了row-oriented的数据库,也就是说,存在有colum-riented的数据库。MySQL infobright存储引擎就是按列来存放数据的,这对于数据仓库下的分析类 SQL语句的执行及数据压缩非常有帮助。类似的数据库还有Sybase IQ、Google Big Table。面向列的数据库是当前数据库发展的一个方向,但这超出了本书涵盖的内容,有兴趣的读者可以在网上寻找相关资料。
2.2 InnoDB存储格式
2.2.1 InnoDB行记录格式
InnoDB存储引擎和大多数数据库一样(如 Oracle和Microsof SQL Server数据库),记录是以行的形式存储的。这意味着页中保存着表中一行行的数据。在InmoDB1.0x版本之前,InnoDB存储引擎提供了Compact和Redundant两种格式来存放行记录数据,这也是目前使用最多的一种格式。
Redundant格式是为兼容之前版本而保留的,如果阅读过InnoDB的源代码,用户会发现源代码中是用PHYSICALRECORD(NEW STYLE)和PHYSICALRECORD(OLD STYLE)来区分两种格式的。
在MySQL5.1版本中,默认设置为Compact行格式。用户可以通过命令SHOW TABLE STATUS LIKE’table_name’来查看当前表使用的行格式,其中row_format 属性表示当前所使用的行记录结构类型。如∶

可以看到,这里的mytest表是Compact的行格式,mytest2表是Redundant的行格式。
2.2.1.1 Compact类型格式
Compact行记录是在MySQL5.0中引入的,其设计目标是高效地存储数据。简单来说,一个页中存放的行数据越多,其性能就越高。下图显示了Compact行记录的存储方式∶

- 变长字段长度列表
- 这部分用来记录该行中每个varchar字段的长度(注意,只记录varchar字段的长度,单位是字节),假设数据行中会有n个varchar列,所以该部分也会对应存储n个长度值。
- 每个varchar列的长度一般用一个字节(对应字段真正长度 < 128字节),最多只能用两个字节(16 bit)(对应字段真正长度 >= 128字节)表示,所以在MySQL数据库中varchar类型的最大长度限制为65535字节(2的16次方)。
- 不过这里就有问题了,如果a列的长度占用1个字节,b列的长度占用两个字节,那解析的时候如何知道这三个字节的分界线呢?InnoDB规定如果某个字节最高位为0,那么这个字节就是独立的字节;如果某个字节最高位为1,那么就和它后面的字节共同表示一个长度(第二个字节可以用所有位表示长度)。也正是因为字节首位另有用处,所以一个字节最多表示长度为小于128。
- 所以如果a,b两列长度紧密排列,如
01111111 10000000 10000000,那就可以知道分界线是01111111 | 10000000 10000000。需要注意的是,MySQL采取 Little Endian 的计数方式,低位在前,高位在后,所以129用两个字节表示就是10000001 10000000。 - 变长字段长度列表中每个长度值的排序,和行中varchar列的顺序是相反的,也就是长度值在变长字段长度列表中是倒序存放
1
2
3
4
5
6
7
8
# 假如有三个字段 id,name,desc,age。其中name,desc是变长类型(Varchar)
|id|name|desc|age|
|1|wang|shuaige|18|
|2|li|meinv|20|
则磁盘里的存储为:
0x07 0x04 null值列表 数据头 1 wang shuaige 18 0x05 0x02 null值列表 数据头 2 li meinv 20
# 其中0x04表示name长度为4 ,0x07表示desc的长度为7,以此类推。
NULL标志位
- 该部分用来标记该行中哪些列的值是NULL值。
- 它是一个bitmap,一般占用1个字节(8 bit),它的每一位位指示了该行数据中对应的列是否是NULL值,有则用1表示。
- 比如NULL标志位如果为0x06,二进制是00000110,很显然第2位和第3位的值是1,那么就表示该行的第二列和第三列当前值为NULL。
- NULL标志位一般是占用1个字节,但如果列的数量大于8个,那么会多扩充一个字节,直到能涵盖所有的列。
记录头信息(record header)
- 固定占用5字节(40位),每位的含义见下图:
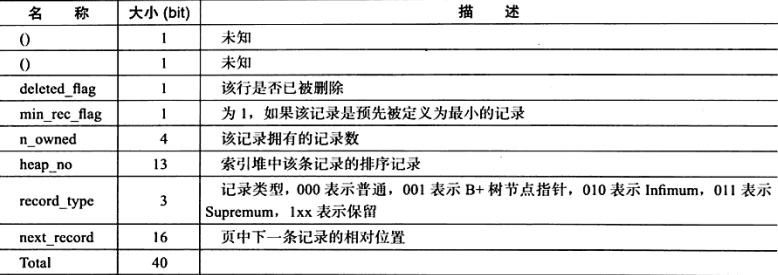
- 值得注意的是RecordHeader的最后两个字节,这16 bit是next_recorder,代表下一个记录的偏移量,假设该值为0x2c,那么它表示当前记录的位置加上偏移量0x2c就是下条记录的起始位置。所以InnoDB存储引擎在页内部是通过一种链表的结构来串连各个行记录的。
列数据
- 最后的部分就是实际存储每个列的数据。需要特别注意的是,NULL不占该部分任何空间,即NULL除了占有NULL标志位,实际存储不占有任何空间。
- 另外有一点需要注意的是,每行数据除了用户定义的列外,还有两个隐藏列,事务ID列和回滚指针列,分别为6字节和7字节的大小,这两个部分与InnoDB实现MVCC有关,版本控制、事务回滚等内容,这里不详述。若InnoDB表没有定义主键,每行还会增加一个6字节的rowid列。
我们来用一个实际的例子分析Compact行记录格式吧:
我们先定义一个表mytest,其中t1,t2,t4是变长的varchar类型,t3是固定长度的char类型
1 | CREATE TABLE `mytest` ( |
我们插入如下记录(其中–表示NULL):
1 | mysql> select * from mytest; |
然后将打开表空间文件mytest.ibd(这里启用了innodb_file_per_table,若没有启用该选项,打开默认的共享表空间文件 ibdata1)。
在Windows操作系统下,可以选择通过程序UltraEdit打开该二进制文件。在Linux 环境下,使用命令hexdump-C-v mytest.ibd>mytest.txt。这里将结果重定向到了文件mytes.txt,打开 mytest.txt文件,找到如下内容∶
1 | 0000c070 73 75 70 72 65 6d 75 6d 03 02 01 00 00 00 10 00|supremum…… |
第一行记录(a,bb,bb,ccc)从0000c078开始,我们整理一下,下面都是16进制数,如03就是0x03:
1 | 03 02 01/*变长字段长度列表,分别记录t1,t2,t4的长度,逆序*/ |
我们再来看有NULL值的第三行记录(d,NULL,NULL,fff),
1 | 03 01/*变长字段长度列表,逆序*/ |
可以发现不管是char还是varchar,NULL都不占用任何空间。
2.2.1.2 Redundant类型格式
Redundant是MySQL 5.0版本之前InnoDB的行记录存储方式,MySQL 5.0支持Redundant是为了兼容之前版本的页格式。Redundant行记录采用如下所示的方式存储。

- 字段长度偏移列表
- 不同于Compact行记录格式,Redundant行记录格式的首部是一个字段长度偏移列表,同样是按照列的顺序逆序放置的。
- 注意该列表记录的是每个列长度的偏移量,而不是长度值本身,比如某个字段长度偏移列表经整理后为
23 20 16 14 13 0c 06,因为是逆序排布,所以我们先翻为正序06,0c,13,14,16,20,23,那么这表示:第一列的长度是6,第二列的长度是6(6+6=0x0C),第三列的长度为7(6+6+7=0x13),第四列的长度是1(6+6+7+1=0x14),第五列的长度是2(6+6+7+1+2=0x16),第六列的长度是10(6+6+7+1+2+10=0x20),第七列的长度是3(6+6+7+1+2+10+3=0x23)。 - 同样的,长度列表中每个列的长度的偏移值一般用一个字节,最多用两个字节来存储。不过不同于compact格式,compact格式允许a列使用1个字节,b列使用两个字节,但是Redundant的话,要么所有列的偏移值都占用1字节,要么都占用2字节。
- 到底每个偏移使用1字节还是2字节,是根据整行记录的长度决定,如果整行长度小于 128,则用1字节存储,否则,用2字节。
- 如果是1字节存储的情况,那么每个字节最高的那个bit用来标记对应字段值是否为 NULL,如果为NULL,则最高位为1,否则为0。剩下的7位用来存储长度偏移量,所以最多是127。
- 对于两字节存储,首个字节的最高位还是用来标记对应字段值是否为NULL。最高的第二位则用来标记这条记录是否在同一页,如果在则为0,如果不在则为1,这其实就涉及到了后面要说的溢出页。剩下的连同第二个字节完整8bit在内的14bit表示长度,所以最多是16383
- 记录头信息(record header)
- 不同于Compact行记录格式,Redundant行记录格式的记录头占用6字节(48 位),每位的含义见下表
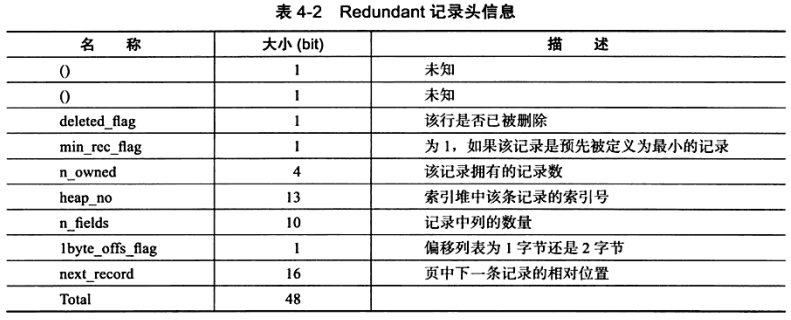
- 从中可以发现,n_fields值代表一行中列的数量,占用10位。同时这也很好地解释了为什么MySQL数据库一行支持最多的列为1023。因为2的10次方为1024
- 另一个需要注意的值为1byte_offs_flag,该值定义了字段长度偏移列表占用的是1字节还是2字节。
- 列数据
- 最后的部分就是实际存储每个列的数据。需要特别注意的是,varchar类型的NULL不占该部分任何空间,char类型的NULL占用固定空间。
- 另外有一点需要注意的是,每行数据除了用户定义的列外,还有两个隐藏列,事务ID列和回滚指针列,分别为6字节和7字节的大小,这两个部分与InnoDB实现MVCC有关,版本控制、事务回滚等内容,这里不详述。若InnoDB表没有定义主键,每行还会增加一个6字节的rowid列。
好,我们也来看下Redundant格式的例子,还是那张表和那些记录:
其中t1,t2,t4是变长的varchar类型,t3是固定长度的char类型
1 | mysql> select * from mytest; |
我们直接来看有NULL的第三行(下面都是16进制表示):
1 | a1 9e 94 14 13 0c 06/*长度偏移列表,逆序*/ |
可以看到:
- 来看长度偏移列表,
21 9e 94 14 13 0c 06翻转为正序是06 0c 13 14 94 9e 21,我们前面说过,每个字节中首位用来表示字段是否为NULL,后面7位才表示偏移值,这里需要将每个字节分成两部分(1bit | 7bit),并转化为十进制是0|6 0|12 0|19 0|20 1|20 1|30 0|33 - 该行中varchar类型的t2列,因为值为NULL,故而在Redundant格式中没有占用任何空间,所以我们看不到t2,t2位NULL的信息其实旨在长度偏移列表中体现了,也就是上文说到的
1|20这个字节。但同样为NULL值的t3数据,除了在偏移列表中体现外,却真的占用了10个字节,可见,在Redundant格式中,varchar类型的NULL不占用空间,char类型的NULL固定占用10字节空间。 - 记录头信息中应该注意48位中22~32位(n_fields),为0000000111,表示表共有7个列(包含了隐藏的3列),接下去的33位(1byte_offs_flag)为1,代表偏移列表中每个偏移量占用一个字节。
当前表mytest的字符集为Latin1,每个字符最多只占用1个字节。若这里将表mytest的字符集转换为utf8,则第三列char固定长度类型就不再是只占用10个字节了,而是10×3=30个字节,Redundant行格式下char固定字符类型将会占据可能存放的最大值字节数。
2.2.1.3 行溢出数据
InnoDB存储引擎可以将一条记录中的某些数据存储在数据页之外,而不是存放在行记录所在的当前页中,这类数据就叫行溢出数据。什么情况下会出现行溢出数据呢?答案是一个页(16K)放不下的时候,一些数据必然要溢出。
于是我们可以想到BLOB、LOB这类的大对象列类型的存储,InnoDB应该会把数据存放在数据页面之外。但是,这个理解有点偏差,其实BLOB、LOB这类的大对象并不一定非要溢出,而常见的varchar类型也并不一定不会溢出。
那么什么时候会产生行溢出数据呢?这个阈值是多少呢?
前文我们说过,数据页会被InnoDB以B+树的形式给整理起来,这就要求了:一个数据页中应该至少能存两条行记录(如果一个页只能存一行,那B+树就没有意义了,数据结构就成链表了)
基于这个要求,我们知道一个页为16KB,即16384字节,那么扣除掉页中如header,tail,dictionary等固定字段外,再对半分,则可以得出一行记录不发生行溢出的最大长度上限:8098字节。
那么,如果一行记录长度超过了8098字节,InnoDB又会如何存储呢?
在一般情况下,InnoDB存储引擎的数据都是存放在页类型为B-tree node(也就是数据页)的页中。但是当发生行溢出时,数据溢出部分存放在页类型为Uncompress BLOB的页中:
假设我们创建一个列a长度为65532的表t,并插入一条数据
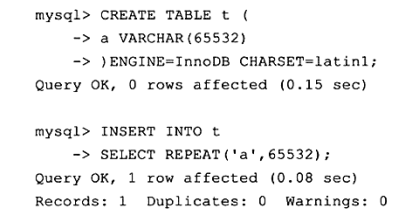
通过工具可以观察到表空间中有一个数据页节点B-tree Node,另外有4个未压缩的二进制大对象页Uncompressed BLOB Page,在这些页中才真正存放了65532字节的数据。既然实际存放的数据都在BLOB页中,那数据页中又存放了些什么内容呢?同样通过之前的 hexdump来读取表空间文件,从数据页c000开始查看∶

可以看到,从0x0000c093到0x000c392数据页面其实只保存了VARCHAR(65532)的前768字节的前缀(prefix)数据(这里都是a)。然后之后是行溢出页指针(20字节),指向行溢出页,也就是前面用户看到的Uncompressed BLOB Page。因此,对于行溢出数据,其存放采用下图的方式。
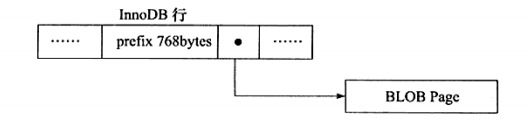
2.2.1.4 Compressed/Dynamic类型格式
InnoDB Plugin引入了新的文件格式(file format,可以理解为新的页格式),对于以前支持的Compact和Redundant格式将其称为Antelope文件格式,新的文件格式称为Barracuda。
Barracuda文件格式下拥有两种新的行记录格式Compressed和Dynamic两种。新的两种格式对于存放BLOB的数据采用了完全的行溢出的方式,在数据页中只存放20个字节的指针,实际的数据都存放在BLOB Page中,而之前的Compact和Redundant两种格式会存放768个前缀字节。
下图是Barracuda文件格式的溢出行:
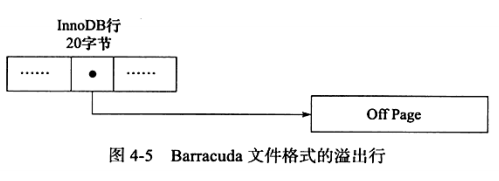
Compressed行记录格式的另一个功能就是,存储在其中的行数据会以zlib的算法进行压缩,因此对于BLOB、TEXT、VARCHAR这类大长度类型的数据能够进行非常有效的存储。
2.2.1.5 CHAR类型字段的存储
通常理解 VARCHAR是存储变长长度的字符类型,CHAR是存储固定长度的字符类型。而在前面的小节中,用户已经了解行结构的内部的存储,并可以发现每行的变长字段长度的列表都没有存储CHAR类型的长度。
然而,值得注意的是之前给出的两个例子中的字符集都是单字节的latin1格式。从MySQL4.1版本开始,CHAR(N)中的N指的是字符的个数,而不是之前版本的字节长度。也就说在不同的字符集下,CHAR类型列内部存储的可能不是定长的数据。
例如,对于UTF-8下CHAR(10)类型的列,其最小可以存储10字节的字符(都是拉丁字母),而最大可以存储30字节的字符(10个字符都是汉字)。因此,对于多字节字符编码的CHAR数据类型的存储,InnoDB存储引擎在内部将其视为VARCHAR变长字符类型。这也就意味着在变长长度列表中会记录CHAR 数据类型的长度。
因此可以认为在多字节字符集的情况下,CHAR和VARCHAR的实际行存储基本是没有区别的。
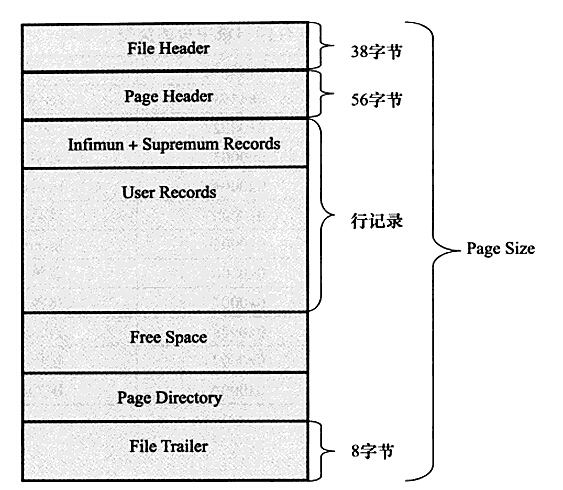
2.2.2 数据页的存储格式
我们已经知道页是InnoDB存储引擎管理数据库的最小磁盘单位。类型为B-tree Node的页存放的即是表中行的实际数据了。页的结构如下图所示:
2.2.2.1 File Header
File Header 字段用于记录 Page 的头信息。
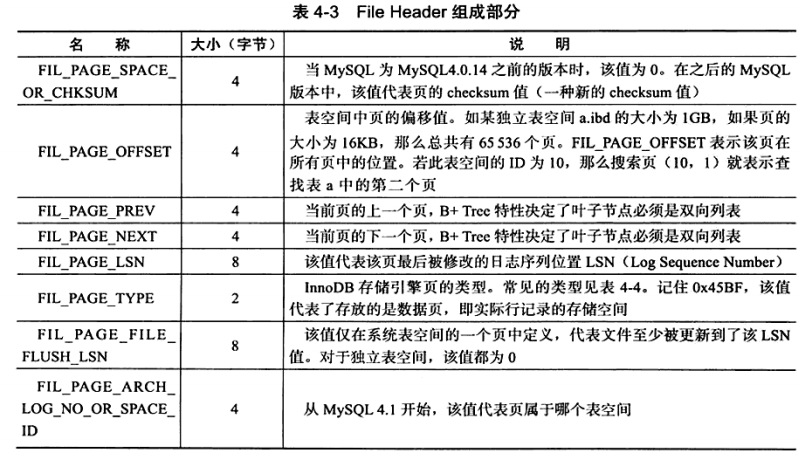
其中比较重要的是 FIL_PAGE_PREV 和 FIL_PAGE_NEXT 字段,它们分别是B+树叶子节点双向链表的前驱和后驱,通过这两个字段,我们可以找到该页的上一页和下一页,实际上所有页通过两个字段可以形成一条双向链表。
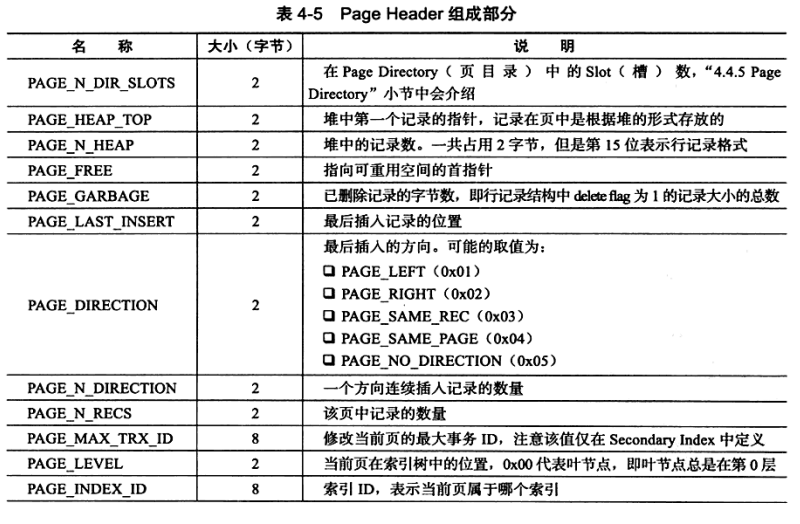
2.2.2.2 Page Header
Page Header 字段用于记录页的状态信息。

2.2.2.3 Infimum 和 Supremum
Infimum 和 Supremum 是两个虚拟的行记录,用来确定真实的行记录的边界。
Infimum(下确界)记录比该页中任何主键值都要小的值,Supremum (上确界)记录比该页中任何主键值都要大的值,这个虚拟记录分别构成了页中记录的边界。
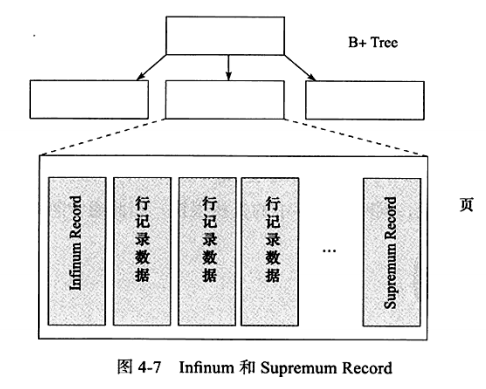
2.2.2.4 User Records
User Records 中存放的是实际的数据行记录,行记录的格式,我们在上文中已经介绍过了,有compact/redundant等格式。
我们再来复习一下,不论是什么格式,行记录都有一个记录头信息部分(record header)
记录头中各个字段如下图:
值得注意的是Record Header的最后两个字节,这16 bit是next_recorder,代表下一个记录的偏移量,假设该值为0x2c,那么它表示当前记录的位置加上偏移量0x2c就是下条记录的起始位置。所以行记录在User Records中是通过一种链表的结构来串连起来的。
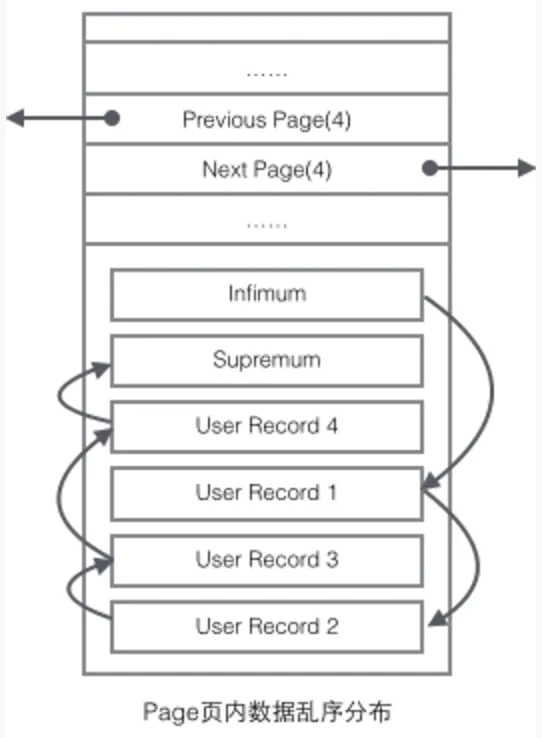
排序顺序一般是根据primary key升序放置。
2.2.2.5 Free Space
Free Space 中存放的是空闲空间,当一条行记录被删除后,它的空间会被加入到空闲列表中。
2.2.2.6 Page Directory
Page Directory 页目录,记录着与二叉查找相关的信息。
前面我们介绍了User Records是有序的,那么维护User Records的记录有序是为了做什么呢?没错,还是为了性能。行记录之间以链表串联,链表的查询性能是O(n),这显然是不够理想的,为了提升性能,Page Directory应运而生。
我们可以打个比方,我们在看书的时候,如果要找到某一节,而这一节我们并不知道在哪一页,我们是不是就要从前往后,一节一节地去寻找我们需要的内容的页码呢?
答案是否定的,因为在书的前面,存在目录,它会告诉你这一节在哪一页,例如,第一节在第1页、第二节在第13页。在数据库的页中,实际上也使用了这种目录的结构,这就是页目录。
那么引入页目录之后,我们所理解的页结构,就变成了这样:
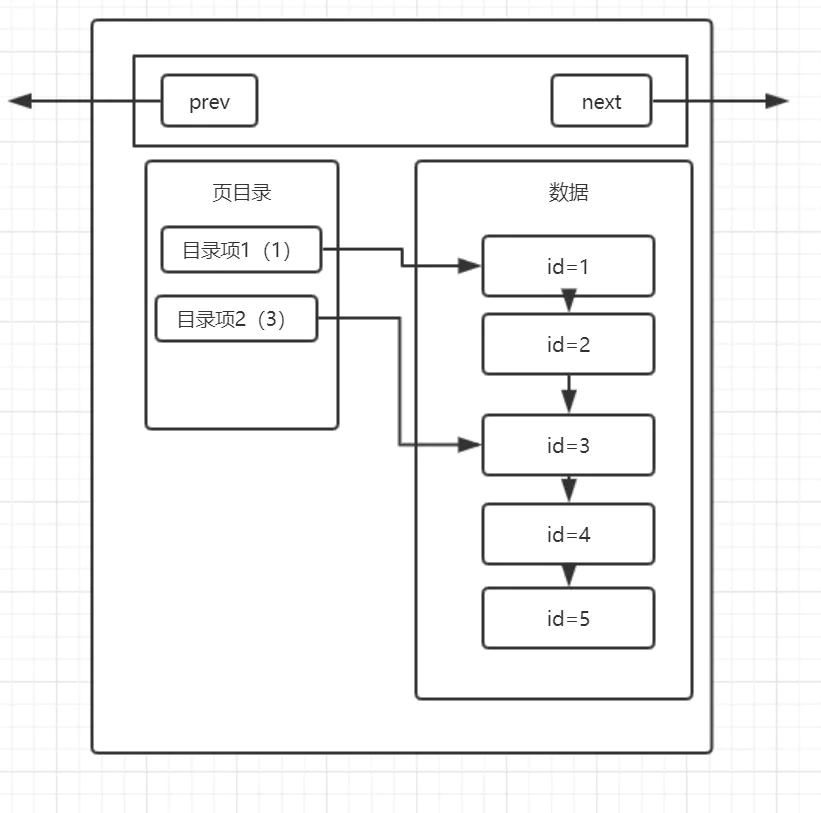
页目录是一个稀疏目录,它有限的目录项会离散的指向整个User Records列表的各个锚点,比如上图的目录项1指向id=1,目录项2指向id=3。
如此一来,假设我们要寻找id=5的数据,就不需要遍历一遍整个User Records列表了,只要通过页目录(假设是[1,3,7,10,...])定位到id=9是在7-10之间,那么就可以直接跳到id=7,之后再后溯两个行,就能定位到id=9。
2.2.2.7 File Trailer
File Trailer 存储用于检测数据完整性的校验和等数据。
为了检测页是否已经完整地写人磁盘(如可能发生的写人过程中磁盘损坏、机器关机等),InnoDB存储引擎的页中设置了File Trailer部分。
File Trailer只有一个FIL_PAGE_END_LSN部分,占用8字节。前4字节代表该页的checksum值,最后4字节和File Header中的FIL_PAGELSN相同。将这两个值与File Header中的FIL_PAGE_SPACE_OR_CHKSUM和FIL_PAGELSN值进行比较,看是否一致(checksum的比较需要通过InnoDB的checksum函数来进行比较,不是简单的等值比较),以此来保证页的完整性(not corrupted)。
2.2.3 索引和页的联系
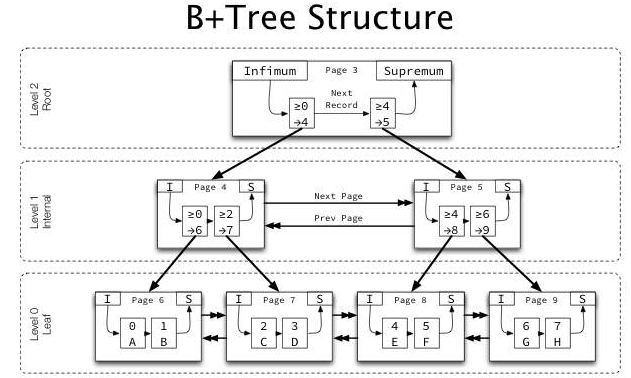
我们已经知道InnoDB的索引采用B+树来实现,B+树中的叶子节点和非叶子节点,其实它们也都是页,只不过叶子结点的页(我们称为索引页)只存放键值和指向非叶子节点(我们称为数据页)的偏移量:
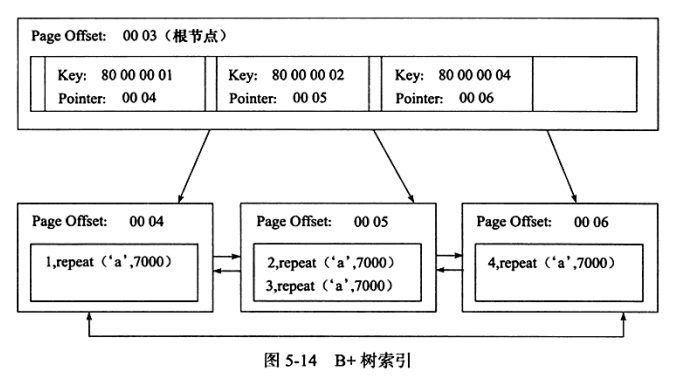

如上图可以看到,page 4/5/6都是叶子节点的数据页,他们存放实际的行记录。除此以外还有存放索引键值和指针的页,比如图中page number=3的页,该页存放键值和指向数据页的指针。这只是一个实例,实际上我们完整的B+树应该长这样:
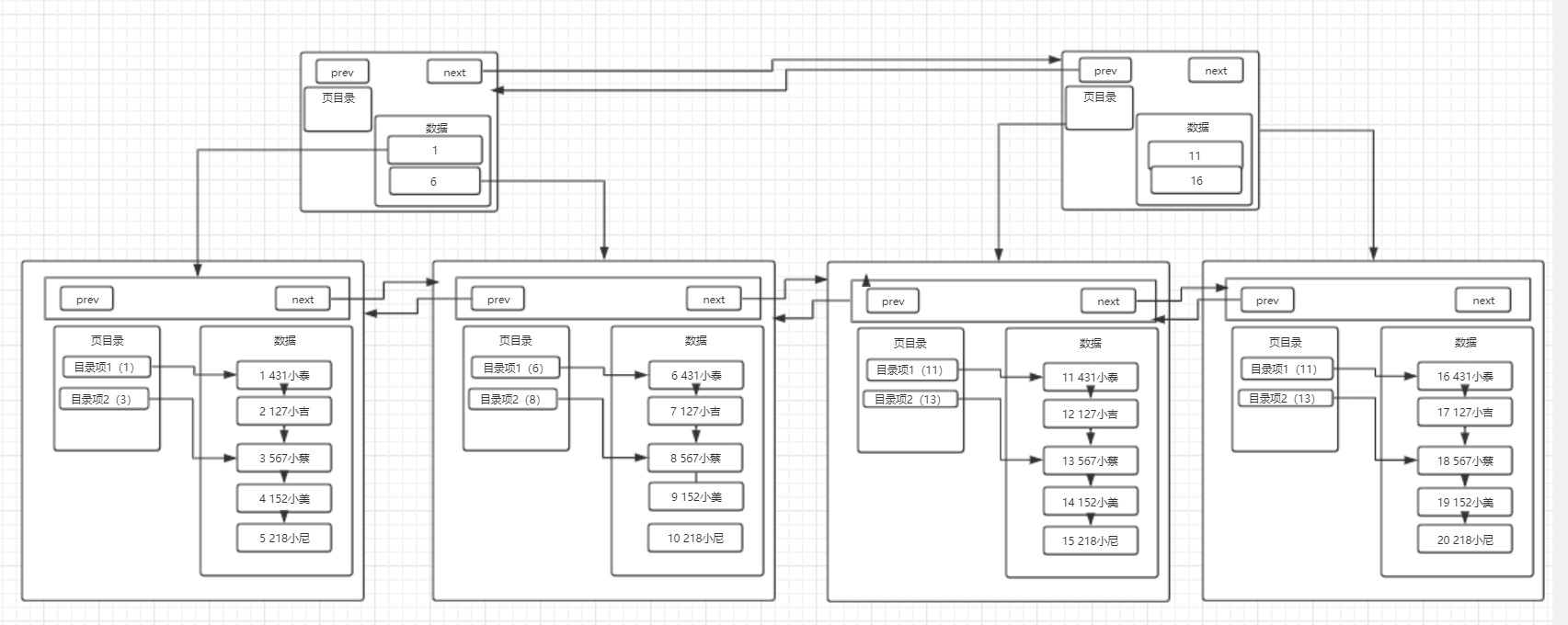
这些页都是被各种指针给逻辑地组成了一个B+树,他们实际上都离散的存放在磁盘上,也就是我们之前说的独立表空间文件中(tableName.idb文件中)。
当我们需要对某个页做读写的时候,再将某个页从磁盘载入缓冲池,缓冲池大小有限,所以会通过LRU List做淘汰机制,将不常用的页从缓冲池删除。
那么,假设现在要查找一条数据,该怎么查,比如:
select * from t1 where id=6;
在这里我们假设t1表选择自增id来做主键,这时要通过B+树来查找:
首先查找根页。一般来说,每个表的根页位置在表空间(t1.ibd)中都是不变的,在这里也就是page number=3的页,将page number=3的页载入缓冲池。
其实一般来说,根页只要进入缓冲池,就基本上都是热点数据,很难被LRU算法淘汰掉,因为基本上所有走t1表索引的查询,都要访问t1表的根页,即便是走非聚簇索引,也会定位到聚簇索引上来。
找到根页后通过二分查找法,定位到id=6的页应该在指针P5指向的页中。
需要牢记的是,B+树索引本身并不能找到具体的一条记录,能找到只是该记录所在的页。
如果P5指向的页(page number=5)不在缓冲池中,那么把页载入到缓冲池。
发现page number=5的页是非叶子节点了,然后通过Page Directory再进行二叉查找,即可查找到id=6的对应记录了。
Page Directory二叉查找的时间复杂度很低,同时在缓冲池(也就是内存)中的查找很快,因此通常忽略这部分查找所用的时间。
再看一张类似的图