前言
我们在日常的开发和维护工作中,免不了需要对JAVA程序进行监控、调优以及问题排查。
给一个系统定位问题的时候,知识、经验是关键基础,数据是依据,工具是运用知识处理数据的手段。这里说的数据包括∶运行日志、异常堆栈、GC日志、线程快照(thread dump/java core文件)、堆转储快照(heap dump/hprof文件)等。
经常使用适当的监控和分析工具可以加快我们分析数据、定位解决问题的速度,但在学习工具前,也应当意识到工具永远都是知识技能的一层包装,没有什么工具是”秘密武器”,不可能学会了就能包治百病。
进程id的获取
许多工具或者命令需要用到java进程的进程id,有必要回顾一下。
- 查看当前运行的所有的java进程:
ps -ef|grep java;- 准确获取定位到tomcat下正在运行的java进程的PID命令:
ps -ef|grep java | grep catalina | awk '{print $2}'- 准确定位到tomcat下正在运行的java进程相关信息:
ps -ef|grep java | grep catalina.
jinfo/jmap访问受限的解决
一般情况下,我们使用jinfo命令,可能会遇到如下的报错:
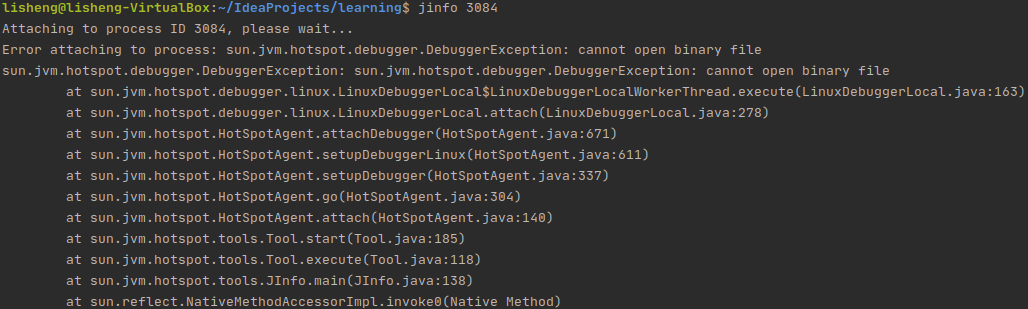
这是因为新版的Linux系统加入了 ptrace-scope 机制,该机制的目的是防止用户访问正在执行的进程的内存,但是如jinfo,jmap这些调试类工具本身就是利用ptrace来获取执行进程的内存等信息。
解决:
- 临时解决,该方法在下次重启前有效:
echo 0 | sudo tee /proc/sys/kernel/yama/ptrace_scope - 永久解决,直接修改内核参数:
sudo vi /etc/sysctl.d/10-ptrace.conf- 编辑这行:
kernel.yama.ptrace_scope = 1 - 修改为:
kernel.yama.ptrace_scope = 0 - 重启系统,使修改生效。
- 编辑这行:
参数名:kernel.yama.ptrace_scope(值为1:表示禁止用户访问正在执行的进程的内存;0表示可以访问)
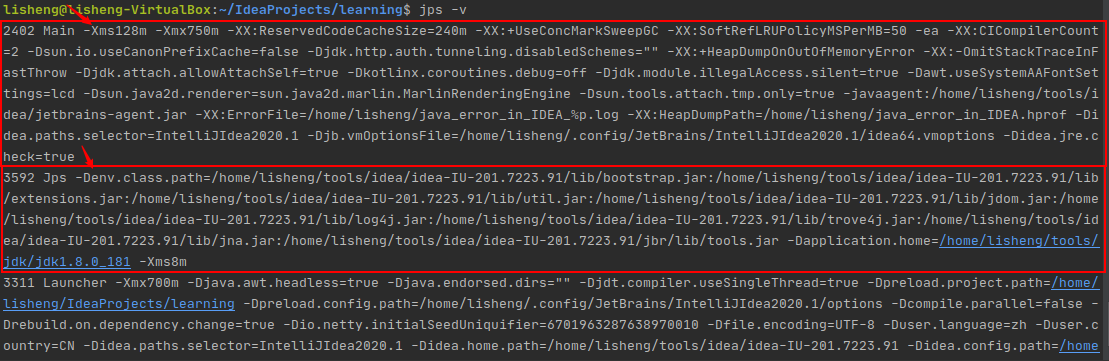
1 jps 显示JVM进程信息
jps (Java Virtual Machine Process Status Tool),是java提供的一个显示当前所有JAVA进程pid的命令,适合在linux/unix平台上简单察看当前java进程的一些简单情况。
我们常常会用到unix系统里的ps命令,这个命令主要是用来显示当前系统的进程情况,有哪些进程以及进程id。
jps就是java程序版本的ps命令,它的作用是显示当前系统的java进程情况及进程id。
格式:jps [-命令选项]

1.1 jps的选项
jps默认只会打印进程id和java类名,如果要更具体的信息,则要借助更多的选项:
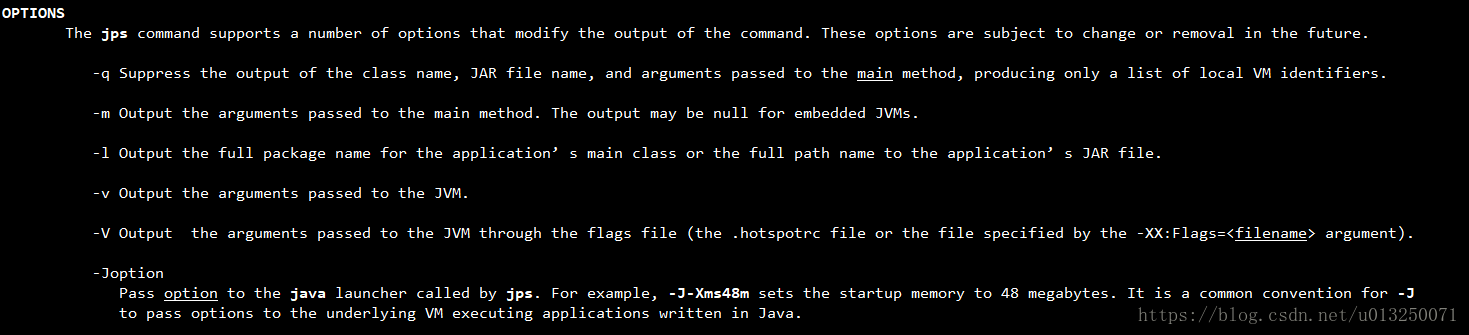
jps -q
- 只显示pid,不显示class名称,jar文件名和传递给main方法的参数

jps -m
- 输出传递给main方法的参数,在嵌入式jvm上可能是null
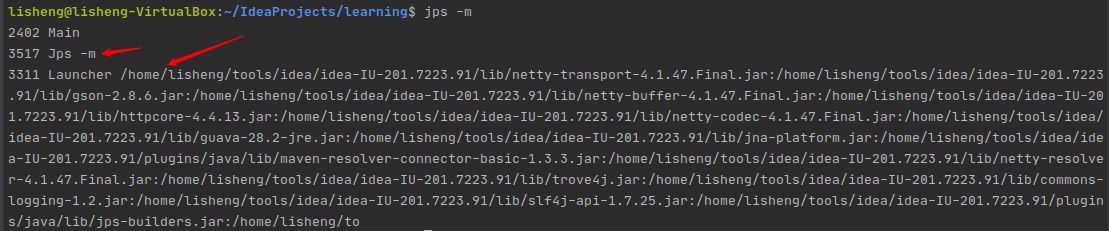
jps -l
- 输出应用程序main class的完整package名或者应用程序的jar文件完整路径名

jps -v
- 输出传递给JVM的参数
jps -V
- 隐藏输出传递给JVM的参数
2 jinfo 显示JVM配置信息
jinfo 是 JDK 自带的命令,可以用来查看正在运行的 java 应用程序的扩展参数,包括Java System属性和JVM命令行参数;也可以动态的修改正在运行的JVM一些参数。当系统崩溃时,jinfo也可以从core文件里面知道崩溃的Java应用程序的配置信息
1 | Usage: |
格式:jinfo [-命令选项] <pid> 或 jinfo [-命令选项] <executable core> 或 jinfo [-命令选项] [server_id@] <remote ip or hostname>
pid:对应jvm的进程idexecutable core:产生core dump文件remote server IP or hostname:远程调试服务的ip或者hostnameserver-id:唯一id,假如一台主机上多个远程debug服务;
Javacore,也可以称为“threaddump”或是“javadump”,它是 Java 提供的一种诊断特性,能够提供一份可读的当前运行的 JVM 中线程使用情况的快照。即在某个特定时刻,JVM 中有哪些线程在运行,每个线程执行到哪一个类,哪一个方法。
应用程序如果出现不可恢复的错误或是内存泄露,就会自动触发 Javacore 的生成。
jinfo工具特别强大,有众多的可选命令选项,比如:
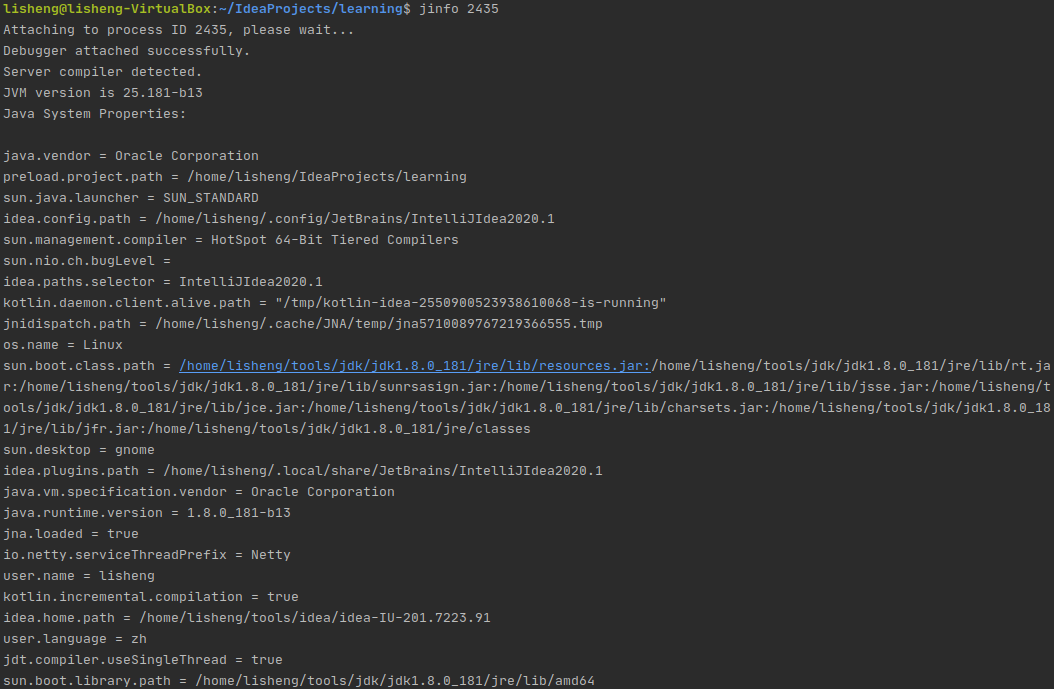
2.1 输出JVM进程的参数和属性
jinfo <pid>
不带任何选项的情况下,输出当前 jvm 进程的全部参数和系统属性
2.2 打印JVM特定参数的值
jinfo -flag <name> <pid>
用于打印虚拟机标记参数的值,name表示虚拟机标记参数的名称。

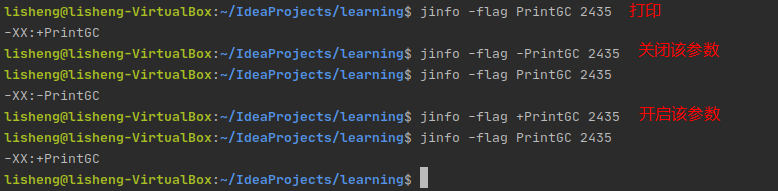
2.3 开启或关闭JVM特定参数
jinfo -flag [+|-]<name> <pid>
用于开启或关闭虚拟机标记参数。+表示开启,-表示关闭。
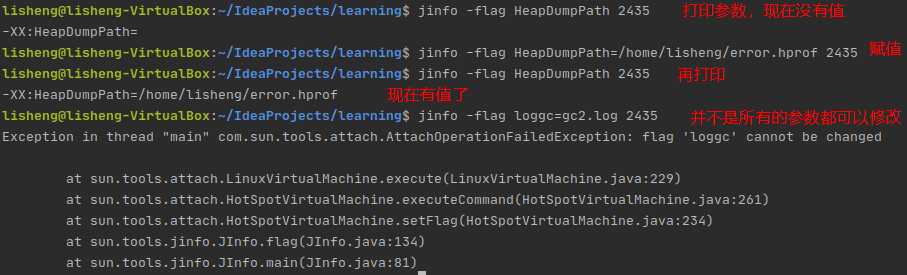
2.4 设置JVM特定参数的值
jinfo -flag <name>=<value> <pid>
用于设置虚拟机标记参数,但并不是每个参数都可以被动态修改的。
2.5 打印所有JVM参数
jinfo -flags <pid>
打印虚拟机参数。什么是虚拟机参数呢?如-XX:NewSize,-XX:OldSize等就是虚拟机参数。
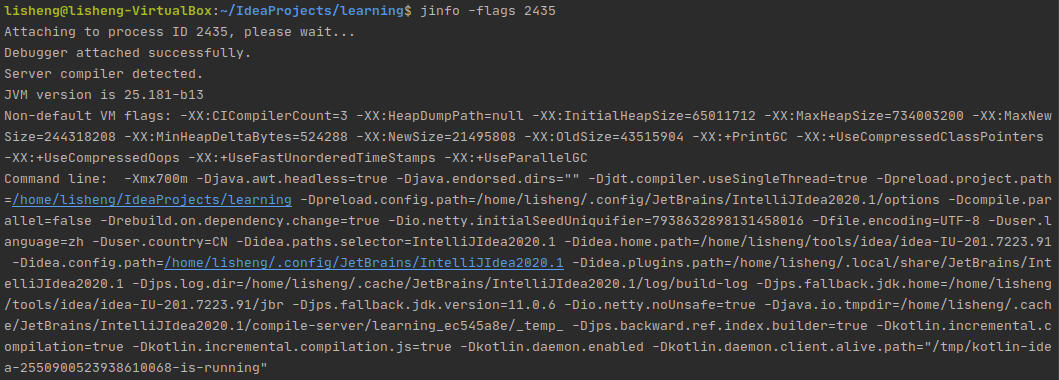
2.6 打印所有系统参数
jinfo -sysprops <pid>
打印所有系统参数
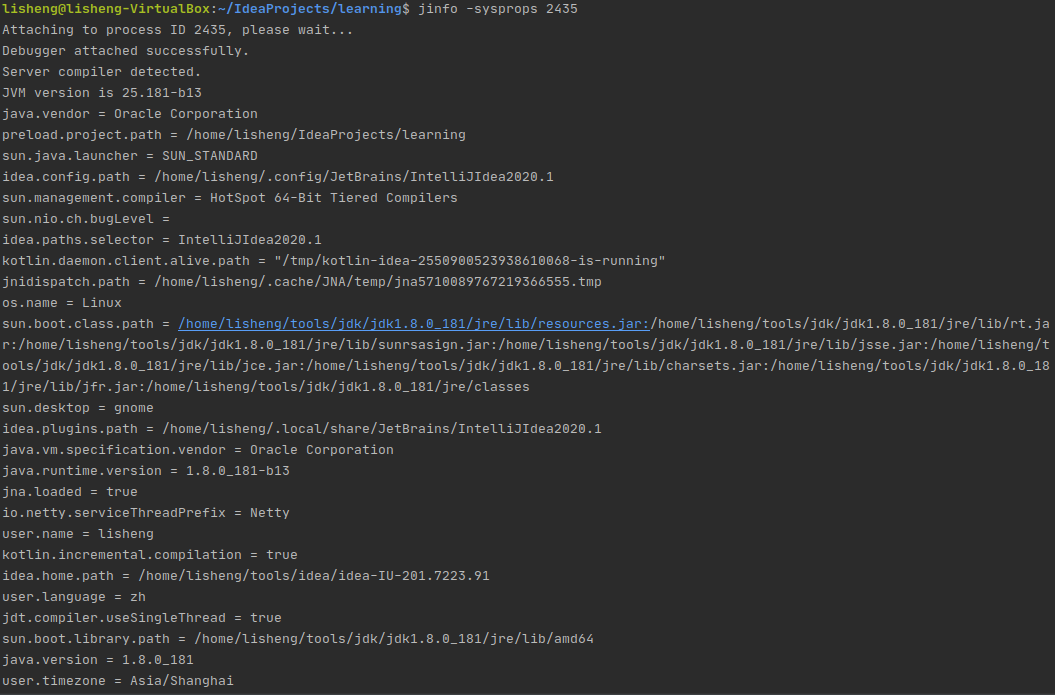
3 jmap 生成内存快照文件
jmap命令是一个可以输出所有内存中对象的工具,甚至可以将VM 中的heap,以二进制输出成文本。打印出某个java进程(使用pid)内存内的,所有‘对象’的情况(如:产生那些对象,及其数量)。
1 | Usage: |
64位机上使用需要使用如下方式:jmap -J-d64 -heap pid
格式:jmap [option] <pid> 或 jmap [option] <executable <core> 或 jmap [option] [server_id@]<remote server IP or hostname>
pid:对应jvm的进程idexecutable core:产生core dump文件remote server IP or hostname:远程调试服务的ip或者hostnameserver-id:唯一id,假如一台主机上多个远程debug服务;
jinfo工具特别强大,有众多的可选命令选项,比如:
3.1 输出hprof二进制格式的heap文件
jmap -dump:live,format=b,file=myjmapfile.txt <pid>
或jmap -dump:file=myjmapfile.hprof,format=b <pid>
使用hprof二进制形式,输出jvm的heap内容到文件,file=可以指定文件存放的目录。live子选项是可选的,假如指定live选项,那么只输出活的对象到文件。

3.2 打印正等候回收的对象的信息
jmap -finalizerinfo <pid>
打印正等候回收的对象的信息。

Number of objects pending for finalization: 0 表示等候回收的对象为0个
3.3 打印heap的概要信息
jmap -heap <pid>
打印heap的概要信息,GC使用的算法,heap(堆)的配置及JVM堆内存的使用情况。
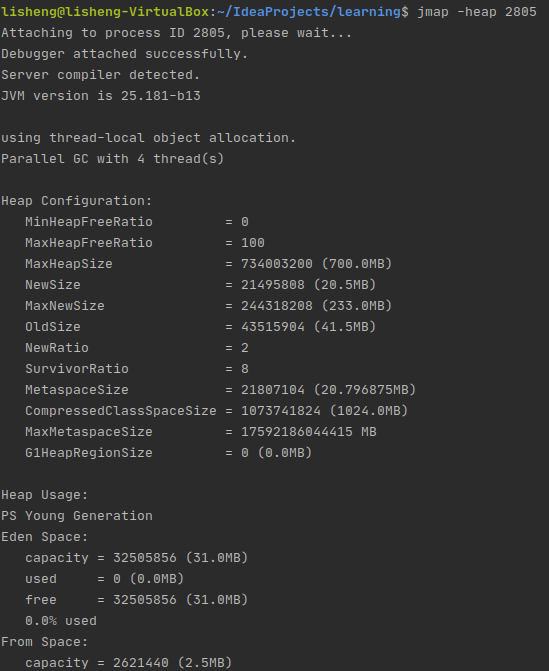
1 | Attaching to process ID 2805, please wait... |
3.4 打印每个class的实例信息
jmap -histo:live <pid>
或jmap -histo: <pid>
打印每个class的实例数目,内存占用,类全名信息,VM的内部类名字开头会加上前缀”*”。如果live子参数加上后,只统计活的对象数量
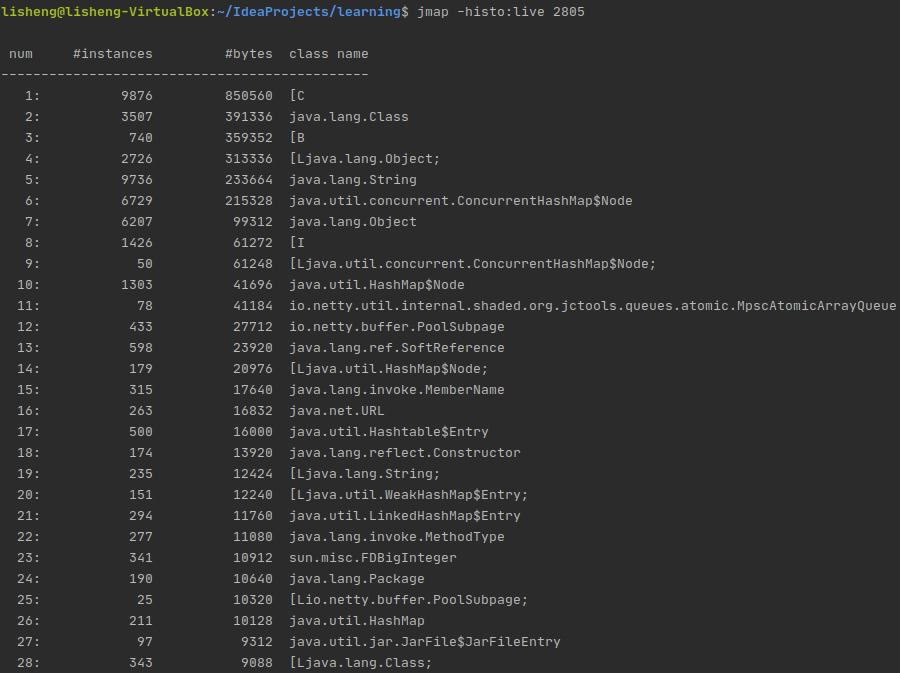
采用jmap -histo pid>a.log日志将其保存,在一段时间后,使用文本对比工具,可以对比出GC回收了哪些对象。
jmap -dump:format=b,file=outfile 3024可以将3024进程的内存heap输出出来到outfile文件里,再配合MAT(内存分析工具)。
3.5 打印类加载器的数据
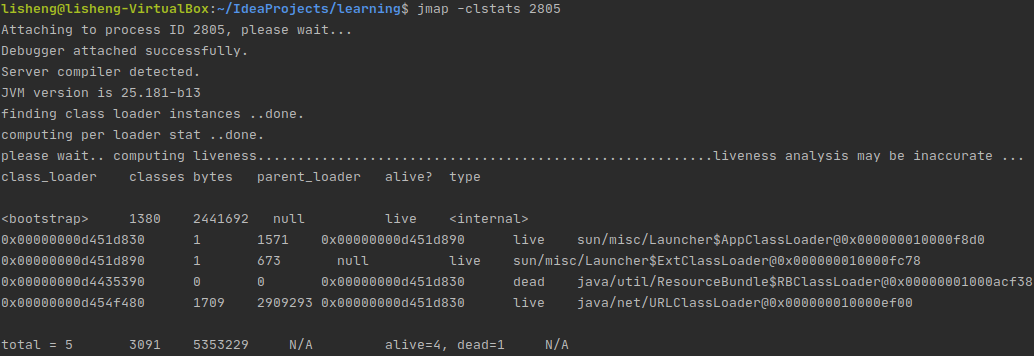
jmap -clstats <pid>
-clstats是-permstat的替代方案,在JDK8之前,-permstat用来打印类加载器的数据。打印Java堆内存的永久保存区域的类加载器的智能统计信息。
对于每个类加载器而言,它的名称、活跃度、地址、父类加载器、它所加载的类的数量和大小都会被打印。此外,包含的字符串数量和大小也会被打印。
3.6 指定传递给运行jmap的JVM的参数
jmap -J<flag> <pid>
指定传递给运行jmap的JVM的参数
如jmap -J-d64 -heap pid表示在64位机上使用jmap -heap
4 jstack 输出线程堆栈快照
jstack用于打印出给定的java进程ID或core file或远程调试服务的Java堆栈信息(也就是线程),如果是在64位机器上,需要指定选项”-J-d64”,Windows的jstack使用方式只支持以下的这种方式:jstack [-l] pid
如果java程序崩溃生成core文件,jstack工具可以用来获得core文件的java stack和native stack的信息,从而可以轻松地知道java程序是如何崩溃和在程序何处发生问题。
另外,jstack工具还可以附属到正在运行的java程序中,看到当时运行的java程序的java stack和native stack的信息,如果现在运行的java程序呈现hung的状态,jstack是非常有用的。
1 | Usage: |
格式:jstack [option] <pid> 或 jstack [option] <executable <core> 或 jstack [option] [server_id@]<remote server IP or hostname>
pid:对应jvm的进程idexecutable core:产生core dump文件remote server IP or hostname:远程调试服务的ip或者hostnameserver-id:唯一id,假如一台主机上多个远程debug服务;
jstack工具特别强大,有众多的可选命令选项和适用场景,比如:
4.1 程序没有响应时强制打印线程
jstack -F <pid>
当pid对应的程序没有响应时,强制打印线程堆栈信息。
4.2 打印完整的堆栈信息
jstack -l <pid>
长列表,打印关于锁的附加信息,例如属于java.util.concurrent的ownable synchronizers列表。
4.3 打印java/native框架的所有堆栈
jstack -m <pid>
打印java和native c/c++框架的所有栈信息。
4.4 jstack统计线程数
jstack -l 28367 | grep 'java.lang.Thread.State' | wc -l
4.5 jstack检测死锁
我们先写个死锁代码
1 | public class DeathLock { |
这个死锁会输出如下日志
1 | "mythread2" #12 prio=5 os_prio=0 tid=0x0000000058ef7800 nid=0x1ab4 waiting on condition [0x0000000059f8f000] |
4.6 jstack检测cpu高
步骤一:查看cpu占用高进程
1 | > top |
步骤二:查看cpu占用高线程
1 | > top -H -p 17850 |
步骤三:转换线程ID
1 | > printf "%x\n" 17880 |
步骤四:定位cpu占用线程
1 | jstack 17850|grep 45d8 -A 30 |
5 jstat 收集JVM运行数据
Jstat是JDK自带的一个轻量级小工具。全称“Java Virtual Machine statistics monitoring tool”,它位于java的bin目录下,主要利用JVM内建的指令对Java应用程序的资源和性能进行实时的命令行的监控,包括了堆内存各部分的使用量,以及加载类的数量,还有垃圾回收状况的监控。
可见,Jstat是轻量级的、专门针对JVM的工具。
格式:jstat [-命令选项] <pid>
jstat工具特别强大,有众多的可选项,详细查看堆内各个部分的使用量,以及加载类的数量。使用时,需加上查看进程的进程id,和所选参数。参考格式如下:
5.1 类加载统计
jstat –class <pid>
显示加载class的数量,及所占空间等信息。

| 显示列名 | 具体描述 |
|---|---|
| Loaded | 装载的类的数量 |
| Bytes | 装载类所占用的字节数 |
| Unloaded | 卸载类的数量 |
| Bytes | 卸载类的字节数 |
| Time | 装载和卸载类所花费的时间 |
5.2 编译统计
jstat -compiler <pid>
显示VM实时编译的数量等信息。

| 显示列名 | 具体描述 |
|---|---|
| Compiled | 编译任务执行数量 |
| Failed | 编译任务执行失败数量 |
| Invalid | 编译任务执行失效数量 |
| Time | 编译任务消耗时间 |
| FailedType | 最后一个编译失败任务的类型 |
| FailedMethod | 最后一个编译失败任务所在的类及方法 |
5.3 垃圾回收统计
jstat -gc <pid>
显示gc的信息,查看gc的次数,及时间。

| 显示列名 | 具体描述 |
|---|---|
| S0C | 年轻代中第一个survivor(幸存区)的容量 (字节) |
| S1C | 年轻代中第二个survivor(幸存区)的容量 (字节) |
| S0U | 年轻代中第一个survivor(幸存区)目前已使用空间 (字节) |
| S1U | 年轻代中第二个survivor(幸存区)目前已使用空间 (字节) |
| EC | 年轻代中Eden(伊甸区)的容量 (字节) |
| EU | 年轻代中Eden(伊甸区)目前已使用空间 (字节) |
| OC | Old代的容量 (字节) |
| OU | Old代目前已使用空间 (字节) |
| PC | Perm(持久代)的容量 (字节) |
| PU | Perm(持久代)目前已使用空间 (字节) |
| YGC | 从应用程序启动到采样时年轻代中gc次数 |
| YGCT | 从应用程序启动到采样时年轻代中gc所用时间(s) |
| FGC | 从应用程序启动到采样时old代(full gc)gc次数 |
| FGCT | 从应用程序启动到采样时old代(full gc)gc所用时间(s) |
| GCT | 从应用程序启动到采样时gc用的总时间(s) |
5.4 堆内存统计
jstat -gccapacity <pid>
显示VM内存中三代(young,old,perm)对象的使用和占用大小

| 显示列名 | 具体描述 |
|---|---|
| NGCMN | 年轻代(young)中初始化(最小)的大小(字节) |
| NGCMX | 年轻代(young)的最大容量 (字节) |
| NGC | 年轻代(young)中当前的容量 (字节) |
| S0C | 年轻代中第一个survivor(幸存区)的容量 (字节) |
| S1C | 年轻代中第二个survivor(幸存区)的容量 (字节) |
| EC | 年轻代中Eden(伊甸区)的容量 (字节) |
| OGCMN | old代中初始化(最小)的大小 (字节) |
| OGCMX | old代的最大容量(字节) |
| OGC | old代当前新生成的容量 (字节) |
| OC | old代的容量 (字节) |
| PGCMN | perm代中初始化(最小)的大小 (字节) |
| PGCMX | perm代的最大容量 (字节) |
| PGC | perm代当前新生成的容量 (字节) |
| PC | Perm(持久代)的容量 (字节) |
| YGC | 从应用程序启动到采样时年轻代中gc次数 |
| FGC | 从应用程序启动到采样时old代(full gc)gc次数 |
5.5 新生代垃圾回收统计
jstat -gcnew <pid>
统计年轻代对象的信息

| 显示列名 | 具体描述 |
|---|---|
| S0C | 年轻代中第一个survivor(幸存区)的容量 (字节) |
| S1C | 年轻代中第二个survivor(幸存区)的容量 (字节) |
| S0U | 年轻代中第一个survivor(幸存区)目前已使用空间 (字节) |
| S1U | 年轻代中第二个survivor(幸存区)目前已使用空间 (字节) |
| TT | 持有次数限制 |
| MTT | 最大持有次数限制 |
| DSS | 期望的幸存区大小 |
| EC | 年轻代中Eden(伊甸区)的容量 (字节) |
| EU | 年轻代中Eden(伊甸区)目前已使用空间 (字节) |
| YGC | 从应用程序启动到采样时年轻代中gc次数 |
| YGCT | 从应用程序启动到采样时年轻代中gc所用时间(s) |
5.6 新生代内存统计
jstat -gcnewcapacity <pid>
统计年轻代对象的信息及其占用量。

| 显示列名 | 具体描述 |
|---|---|
| NGCMN | 年轻代(young)中初始化(最小)的大小(字节) |
| NGCMX | 年轻代(young)的最大容量 (字节) |
| NGC | 年轻代(young)中当前的容量 (字节) |
| S0CMX | 年轻代中第一个survivor(幸存区)的最大容量 (字节) |
| S0C | 年轻代中第一个survivor(幸存区)的容量 (字节) |
| S1CMX | 年轻代中第二个survivor(幸存区)的最大容量 (字节) |
| S1C | 年轻代中第二个survivor(幸存区)的容量 (字节) |
| ECMX | 年轻代中Eden(伊甸区)的最大容量 (字节) |
| EC | 年轻代中Eden(伊甸区)的容量 (字节) |
| YGC | 从应用程序启动到采样时年轻代中gc次数 |
| FGC | 从应用程序启动到采样时old代(full gc)gc次数 |
5.7 老年代垃圾回收统计
jstat -gcold <pid>
统计老年代对象的信息

| 显示列名 | 具体描述 |
|---|---|
| MC | 方法区大小 |
| MU | 方法区使用大小 |
| CCSC | 压缩类空间大小 |
| CCSU | 压缩类空间使用大小 |
| OC | Old代的容量 (字节) |
| OU | Old代目前已使用空间 (字节) |
| YGC | 从应用程序启动到采样时年轻代中gc次数 |
| FGC | 从应用程序启动到采样时old代(full gc)gc次数 |
| YGCT | 从应用程序启动到采样时年轻代中gc所用时间(s) |
| GCT | 从应用程序启动到采样时gc用的总时间(s) |
5.8 老年代内存统计
jstat -gcoldcapacity <pid>
统计老年代对象的信息及其占用量

| 显示列名 | 具体描述 |
|---|---|
| OGCMN | old代中初始化(最小)的大小 (字节) |
| OGCMX | old代的最大容量(字节) |
| OGC | old代当前新生成的容量 (字节) |
| OC | Old代的容量 (字节) |
| YGC | 从应用程序启动到采样时年轻代中gc次数 |
| FGC | 从应用程序启动到采样时old代(full gc)gc次数 |
| YGCT | 从应用程序启动到采样时年轻代中gc所用时间(s) |
| GCT | 从应用程序启动到采样时gc用的总时间(s) |
5.9 元数据空间统计
jstat -gcmetacapacity <pid>
统计元数据空间容量

| 显示列名 | 具体描述 |
|---|---|
| MCMN | 最小元数据容量 |
| MCMX | 最大元数据容量 |
| MC | 方法区大小 |
| CCSMN | 最小压缩类空间大小 |
| CCSMX | 最大压缩类空间大小 |
| CCSC | 压缩类空间大小 |
| YGC | 从应用程序启动到采样时年轻代中gc次数 |
| FGC | 从应用程序启动到采样时old代(full gc)gc次数 |
| FGCT | 从应用程序启动到采样时old代(full gc)gc所用时间(s) |
| GCT | 从应用程序启动到采样时gc用的总时间(s) |
5.10 总结垃圾回收统计
jstat -gcutil <pid>
统计gc容量占比信息

| 显示列名 | 具体描述 |
|---|---|
| S0 | 年轻代中第一个survivor(幸存区)已使用的占当前容量百分比 |
| S1 | 年轻代中第二个survivor(幸存区)已使用的占当前容量百分比 |
| E | 年轻代中Eden(伊甸区)已使用的占当前容量百分比 |
| O | old代已使用的占当前容量百分比 |
| P | perm代已使用的占当前容量百分比 |
| YGC | 从应用程序启动到采样时年轻代中gc次数 |
| YGCT | 从应用程序启动到采样时年轻代中gc所用时间(s) |
| FGC | 从应用程序启动到采样时old代(full gc)gc次数 |
| FGCT | 从应用程序启动到采样时old代(full gc)gc所用时间(s) |
| GCT | 从应用程序启动到采样时gc用的总时间(s) |
5.11 JVM编译方法统计
jstat -printcompilation <pid>
统计 JVM编译方法的信息

| 显示列名 | 具体描述 |
|---|---|
| Compiled | 最近编译方法的数量 |
| Size | 最近编译方法的字节码数量 |
| Type | 最近编译方法的编译类型。 |
| Method | 方法名标识 |
6 jhat 堆快照文件可视化工具
jhat(Java Virtual Machine Heap Analysis Tool)虚拟机堆转储快照分析工具,也是jdk内置的工具之一,是个用来分析java堆内存的命令,它会建立一个HTTP/HTML服务器,让用户可以在浏览器上查看分析结果,包括对象的数量,大小等等,并支持对象查询语言(OQL)。
jhat的作用对象是堆快照文件,也就是dump文件或者hprof文件,文件生成后,我们再使用jaht进行分析。
使用jmap命令获取java程序堆快照(生成dump文件)
使用jconsole选项通过
HotSpotDiagnosticMXBean从运行时获得堆快照(生成dump文件)虚拟机启动时如果指定了
-XX:+HeapDumpOnOutOfMemoryError选项, 则在抛出OutOfMemoryError时, 会自动执行堆快照(生成dump文件)使用 hprof 命令获得hprof文件(生成hprof文件)
用法:jhat [ options ] heap-dump-file,如jhat -J-Xmx512M app.dump
option具体选项及作用如下:
- -J< flag > 因为 jhat 命令实际上会启动一个JVM来执行, 通过 -J 可以在启动JVM时传入一些启动参数. 例如, -J-Xmx512m 则指定运行 jhat 的Java虚拟机使用的最大堆内存为 512 MB. 如果需要使用多个JVM启动参数,则传入多个 -Jxxxxxx
- -stack false|true 关闭跟踪对象分配调用堆栈。如果分配位置信息在堆转储中不可用. 则必须将此标志设置为 false. 默认值为 true.
- -refs false|true 关闭对象引用跟踪。默认情况下, 返回的指针是指向其他特定对象的对象,如反向链接或输入引用(referrers or incoming references), 会统计/计算堆中的所有对象。
- -port port-number 设置 jhat HTTP server 的端口号. 默认值 7000。
- -exclude exclude-file 指定对象查询时需要排除的数据成员列表文件。 例如, 如果文件列出了 java.lang.String.value , 那么当从某个特定对象 Object o 计算可达的对象列表时, 引用路径涉及 java.lang.String.value 的都会被排除。
- -baseline exclude-file 指定一个基准堆转储(baseline heap dump)。 在两个 heap dumps 中有相同 object ID 的对象会被标记为不是新的(marked as not being new). 其他对象被标记为新的(new). 在比较两个不同的堆转储时很有用。
- -debug int 设置 debug 级别. 0 表示不输出调试信息。 值越大则表示输出更详细的 debug 信息。
- -version 启动后只显示版本信息就退出。
有时dump出来的堆很大,在启动时会报堆空间不足的错误,可加参数:
jhat -J-Xmx512m <heap dump file>。这个内存大小可根据自己电脑进行设置。
不过实事求是地说,在实际工作中,除非真的没有别的工具可用,否则一般不会去直接使用jhat命令来分析demp文件,主要原因有二:
- 一是一般不会在部署应用程序的服务器上直接分析dump文件,即使可以这样做,也会尽量将dump文件拷贝到其他机器上进行分析,因为分析工作是一个耗时且消耗硬件资源的过程,既然都要在其他机器上进行,就没必要受到命令行工具的限制了;
- 另外一个原因是jhat的分析功能相对来说很简陋,VisualVM以及专门分析dump文件的Eclipse Memory Analyzer、IBM HeapAnalyzer等工具,都能实现比jhat更强大更专业的分析功能。
6.1 jhat工具的开启
- 使用jps获取java应用的pid
1 | $ jps |
使用jmap获取dump文件
1
2
3$ jmap -dump:file=test.dump,format=b 43228
> Dumping heap to D:\projects\i-lupro-app\test.dump ...
> Heap dump file created使用jhat分析dump文件
1
2
3
4
5
6
7
8
9
10$ jhat -J-Xmx512M test.dump
> Reading from test.dump...
> Dump file created Wed Nov 25 18:48:51 CST 2020
> Snapshot read, resolving...
> Resolving 197329 objects...
> Chasing references, expect 39 dots.......................................
> Eliminating duplicate references.......................................
> Snapshot resolved.
> Started HTTP server on port 7000
> Server is ready.在浏览器打开
http://localhost:7000/开启可视化工具
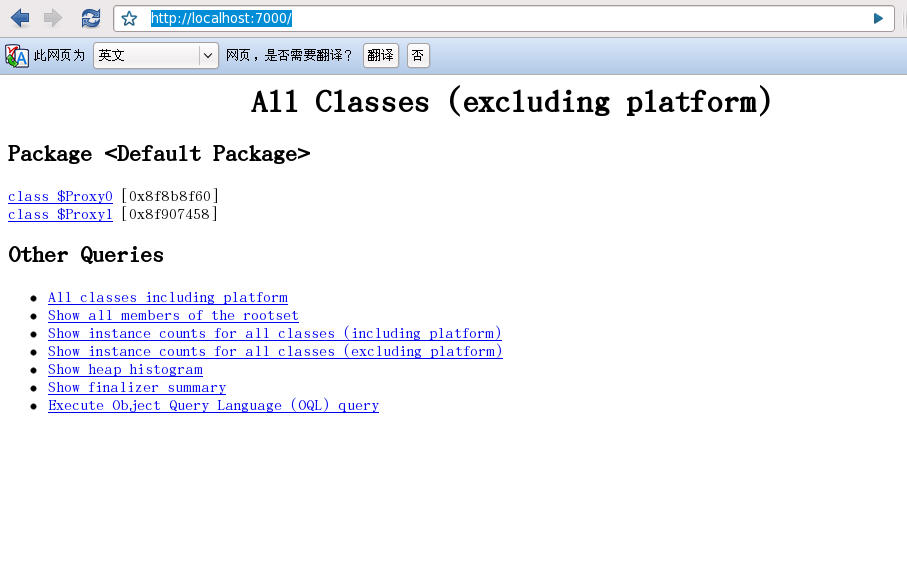
6.2 jhat工具的功能
6.2.1 显示出堆中所包含的所有的类
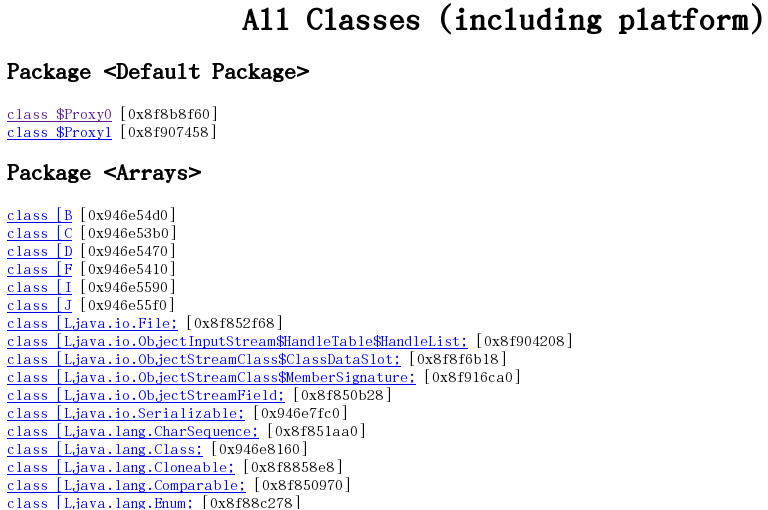
6.2.2 从根集能引用到的对象

6.2.3 显示平台包括的所有类的实例数量
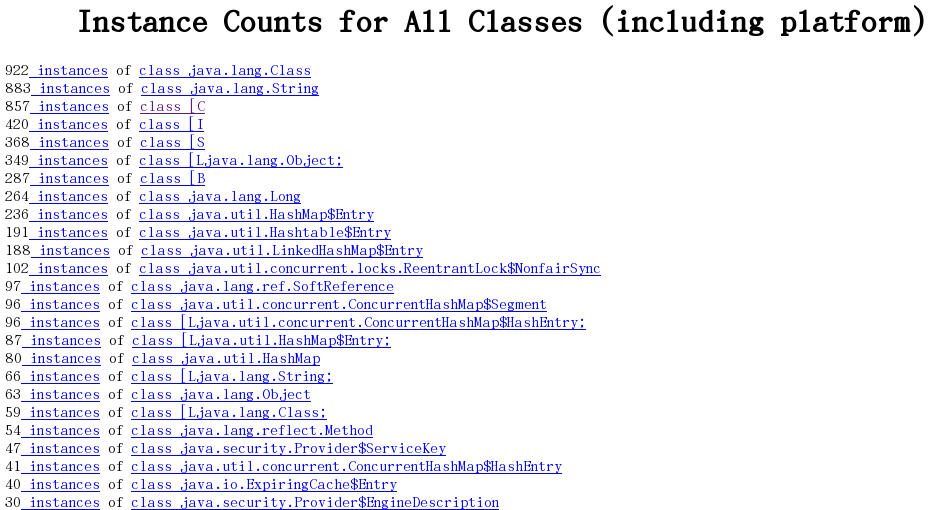
6.2.4 堆实例的分布表
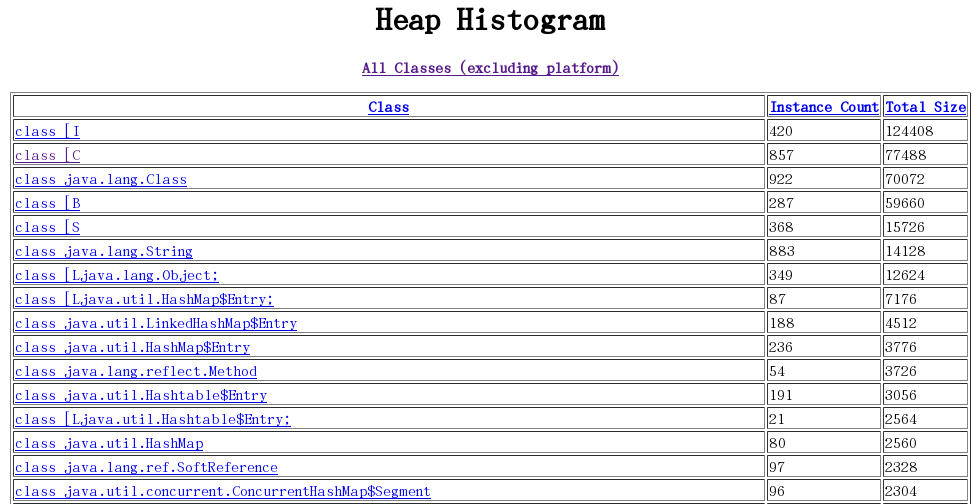
6.2.5 执行对象查询语句(OQL)
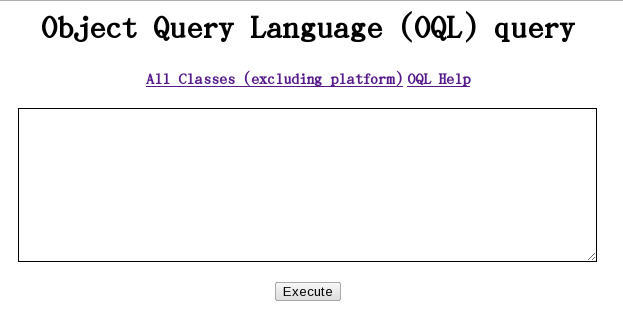
其输入内容如:
1 | # 查询长度大于100的字符串 |
详细的OQL可点击上图的“OQL help”
7 jconsole 可视化监控控制台
Jconsole(Java Monitoring and Management Console),一种基于JMX的可视化监视、管理工具。
7.1 启动JConsole
- 点击JDK/bin 目录下面的jconsole.exe 即可启动
- 然后会自动自动搜索本机运行的所有虚拟机进程。
- 选择其中一个进程可开始进行监控
7.2 JConsole介绍
JConsole 基本包括以下基本功能:概述、内存、线程、类、VM概要、MBean
7.2.1 概览
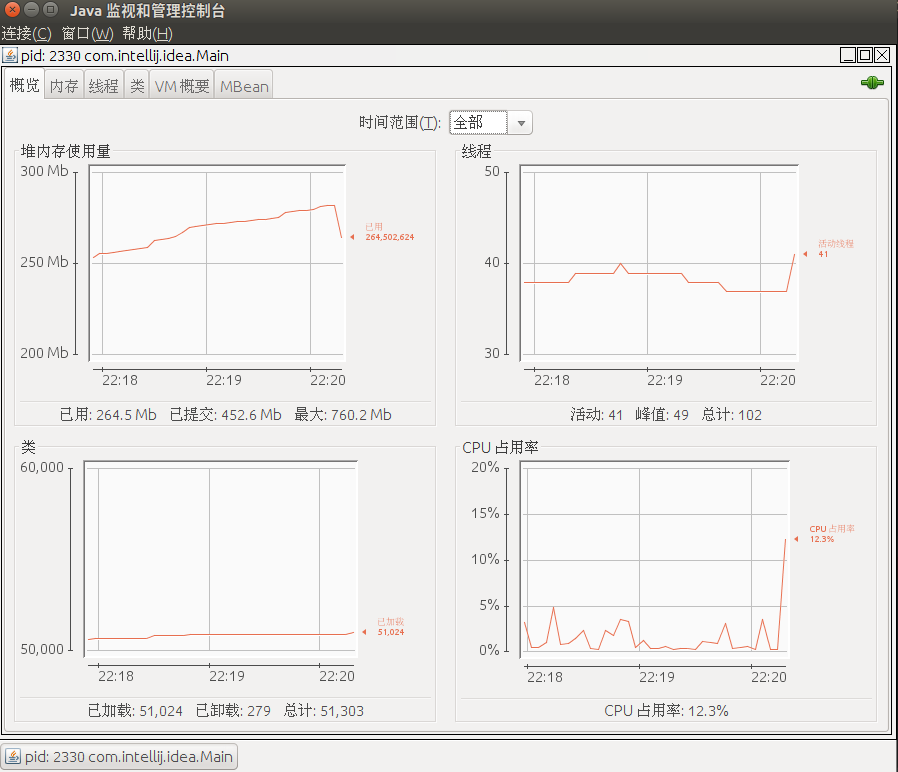
7.2.2 内存监控
内存页签相对于可视化的jstat 命令,用于监视受收集器管理的虚拟机内存。
jconsole可监控的内存有许多,如下图

我们以堆内存为例:
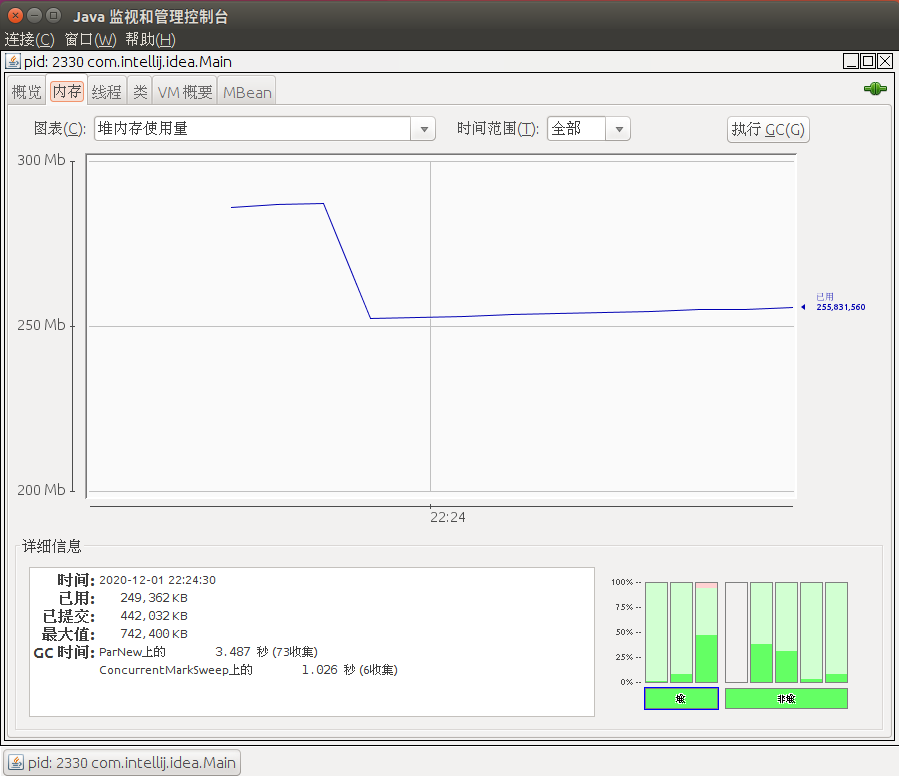
| 选项 | 值 | 描述 |
|---|---|---|
| 堆内存的大小 | 442032KB | |
| 已使用 | 249362KB | 目前使用的内存量,包括所有对象,可达和不可达占用的内存。 |
| 已提交 | 442032KB | 保证由Java虚拟机使用的内存量。 提交的内存量可能会随时间而改变。 Java虚拟机可能会释放系统内存,并已提交的内存量可能会少于最初启动时分配的内存量。 提交的内存量将始终大于或等于使用的内存量。 |
| 最大值 | 742400KB | 可用于内存管理的最大内存量。 它的价值可能会发生变化,或者是不确定的。 如果Java虚拟机试图增加使用的内存要大于提交的内存,内存分配可能失败,即使使用量小于或等于最大值(例如,当系统上的虚拟内存不足)。 |
| GC时间 | parnew上的 3.487s(73收集) | 累计时间花在垃圾收集和调用的总数。 它可能有多个行,其中每一个代表一个垃圾收集器算法在Java虚拟机的总耗时和执行次数 |
| 堆 | – | 堆内存是运行时数据区域,Java VM的所有类实例和数组分配内存。 可能是固定或可变大小的堆。 |
| 非堆内存 | – | 非堆内存包括在所有线程和Java虚拟机内部处理或优化所需的共享的方法。 它存储了类的结构,运行常量池,字段和方法数据,以及方法和构造函数的代码,方法区在逻辑上是堆的一部分,看具体实现的方式。根据实现方式的不同,Java虚拟机可能不进行垃圾收集或压缩。 堆内存一样,方法区域可能是一个固定或可变大小。 方法区的内存不需要是连续的。 |
除了方法区,Java虚拟机可能需要进行内部处理或优化,这也属于非堆内存的内存。 例如,实时(JIT)编译器需要内存用于存储从Java虚拟机的高性能的代码翻译的机器码。
7.2.3 线程监控
如果上面的“内存”页签相当于可视化的jstat命令的话,“线程”页签的功能相当于可视化的jstack命令,遇到线程停顿时可以使用这个页签进行监控分析。
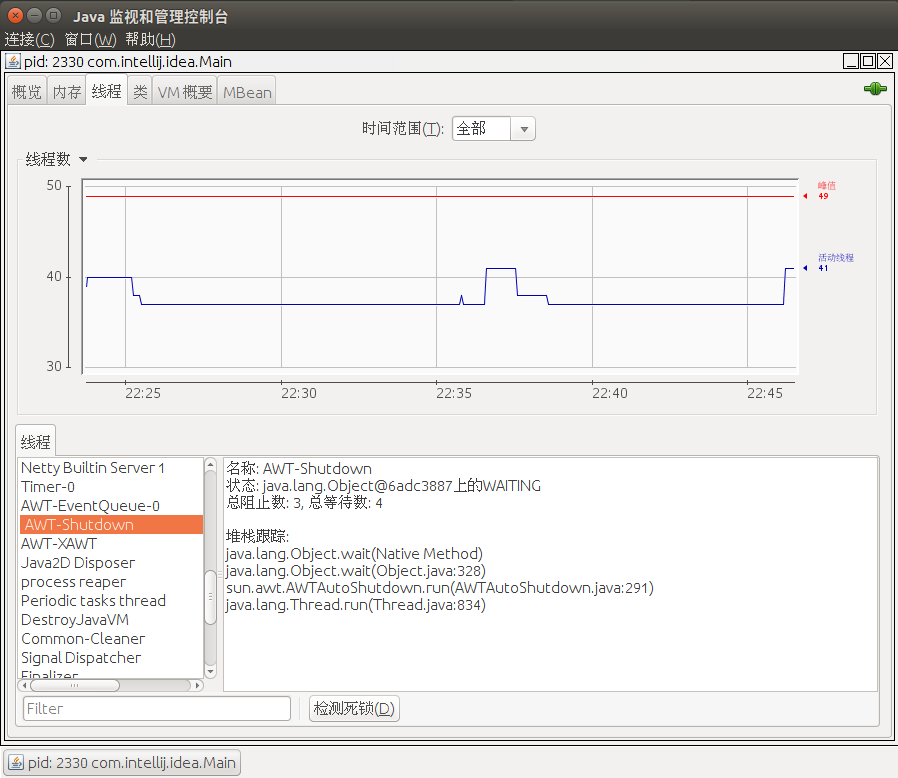
在左下角的“线程”列表列出了所有的活动线程。 如果你输入一个“filter”字段中的字符串,线程列表将只显示其名称中包含你输入字符串线程。 点击一个线程在线程列表的名称,显示该线程的信息的权利,包括线程的名称,状态、阻塞和等待的次数、堆栈跟踪。
如果要检查您的应用程序已经陷入死锁的线程,可以通过点击“检测死锁”按钮检测。线程长时间停顿的主要原因主要有:等待外部资源(数据库连接、网络资源、设备资源等)、死循环、锁等待(活锁和死锁)
我们写个死锁代码
1 | package com.jvm; |
这段代码开了200个线程去分别计算1+2以及2+1的值,其实for循环是可省略的,两个线程也可能会导致死锁,不过那样概率太小,需要尝试运行很多次才能看到效果。一般的话,带for循环的版本最多运行2~3次就会遇到线程死锁,程序无法结束。
造成死锁的原因是Integer.valueOf()方法基于减少对象创建次数和节省内存的考虑,
[-128,127]之间的数字会被缓存,当valueOf()方法传入参数在这个范围之内,将直接返回缓存中的对象。也就是说,代码中调用了200次Integer.valueOf()方法一共就只返回了两个不同的对象。假如在某个线程的两个synchronized块之间发生了一次线程切换,那就会出现线程A等着被线程B持有的Integer.valueOf(1),线程B又等着被线程A持有的Integer.valueOf(2),结果出现大家都
跑不下去的情景。
如果检测到任何死锁的线程,这些都显示在一个新的标签,旁边出现的“死锁”标签, 在图所示。
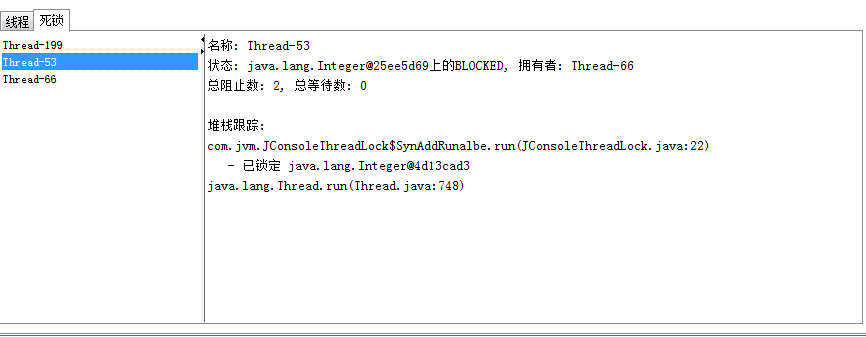
结果描述:显示了线程Thread-53在等待一个被线程Thread-66持有Integer对象,而点击线程Thread-66则显示它也在等待一个Integer对象,被线程Thread-53持有,这样两个线程就互相卡住,都不存在等到锁释放的希望了
7.2.4 类加载信息监控
类”标签显示关于类加载的信息。
- 红线表示加载的类的总数(包括后来卸载的)
- 蓝线是当前的类加载数
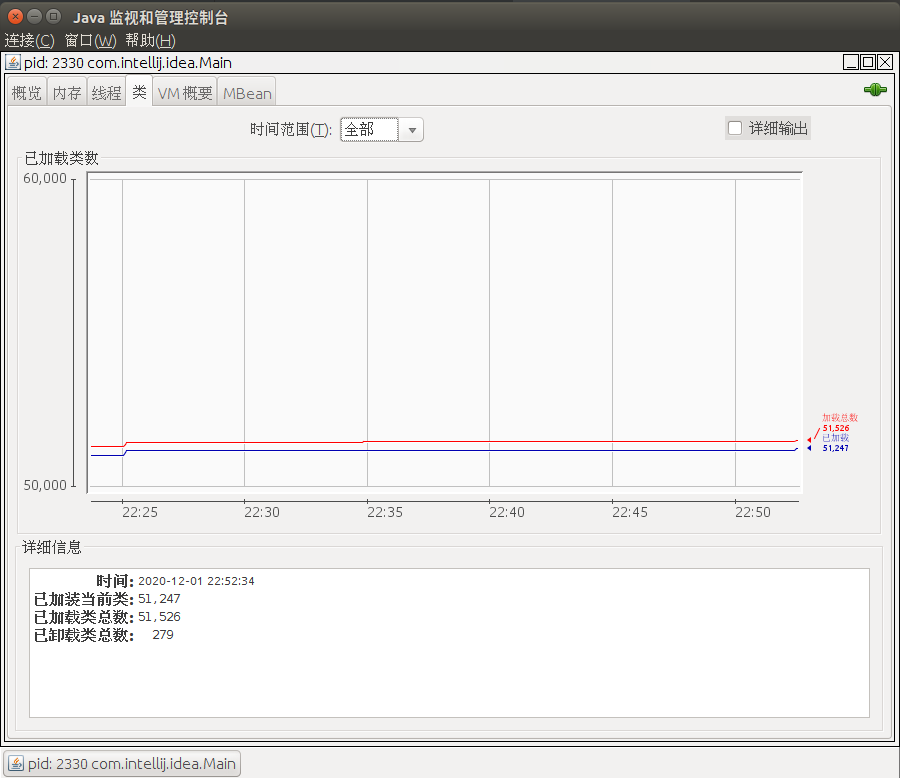
在选项卡底部的详细信息部分显示类的加载,因为Java虚拟机开始的总数,当前加载和卸载的数量。** 跟踪**类加载详细的输出,您可以勾选在顶部的右上角复选框。
7.2.5 VM概要监控
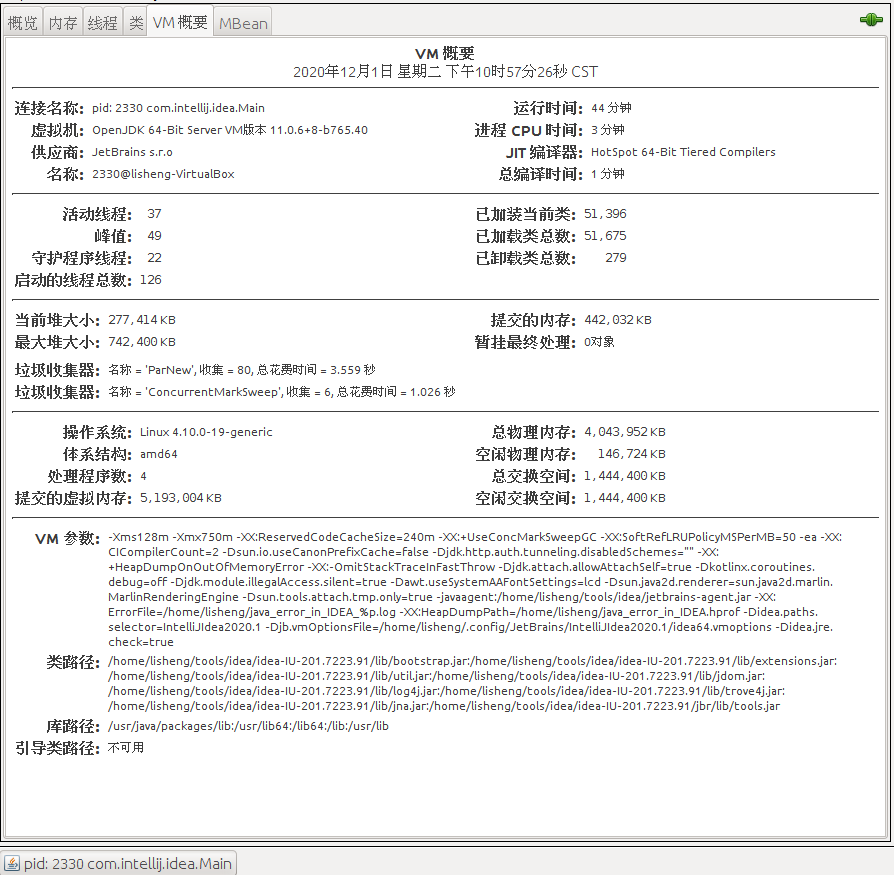
在此选项卡中提供的信息包括以下内容。
- 摘要
- 运行时间 :开始以来,Java虚拟机的时间总额。
- 进程的CPU时间 :Java VM的开始,因为它消耗的CPU时间总量。
- 编译总时间 :累计时间花费在JIT编译。
- 主题
- 活动线程 :目前现场守护线程,加上非守护线程数量。
- 峰值 :活动线程的最高数目,因为Java虚拟机开始。
- 守护线程 :当前的活动守护线程数量。
- 总线程 :开始自Java虚拟机启动的线程总数,包括非守护进程,守护进程和终止的线程。
- 类
- 当前类装载 :目前加载到内存中的类数目。
- 总类加载 :从Java VM开始加载到内存中的类总和,包括那些后来被卸载的类。
- 已卸载类总数 :从Java虚拟机开始从内存中卸载的类的数目。
- 内存
- 当前的堆大小 :目前所占用的堆的千字节数。
- 分配的内存 :堆分配的内存总量。
- 最大堆最大值 :堆所占用的千字节的最大数目。
- 待最后确定的对象:待最后确定的对象的数量。
- 花在执行GC的垃圾收集器 :包括垃圾收集,垃圾收集器的名称,进行藏品的数量和总时间的信息。
- 操作系统
- 总物理内存
- 空闲物理内存
- 分配的虚拟内存
- 其他信息
- VM参数 :输入参数的应用程序通过Java虚拟机,不包括的主要方法的参数。
- 类路径是由系统类加载器用于搜索类文件的类路径。
- 库路径 :加载库时要搜索的路径列表。
- 引导类路径 :引导类路径是由引导类加载器用于搜索类文件。
8 jvisualvm
jvisualvm是Netbeans的profile子项目,从JDK6.0 update 7 版本开始自带。jvisualvm同jconsole一样,都是一个基于图形化界面的、可以查看本地及远程的JAVA GUI监控工具,jvisualvm是一个综合性的分析工具,其整合了jstack、jmap、jinfo等众多调试工具的功能,可以认为jvisualvm是jconsole的升级版。
8.1 启动jvisualvm
在JDK_HOME/bin下双击jvisualvm.exe,或者直接在命令行中输入jvisualvm 都可
我们可以看到侧边框:
- 本地:如果你本地有java进程启动了,那么在本地这个栏目就会显示。
- 远程:监控的远程主机
- 快照:装载dump文件或者hprof文件,进行分析
由于本地和远程展示的监控界面都是相同的,接下来我们直接介绍远程。
8.2 添加远程监控
注意,一个主机如果希望支持远程监控,需要在启动时添加以下参数:
1 |
|
右击”远程”–>”添加远程主机”,出现界面:
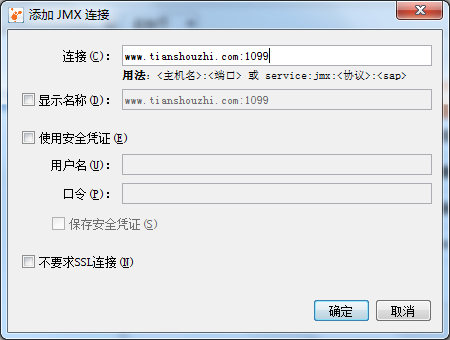
在连接后面添加一个1099,这是远程主机jmx监听的端口号,点击确定,侧边栏变为:
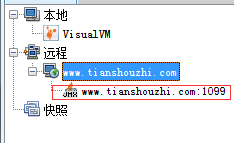
点击红色框中的jmx连接,出现以下界面:
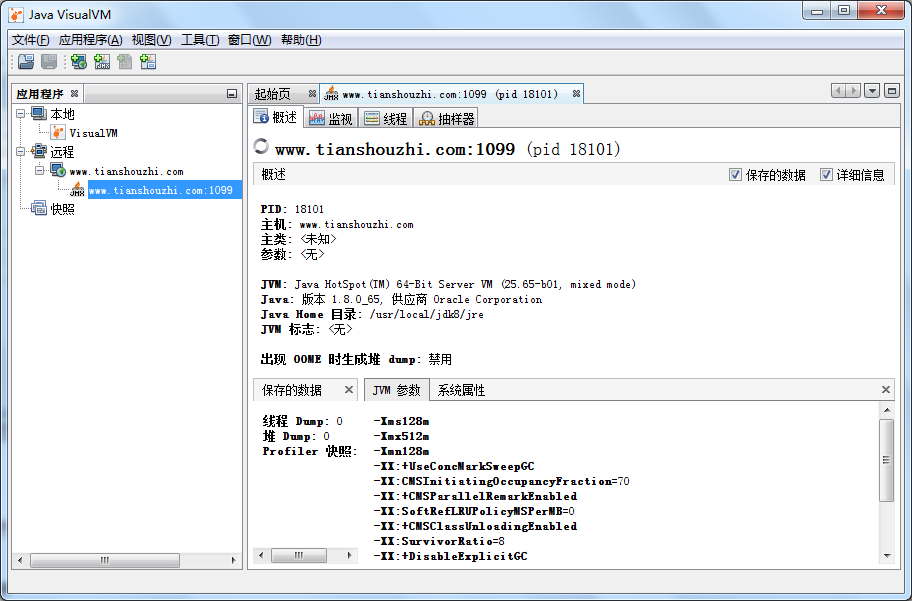
8.3 jvisualvm介绍
jvisualvm分为四个选项卡:概述、监视、线程、抽样器,下面我们一一介绍:
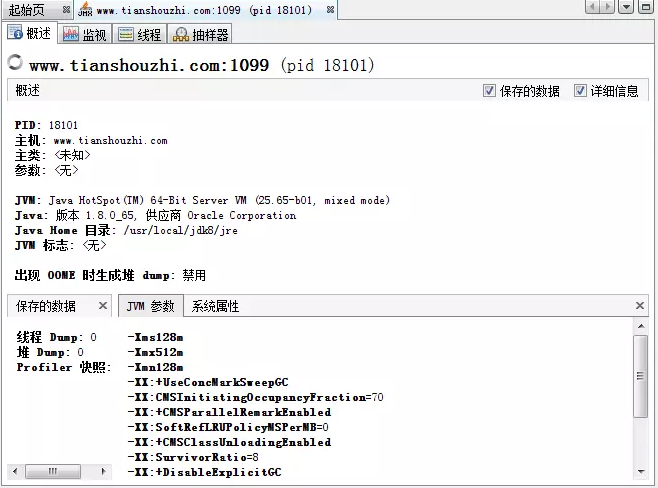
8.3.1 概述页
默认显示的就是概述选项卡,其中的信息相当于我们调用了jinfo命令获得,其还包含了两个子选项卡:
- jvm参数栏:相当于我们调用
jinfo -flags <pid>获得 - 系统属性栏:相当于我们调用
jinfo -sysprops <pid>获得
8.3.2 监视页
主要显示了cpu、内存使用、类加载信息、线程信息等,这只是一个概要性的介绍,如下图:
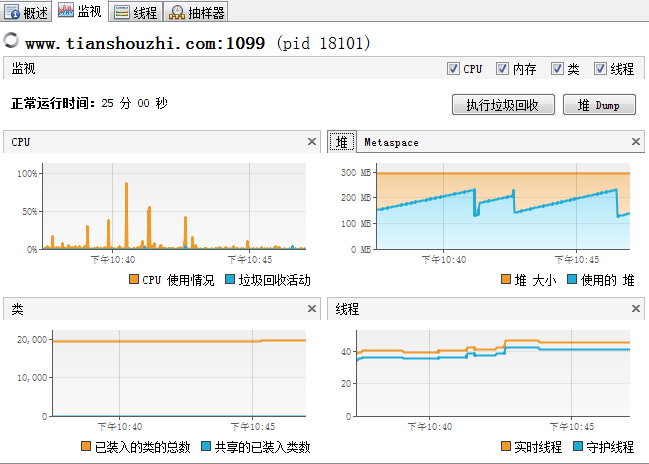
点击右上角的”堆dump”会在远程主机上,dump一个内存映射文件,之所以不直接dump到本地,主要是因为这个文件通常比较大,直接dump到本地会很慢。
dump完成之后,可以手工下载这个文件,通过”文件”->”装入”来进行分析。
8.3.3 线程页
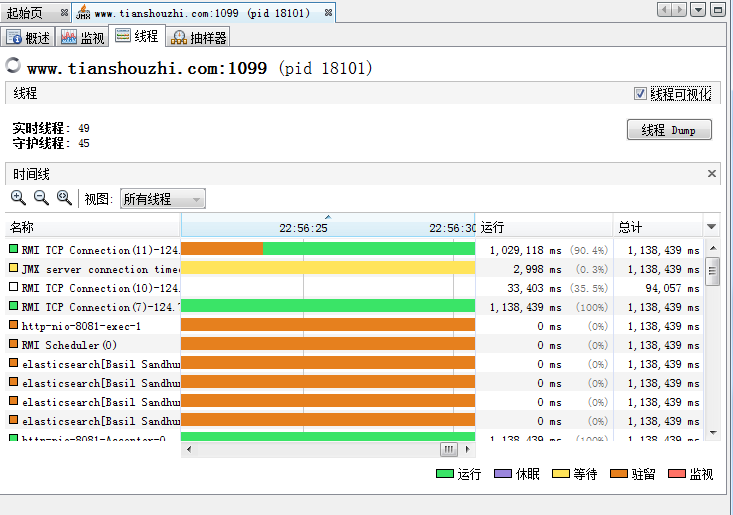
线程选项卡列出了所有线程的信息,并使用了不同的颜色标记,右下角的颜色表示了不同的状态。
右上角的线程dump会直接把线程信息dump到本地,相当于调用了jstack命令,如:
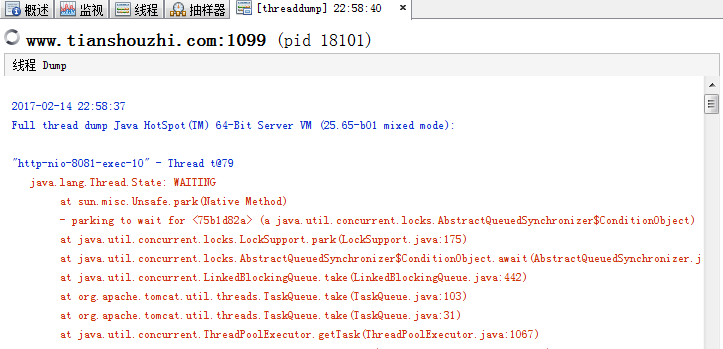
8.3.4 抽样器页
主要有”cpu”和”内存”两个按钮,功能类似,只不过一个是抽样线程占用cpu的情况,一个是抽样jvm对象内存的情况。
- 通过设置可以对CPU的采样来源以及内存的刷新时间进行设置;
- 点击CPU或者Memory即可开始监控,点击Stop则停止采样;
我们以分析cpu波动为例,看下如何使用cpu采样器:
8.3.4.1 分析CPU波动问题
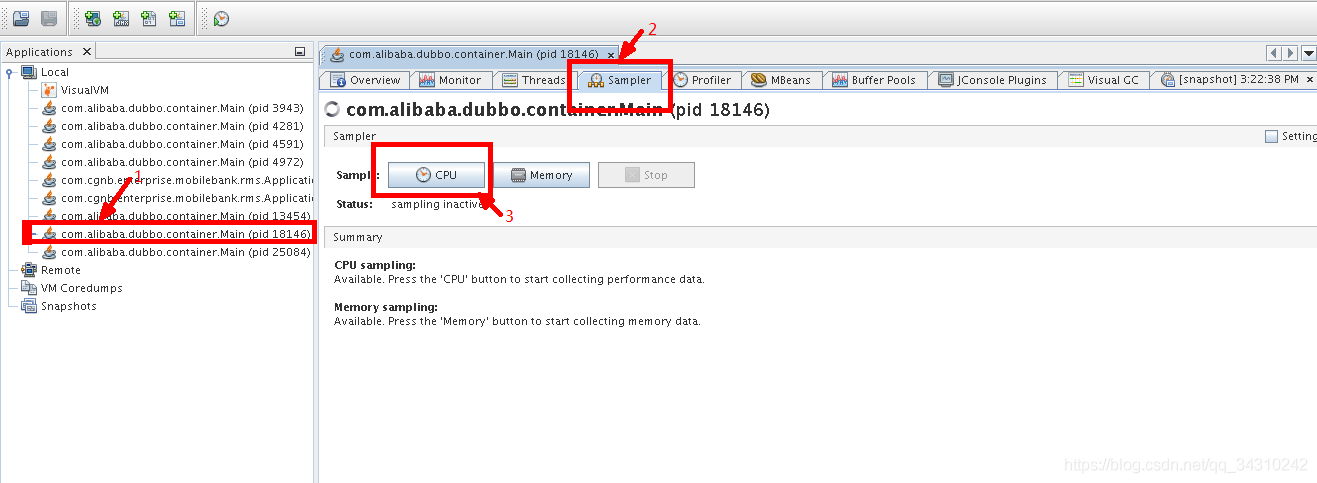
进入抽样器页(Sampler),在CPU波动的时候点击CPU对CPU进行抽样。
注意线上环境千万不要使用Sampler右边的Profiler
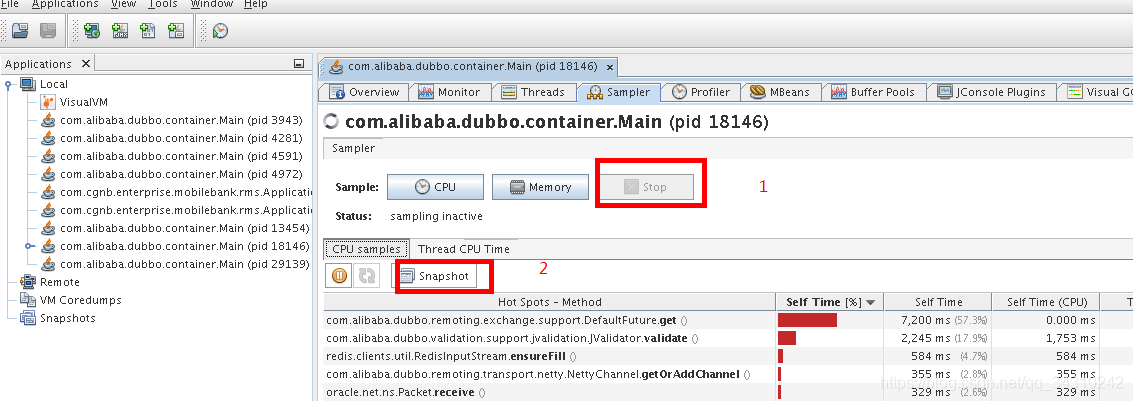
抽样进行一段时间后(建议3分钟左右就行了,时间越长生成的snapshot越大),点击”stop”,然后点击”snapshot”生成快照
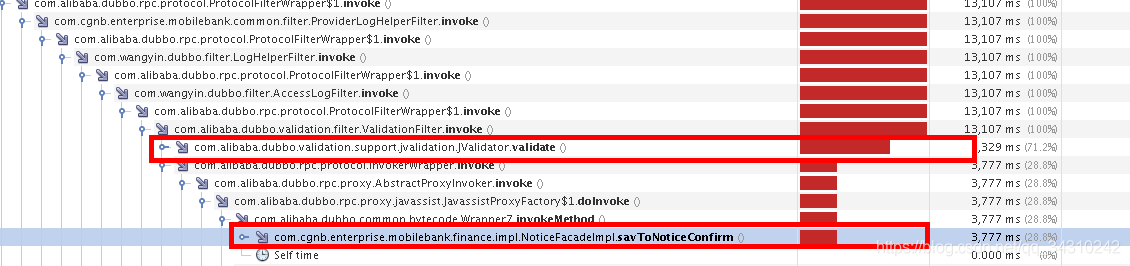
生成快照后按照”Total Time(CPU)”排序,找到那些线程最耗费CPU,从下图中我们看到基本上都是DubboServerHandler,熟悉Dubbo框架的知道这都是我们的业务线程。
那么我们对这些线程进行分析(多分析几个线程,双击指定线程就可以看这个线程的调用栈以及耗时情况),看看这些线程在哪里比较耗费CPU。
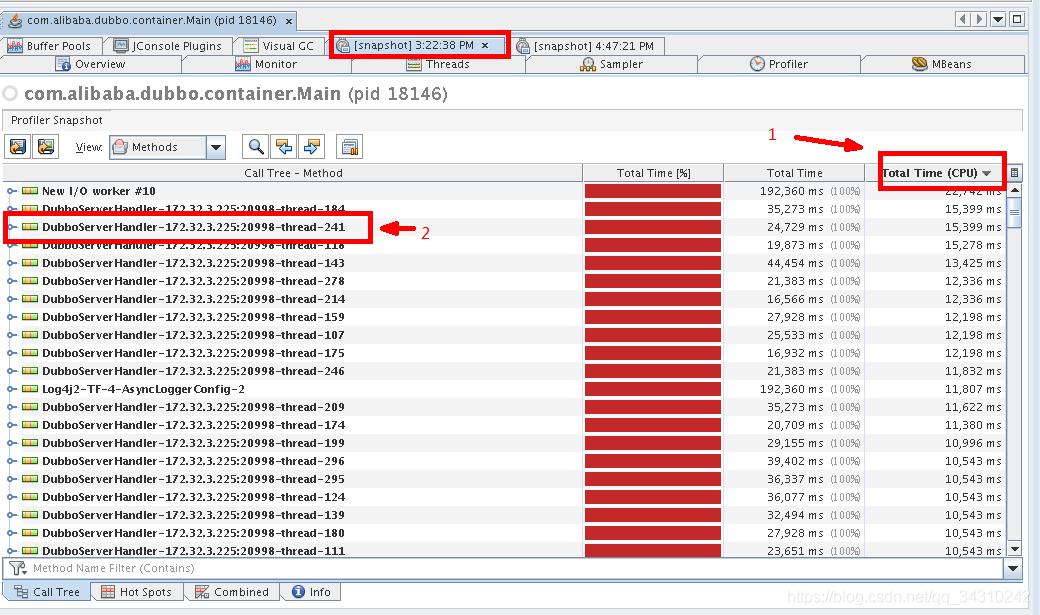
通过分析发现,在Dubbo远程调用的时候验证参数的时间比我们处理业务的时间都长(见下图红色方框框起来的方法)。结合Dubbo官方文档得知,Dubbo的参数验证这个特性是比较耗费性能的,而我们的接口参数使用了javax.validation注解来验证参数。所以我们在调用的时候使用validation=”false”禁止使用参数验证这个特性就好了CPU就回归正常了。
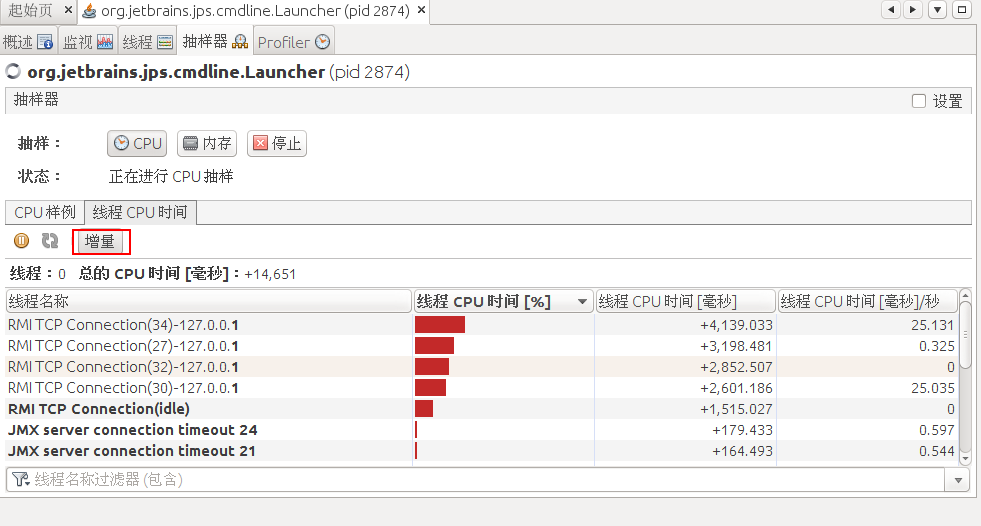
除此之外,我们也可以动态的观察线程的变化,功能有点类似JProfiler的“Mark Current Values”。我们点击线程CPU时间这个tab。查看每个线程占用cpu时间的增量数据。
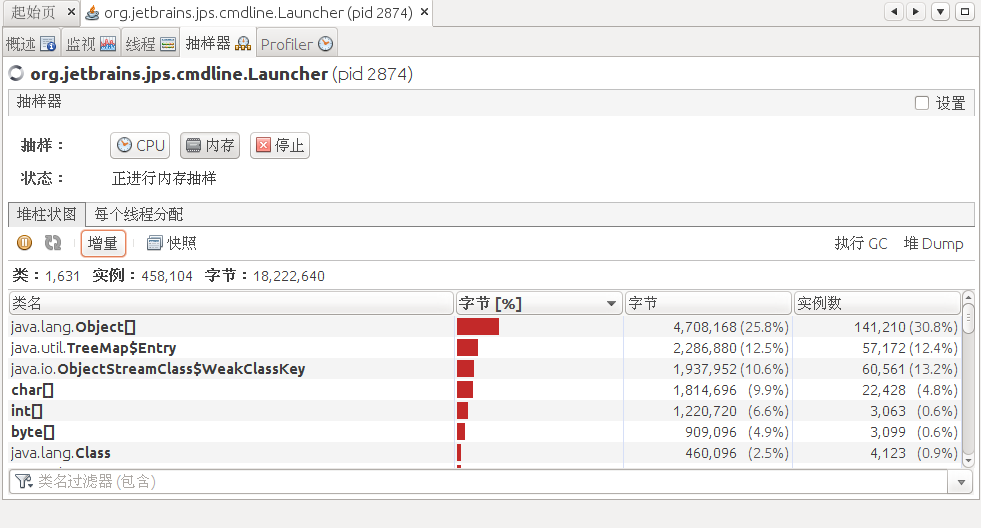
8.3.4.2 内存采样
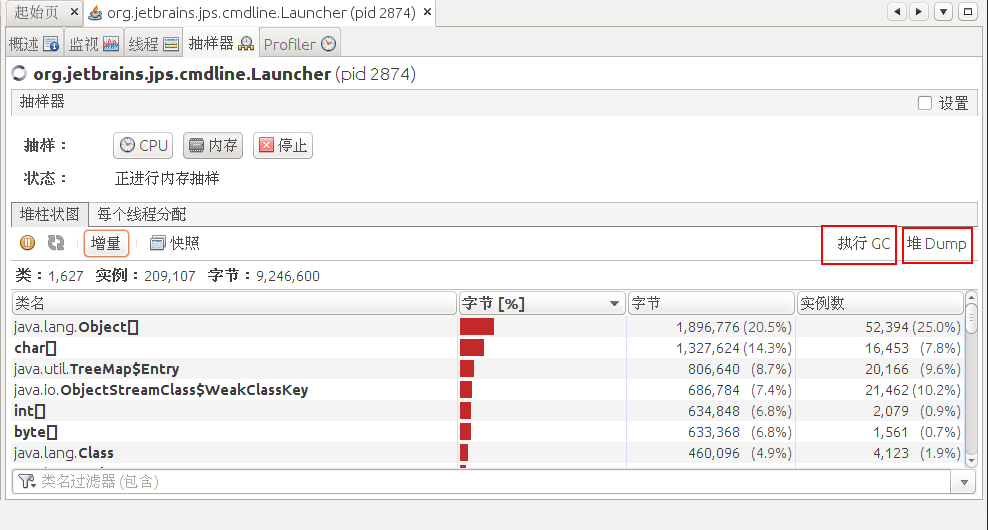
和cpu采样一样的,样进行一段时间后(建议3分钟左右就行了,时间越长生成的snapshot越大),点击”stop”,然后点击”snapshot”生成快照
点击增量同样可以监控内存的变动情况:
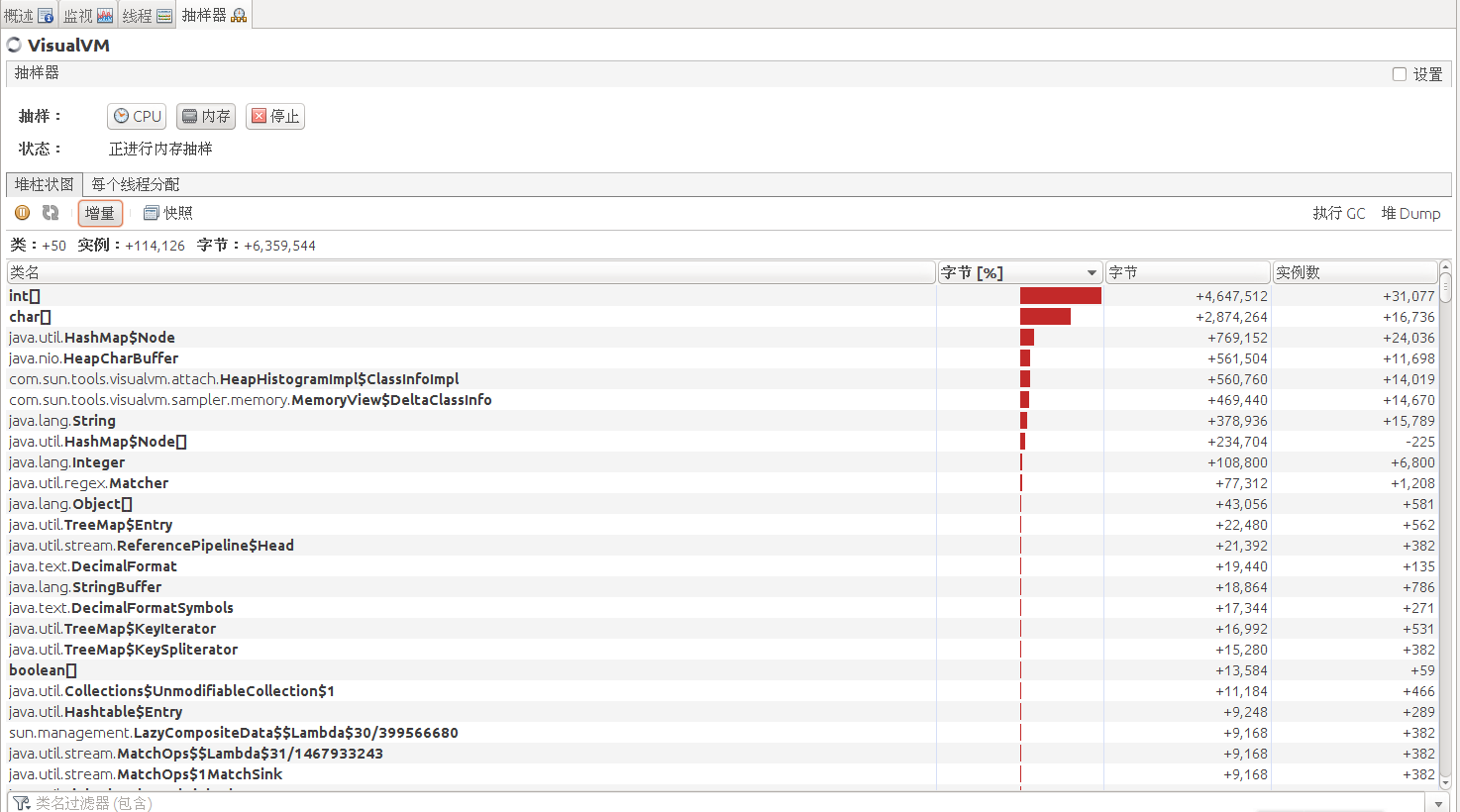
点击“执行GC”,则可以手动触发GC;
点击“堆Dump”,则可以手动触发dump文件生成;