前言
排序算法可以分为两大类:
- 比较类排序:通过比较来决定元素间的相对次序,由于其时间复杂度不能突破O(nlogn),因此也称为非线性时间比较类排序。
- 非比较类排序:不通过比较来决定元素间的相对次序,它可以突破基于比较排序的时间下界,以线性时间运行,因此也称为线性时间非比较类排序。
其中这些算法的复杂度如下表格:
| 算法 | 时间复杂度(平均) | 时间复杂度(最坏) | 时间复杂度(最好) | 空间复杂度 | 稳定性 | 备注 |
|---|---|---|---|---|---|---|
| 冒泡排序 | O(n^2) | O(n^2) | O(n) | O(1) | 稳定 | |
| 选择排序 | O(n^2) | O(n^2) | O(n^2) | O(1) | 不稳定 | |
| 插入排序 | O(n^2) | O(n^2) | O(n) | O(1) | 稳定 | |
| 快速排序 | O(nlogn) | O(n^2) | O(nlogn) | O(logn)~O(n) | 不稳定 | O(logn)~O(n)分别表示最好情况和最坏情况 |
| 希尔排序 | O(n^1.3) | O(n^2) | O(n) | O(1) | 不稳定 | |
| 归并排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(n) | 稳定 | |
| 堆排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(1) | 不稳定 | |
| 计数排序 | O(n+k) | O(n+k) | O(n+k) | O(n+k) | 稳定 | k为元素值范围差,或者说元素值的数量 |
| 桶排序 | O(n+nlogn-nlogk) | O(nlogn) | O(n) | O(n+k) | 稳定 | k表示桶个数 |
| 基数排序 | O(d(n+r)) | O(d(n+r)) | O(d(n+r)) | O(n+r) | 稳定 | d表示最大数字的位数,r表示基数,数字固定是10 |
稳定性:如果a原本在b前面,而a=b,排序之后a仍然在b的前面,则表示该算法是稳定的排序算法。
1 冒泡排序(Bubble Sort)
冒泡排序是一种简单的排序算法。它重复地遍历要排序的数列,每一次比较两个元素,如果它们的顺序错误就把它们交换过来。
遍历数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。
这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。
1.1 算法描述
冒泡排序的算法步骤如下:
- 比较相邻的元素。如果第一个比第二个大,就交换它们两个;
- 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对,这样在最后的元素应该会是最大的数;
- 针对所有的元素重复以上的步骤,直到排序完成。
1.2 动图演示
1.3 代码实现
1 | public void bubbleSort() { |
由代码可见,冒泡排序的时间复杂度是O(n^2),不过值得注意的是,在最好的情况下(即当前数列已经是我们想要的顺序了),它的时间复杂度是O(n)。要想得到线性的时间复杂度,我们需要改造一下代码:
1 | public void bubbleSort() { |
2 选择排序(Selection Sort)
选择排序(Selection-sort)是一种简单直观的排序算法。它的工作原理:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
2.1 算法描述
n个记录的直接选择排序可经过n-1趟直接选择排序得到有序结果。具体算法描述如下:
- 初始状态:无序区为
R[1,n],有序区为空; - 第i趟排序(i=1,2,3…n-1)开始时,当前有序区和无序区分别为
R[1,i-1]和R(i,n)。该趟排序从当前无序区中选出关键字最小的记录R[k],将它与无序区的第1个记录R交换,使R[1,i]和R[i+1,n)分别变为记录个数增加1个的新有序区和记录个数减少1个的新无序区; - n-1趟选择,排序完成。
2.2 动图演示
2.3 代码实现
1 | public void selectionSort() { |
2.4 算法总结
选择排序是表现最稳定的排序算法之一,因为无论什么数据进去都是O(n^2)的时间复杂度,所以用到它的时候,数据规模越小越好。
同时值得注意的是,它还是不稳定的,如何理解选择排序是不稳定的呢?
举个例子,序列5 8 5 2 9,我们知道第一遍选择第1个元素5会和2交换,那么原序列中2个5的相对前后顺序就被破坏了,所以选择排序不是一个稳定的排序算法。
唯一的好处可能就是不占用额外的内存空间。选择排序也是一般人想到的最多的排序方法,它的排序思路非常的常规。
3 插入排序(Insertion Sort)
插入排序(Insertion-Sort)的算法描述是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
3.1 算法描述
一般来说,插入排序都采用in-place在数组上实现。具体算法描述如下:
- 从第一个元素开始,该元素可以认为已经被排序;
- 取出下一个元素,在已经排序的有序区间中从后向前扫描;
- 如果当前被扫描的元素(已排序)大于新元素,将该元素移到下一位置,即将它的空间让出来;
- 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置;
- 将新元素插入到该位置;
- 重复步骤2~5。
3.2 动图演示
3.3 代码实现
1 | public void insertionSort(){ |
3.4 算法总结
插入排序在实现上,通常采用in-place排序(即只需用到O(1)的额外空间的排序),因而在从后向前扫描过程中,需要反复把已排序元素逐步向后挪位,为最新元素提供插入空间。
值得注意的是,插入排序最好情况(数列本身已经有序)的时间复杂度是O(n),也就是说,每一趟的插入操作,都是第一步就找到了插入的位置,这样的时间复杂度是线性的。
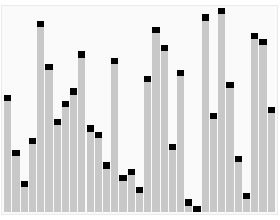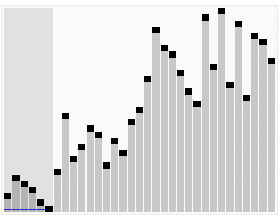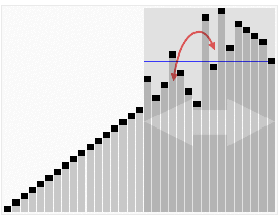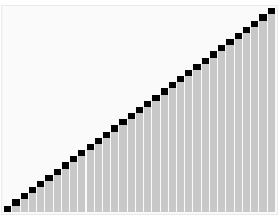
4 快速排序(Quick Sort)
快速排序是采用分治法的思路:通过一趟排序将待排记录分隔成独立的两部分,其中一部分记录的关键字均比另一部分的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。
4.1 算法描述
快速排序使用分治法来把一个串(list)分为两个子串(sub-lists)。具体算法描述如下:
- 从数列中挑出一个元素,称为 “基准”(pivot);一般都采用当前数列的第一个元素作为pivot。
- 重新排序数列,所有比基准值小的元素摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作;
- 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列,重复步骤1-2进行递归排序,直到所有子数列都有序为止。
4.2 动图演示


4.3 代码实现
1 | /** |
4.4 算法总结
快速排序顾名思义,它的性能可以达到比较类排序算法最高的O(nlogn)级别。不过由于分治法主要采用递归实现,所以它也是有额外的递归造成的栈空间的使用。因为一般情况下,快排会递归logn次,所以他的空间复杂度是O(logn)。
可惜的是,由于关键字的比较和交换是跳跃进行的,因此,快速排序是一种不稳定的排序方法。
快排的最坏情况,是每次分隔,生成的两个subList都有一个是空集合,也就是每次选取的pivot是当前数列的最小值或者最大值,无法达到二分的效果。这种情况下,它的时间复杂度是O(n^2),空间复杂度是O(n)。
5 希尔排序(Shell’s Sort)
希尔排序(Shell’s Sort)是插入排序的一种,又称“缩小增量排序”(Diminishing Increment Sort),是直接插入排序算法的一种更高效的改进版本,它与插入排序的不同之处在于,它会优先比较距离较远的元素。
希尔排序是非稳定排序算法,也是第一个突破O(n2)的排序算法。
该方法因 D.L.Shell 于 1959 年提出而得名。
希尔排序是基于插入排序的以下两点性质而提出改进方法的:
- 插入排序在对几乎已经排好序的数据操作时,效率高,即可以达到线性排序的效率。
- 因为插入排序每次遍历一遍完整数组,只能将一个元素移动到已排序区间的正确位置。当n值很大时,为了找到移动一个元素到正确位置的时间太长了,所以插入排序一般来说是低效的算法。
基于插入排序上述的这两点性质,希尔排序通过分组,达到了如下三个目的:
- 通过分组,使得每个子序列的长度减少,使得每一次遍历,能较快的将一个元素确定位置。虽然这时确定的只是改元素在分组内的位置,可能并非整个序列的正确位置,但此时已经接近于它们排序后的最终位置了。
- 通过分组,使得只要完整遍历一次整个序列的时间,就可以使每个分组内都有一个元素确定大概的位置,相比于插入排序的一次完整遍历只能确定一个元素的正确位置,性能提升非常明显。
- 通过分组进行插入排序,使得希尔排序在进行最后一次全序列的插入排序时,基本上每个元素所在的位置已经接近于它排序后正确的位置了,面对这样的情况,插入排序的性能可以达到接近线性时间,即O(n)。
5.1 算法描述
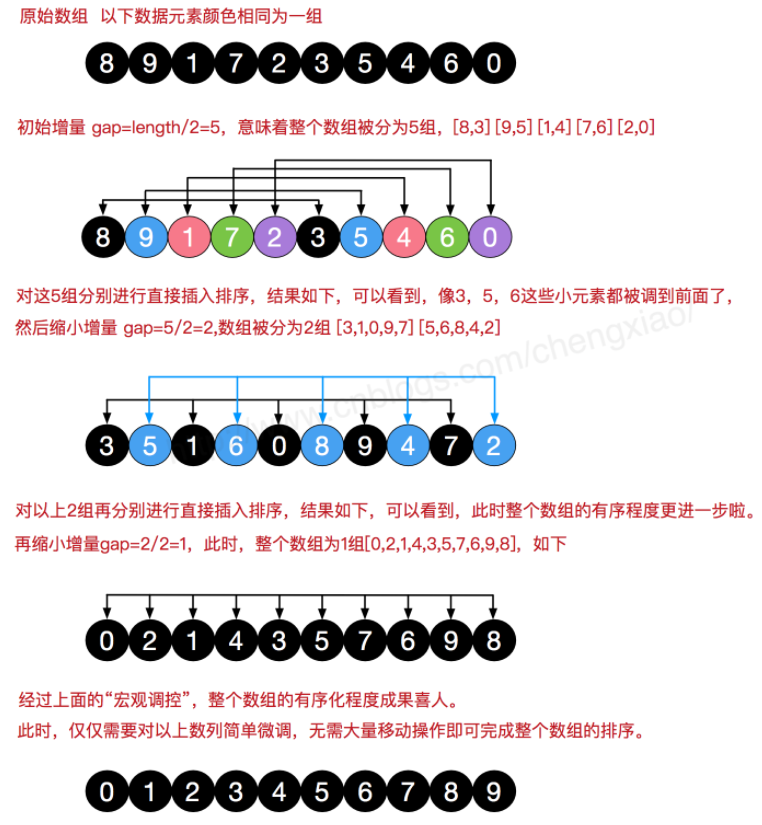
先将整个待排序的序列分割成为若干子序列分别进行直接插入排序,具体算法描述:
- 选择一个增量gap,一般默认初始为length/2。
- 确定了gap后,则可以得到如下gap个分组,每个分组最多有length/gap个元素,如gap=length/2时分组如:
{arr[0],arr[gap]},{arr[1],arr[gap+1]}.....{arr[gap-1],arr[length-1]} - 对每个分组,执行插入排序。
- 再确定一个新的gap,一般为再缩小一倍,gap=gap/2
- 重复步骤2、3、4,直到gap=1为止,这时不存在其他分组了,最后执行一次对整个序列的插入排序,算法结束。
5.2 动图演示

5.3 代码实现
1 | private static void shellSort(int[] arr, int start, int end) { |
5.4 算法总结
希尔排序的时间的平均时间复杂度为O(n^1.3),希尔排序时间复杂度最快的是O(nlog(2n)),没有快速排序算法O(n(logn))快,因此希尔排序在中等大小规模时表现良好,但对规模非常大的数据排序不是最优选择。
由于多次插入排序,我们知道一次插入排序是稳定的,不会改变相同元素的相对顺序,但在不同的插入排序过程中,相同的元素可能在各自的插入排序中移动,最后其稳定性就会被打乱,所以希尔排序是不稳定的。
希尔排序非常容易实现,算法代码短而简单。 此外,希尔算法在最坏的情况下和平均情况下执行效率相差不是很多,一般来说,几乎任何排序工作在开始时都可以用希尔排序,若在实际使用中证明它不够快,再改成快速排序这样更高级的排序算法。
6 归并排序(Merge Sort)
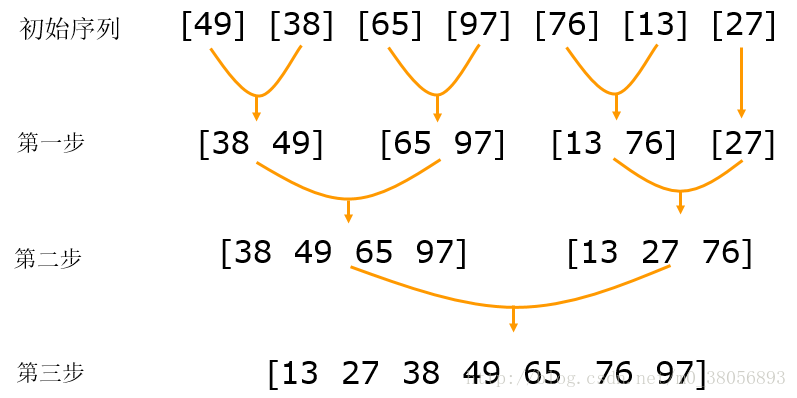
归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。
速度仅次于快速排序,为稳定排序算法,一般用于对总体无序,但是各子项相对有序的数列
6.1 算法描述
- 把长度为n的输入序列分成两个长度为n/2的子序列;
- 对这两个子序列分别采用归并排序,再进行对半分,一直分到子序列的长度为1为止。
- 将两个排序好的子序列合并,递归回溯,最后归并成一个最终的排序序列。
6.2 动图演示
6.3 代码实现
1 | public static void main(String[] args) { |
6.4 算法总结
归并排序是一种稳定的排序方法。和选择排序一样,归并排序的性能不受输入数据的影响,但表现比选择排序好的多,因为始终都是O(nlogn)的时间复杂度。代价是需要额外的内存空间。
速度仅次于快速排序,为稳定排序算法,一般用于对总体无序,但是各子项相对有序的数列。
7 堆排序(Heap Sort)
堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。
7.1 算法描述
- 将初始待排序关键字序列(R1,R2….Rn)构建成大顶堆,此堆为初始的无序区;
- 将堆顶元素R[1]与最后一个元素R[n]交换,此时得到新的无序区(R1,R2,……Rn-1)和新的有序区(Rn),且满足R[1,2…n-1]<=R[n];
- 由于交换后新的堆顶R[1]可能违反堆的性质,因此需要对当前无序区(R1,R2,……Rn-1)调整为新堆,然后再次将R[1]与无序区最后一个元素交换,得到新的无序区(R1,R2….Rn-2)和新的有序区(Rn-1,Rn)。
- 不断重复此过程直到有序区的元素个数为n-1,则整个排序过程完成。
7.2 动图演示

7.3 代码实现
1 | public static void main(String[] args) { |
7.4 算法总结
堆排序是一种不稳定的选择排序,整体主要由构建初始堆+交换堆顶元素和末尾元素并重建堆两部分组成。其中构建初始堆经推导复杂度为O(n),在交换并重建堆的过程中,需交换n-1次,而重建堆的过程中,根据完全二叉树的性质,[log2(n-1),log2(n-2)…1]逐步递减,近似为nlogn。
所以堆排序时间复杂度一般认为就是O(nlogn)级。时间复杂度很稳定,都是O(nlogn)。
8 计数排序(Counting Sort)
计数排序不是基于比较的排序算法,其核心在于将输入的数据值转化为键存储在额外开辟的数组空间中。 作为一种线性时间复杂度的排序,计数排序要求输入的数据必须是有确定范围的整数。
8.1 算法描述
- 找出待排序的数组A中最大元素值max和最小元素值min,并创建一个长度为max-min的数组C。
- 统计数组A中每个值为i的元素出现的次数,存入数组C的第i-min项;
- 数组C从小到大填充原数组A,数组C从第0项开始,每一项i输出C[i]次,输出的值是i+min。
8.2 动图演示
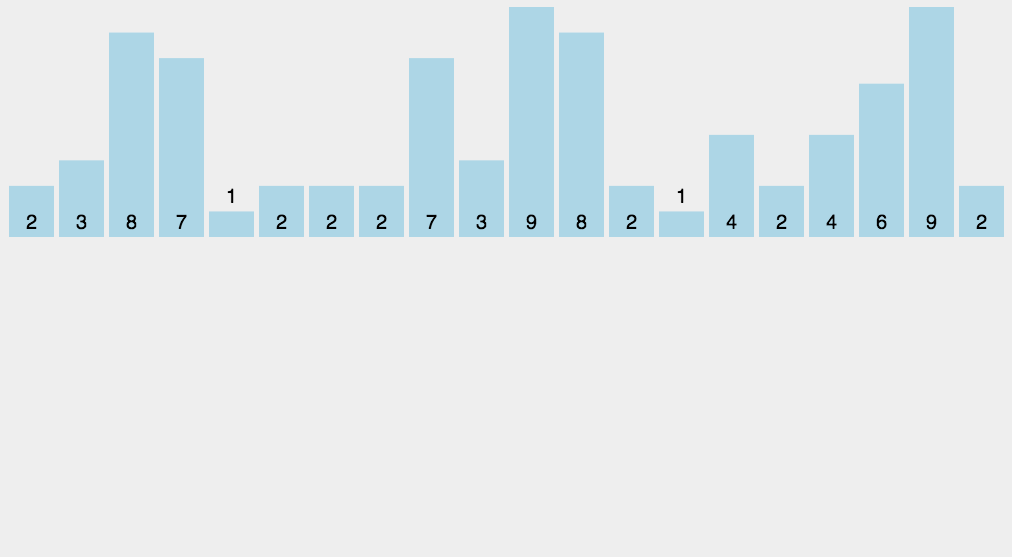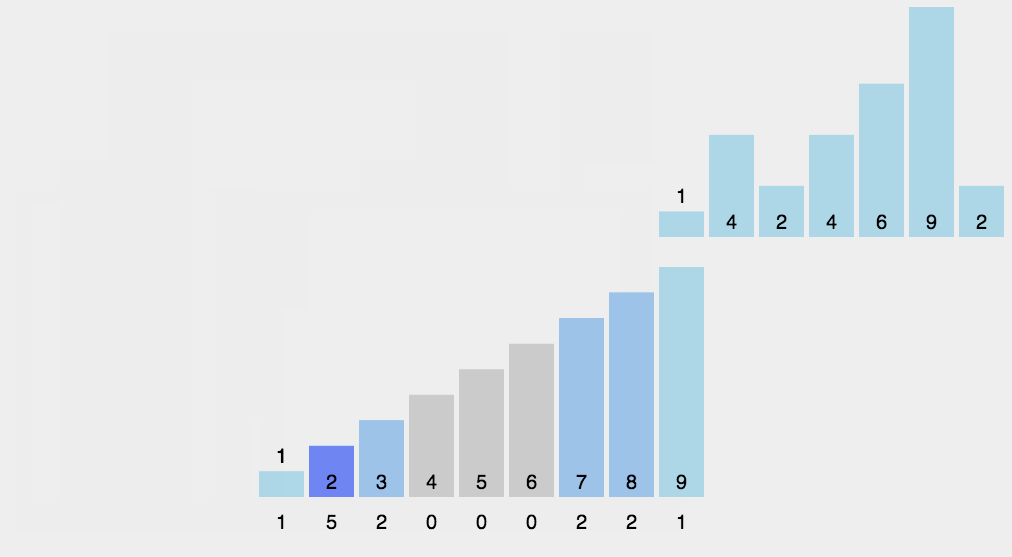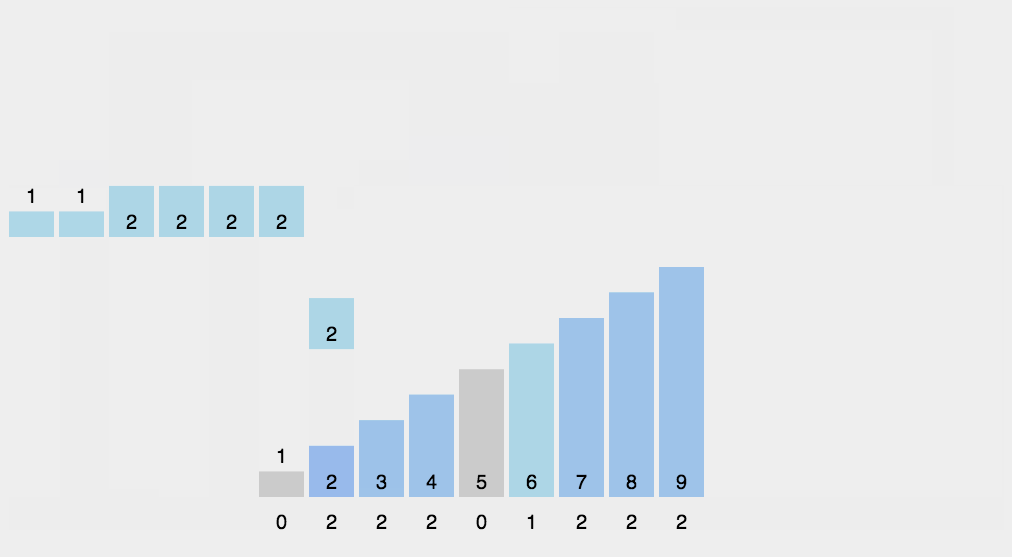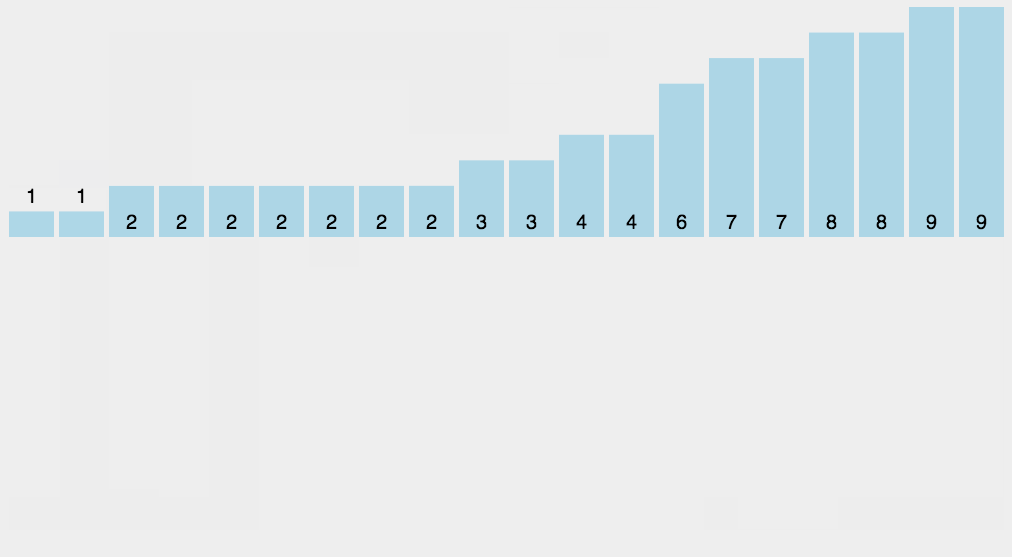
8.3 代码实现
1 | public static void countingSort(int[] arr) { |
8.4 算法总结
计数排序是一个稳定的排序算法。当输入的元素是 n 个范围差为k的整数时,时间复杂度是O(n+k),空间复杂度也是O(n+k),其排序速度快于任何比较排序算法。当k不是很大并且序列比较集中时,计数排序是一个很有效的排序算法。
9 桶排序(Bucket Sort)
桶排序 (Bucket sort)的工作的原理:假设输入数据服从均匀分布,将数据分到有限数量的桶里,每个桶再分别排序(一般使用快排),最后把每个桶里排好序的数据拼接起来。
算法思想和散列中的开散列法差不多,当冲突时放入同一个桶中;可应用于数据量分布比较均匀,或比较侧重于区间数量时。
桶排序利用了函数的映射关系,高效与否的关键就在于这个映射函数的确定。
我们用k表示桶的个数,那假设数据是均匀分布的,则每个桶的元素平均个数为n/k,那么桶排序的时间复杂度是O(n+nlog(n/k))=O(n+nlogn-nlogk)。
故而我们可以很明显的看出,O(n+nlogn-nlogk),为了使桶排序更加高效,我们需要做到这两点:
- 在额外空间充足的情况下,尽量增大桶的数量,即k越大越好。当然,做到这一点很不容易,数据量巨大的情况下,映射函数会使得桶集合的数量巨大,空间浪费严重。这就是一个时间代价和空间代价的权衡问题了。
- 使用的映射函数能够将输入的 N 个数据均匀的分配到 K 个桶中,使得每个桶内的排序性能接近。(试想一下极端情况,所有元素都在一个桶内,那时间复杂度就是快排的O(nlogn)了)
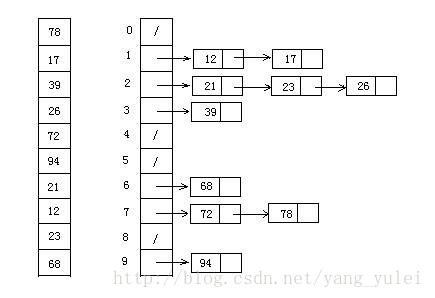
9.1 算法描述
- 设置一个定量的数组当作空桶;
- 遍历输入数据,并且把数据一个一个放到对应的桶里去;
- 对每个不是空的桶进行排序;
- 从不是空的桶里把排好序的数据拼接起来。
9.2 动图演示
9.3 代码实现
1 | public static void bucketSort(int[] arr,int bucketNum){ |
9.4 算法总结
桶排序在最优情况下(数组内的元素均匀分布,可以使得分桶后,每个桶内的元素数量差异不大),可以达到接近线性的时间复杂度,因为它不是比较排序算法,所以可以突破O(nlogn)的极限。
桶排序最坏的时间复杂度是O(nlogn),也就是所有元素都在同一个桶内,这样相当于对整个列表使用了快排。
不过桶排序是稳定的排序算法。
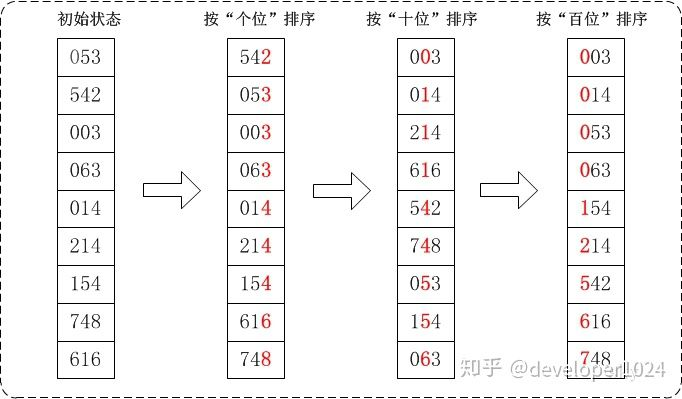
10 基数排序(Radix Sort)
基数排序是按照低位先排序,然后收集;再按照次低位排序,然后再收集;依次类推,直到最高位。
有时候有些属性是有优先级顺序的,先按低优先级排序,再按高优先级排序。最后的次序就是高优先级高的在前,高优先级相同的低优先级高的在前。
比如一系列两位数数字组成的序列,他们比大小,十位上的数字肯定优先级更高,个位上的数字优先级较低。我们先按照个位上的数字排序,再按照十位上的数字排序,那么就可以得到十位>个位标准下的有序。
换句话说,如果对于数字大小的评价标准是个位>十位,那基数排序先判断十位再判断个位即可。
在十进制数中,基数r就等于10,即表示最大有10种可能,最多需要10个桶来映射数组元素。
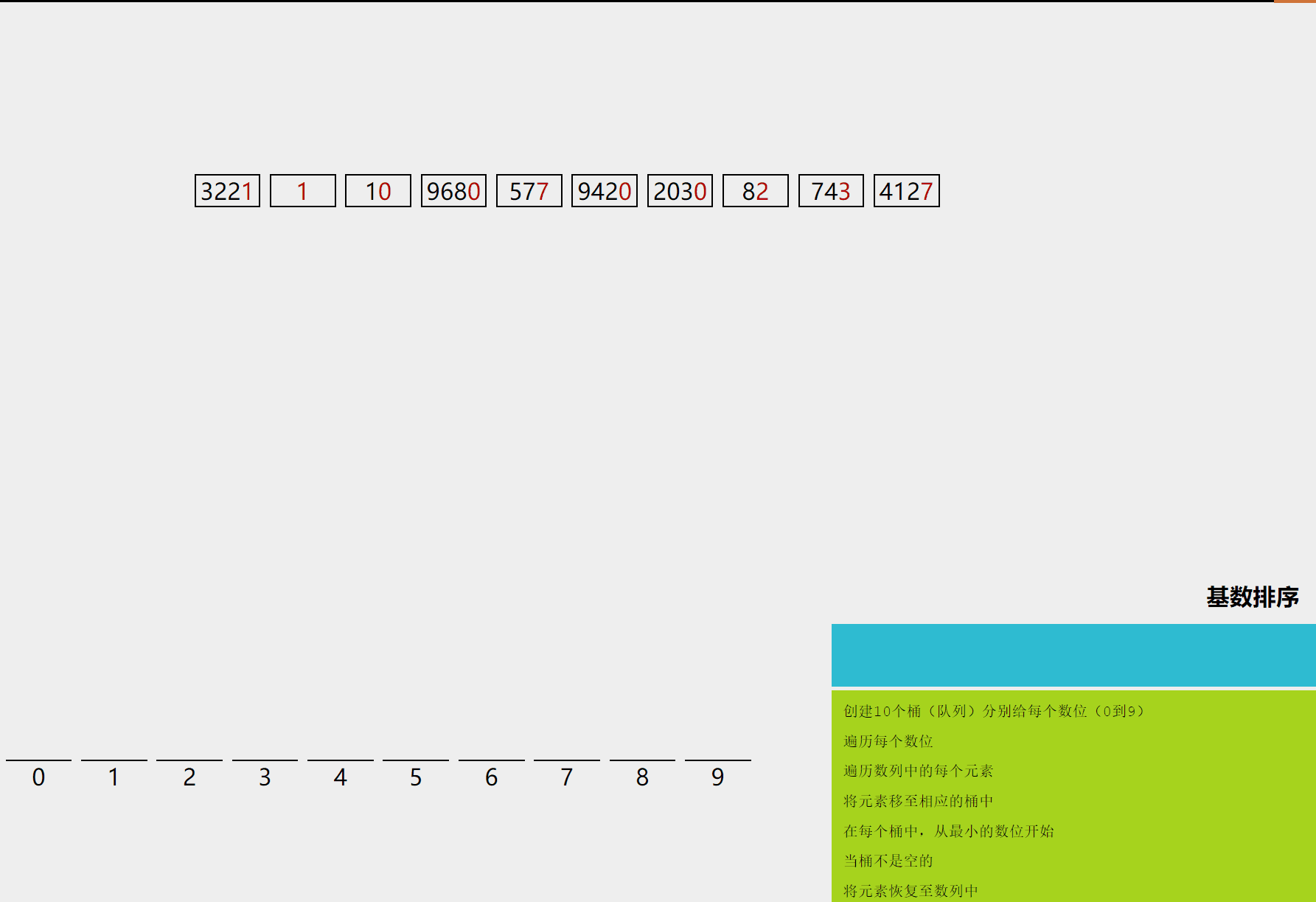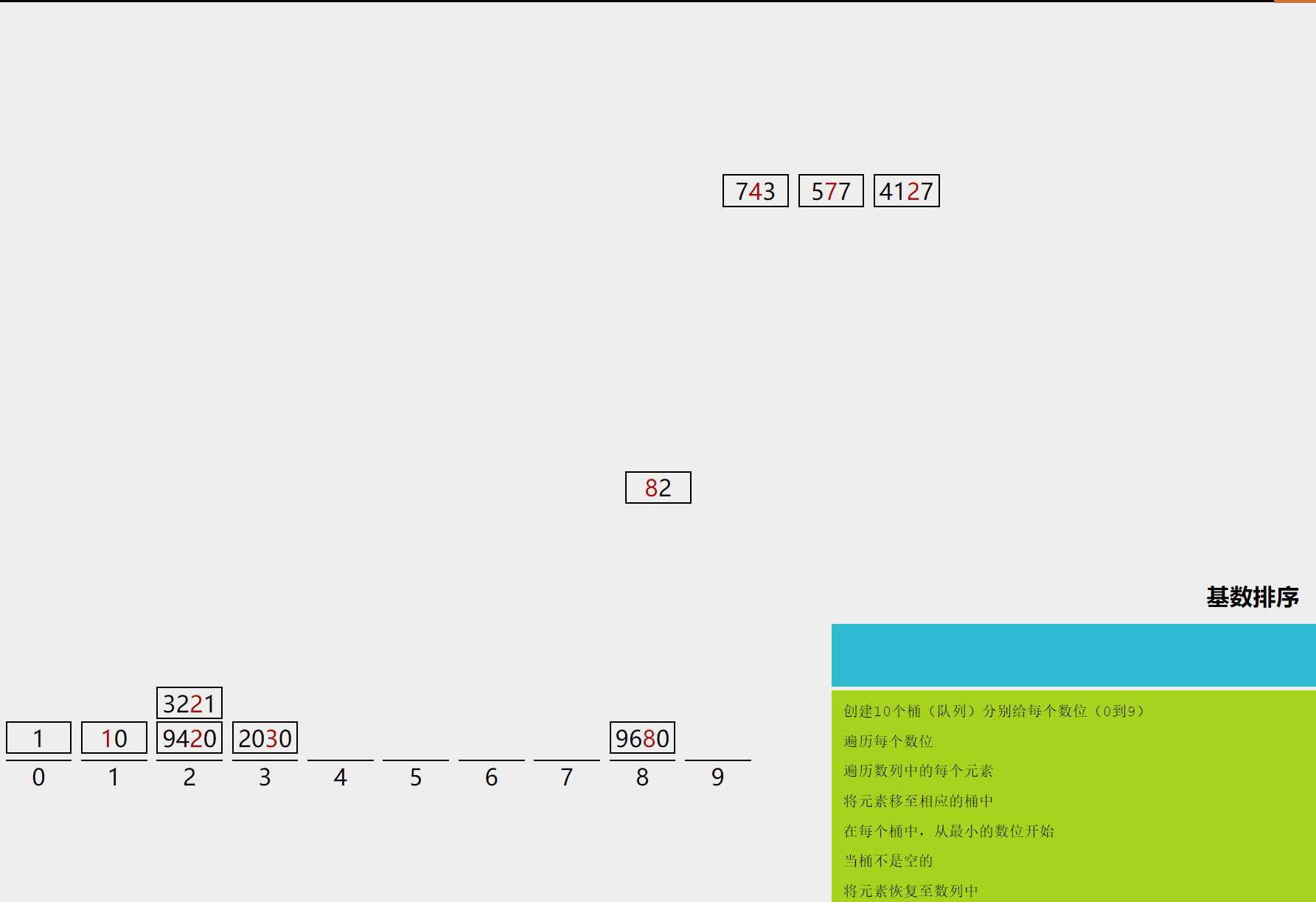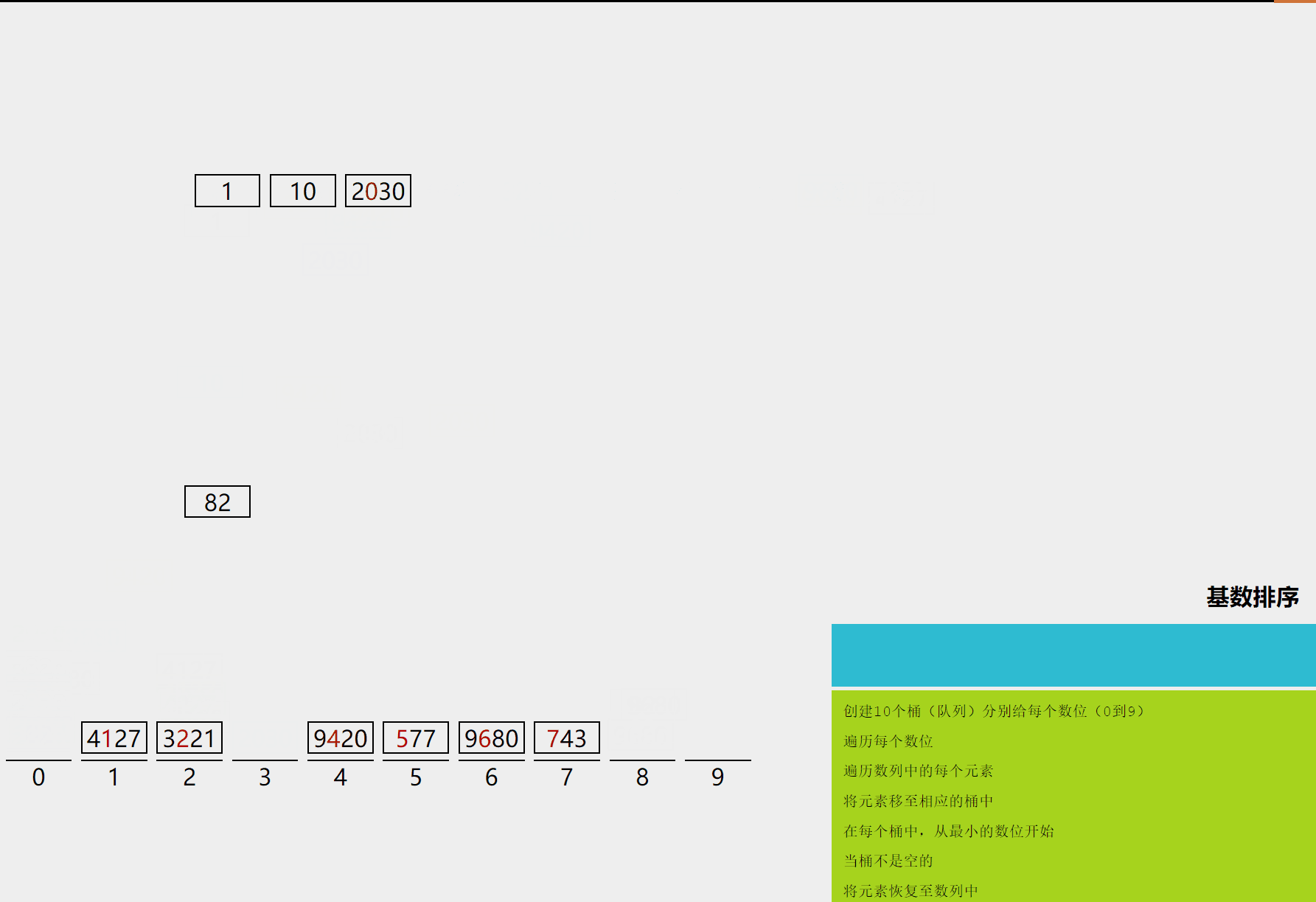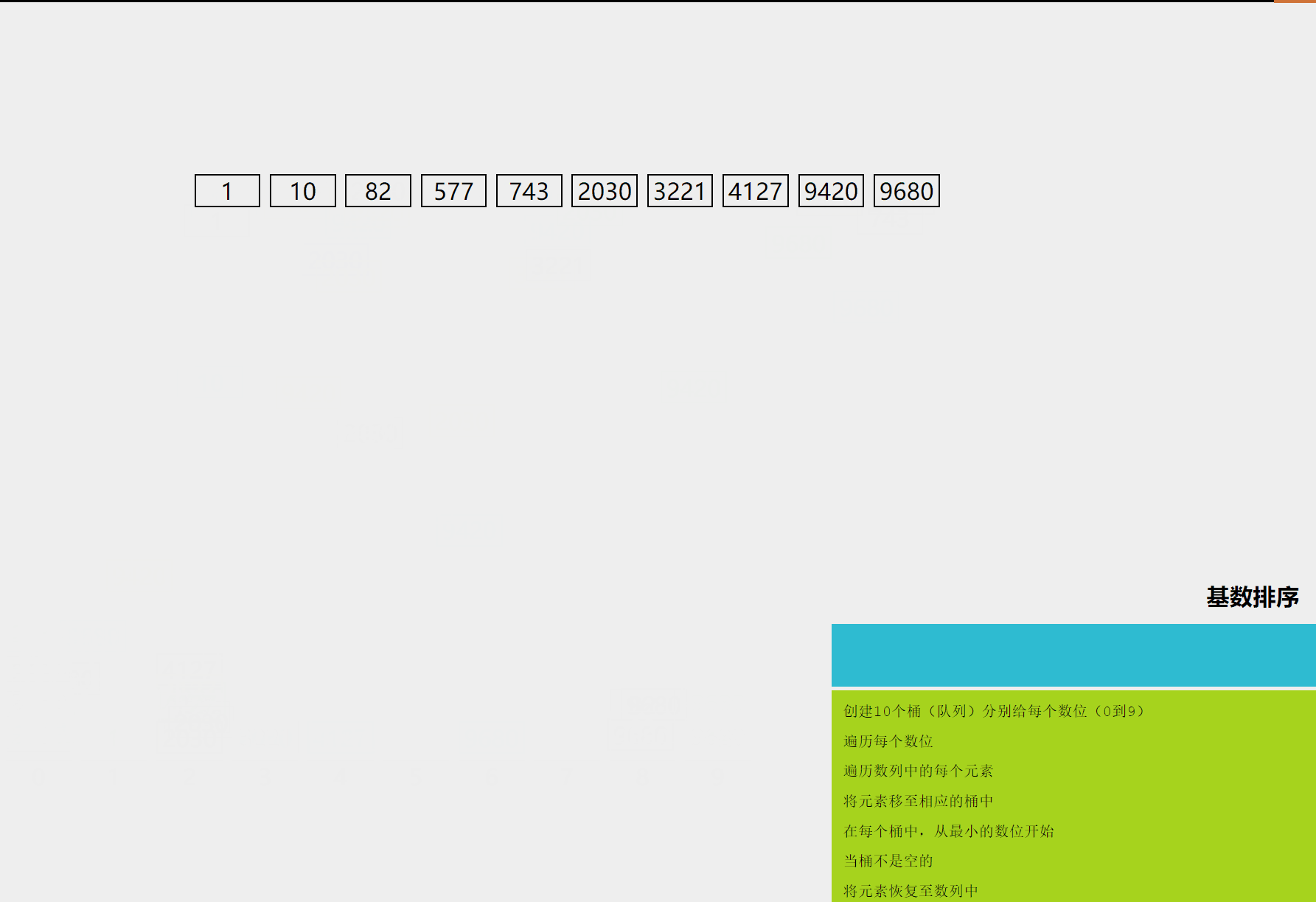
10.1 算法描述
- 取得数组中的最大数,并取得位数,这就确定了我们最多要判断多少位。
- 将待排元素按照个位进行分桶;然后将这些桶中的元素按桶的编号重新串接起来,得到以个位排序完成的序列。
- 再对序列按照十位进行分桶,然后将这些桶中的元素按桶的编号重新串接起来,得到以十位排序完成的序列。
- 以此类推,一直到最高位进行分桶并且重新串接,最后得到完整排序的序列。
10.2 动图演示

10.3 代码实现
1 | private static void radixsSort(int[] array) { |
10.4 算法总结
假设待排序的数组R[1..n],数组中最大的数是d位数,基数为r。那么每处理一位数,就需要将数组元素映射到r个桶中,映射完成后还需要收集,相当于遍历一遍桶+遍历一遍数组,最多元素数为n,则处理一位数的时间复杂度为O(n+r)。处理d位数的总的时间复杂度为O(d*(n+r))。
基数排序的空间复杂度为O(n+r),n表示n个指针,用来给桶内的元素做后驱指向,r则是开辟了长度为r的队列,用来当做r个桶。
基数排序基于分别排序,分别收集,所以是稳定的。
基数排序算法适用于位数不多,待排序列最大位数不是特别大,每一位数的范围不大的情况下(当然对于数字排序,每一位的范围都是[0,9])。