1. 循环依赖
循环依赖其实就是循环引用,也就是两个或则两个以上的bean互相持有对方,最终形成闭环。比如A依赖于B,B依赖于C,C又依赖于A。如下图:
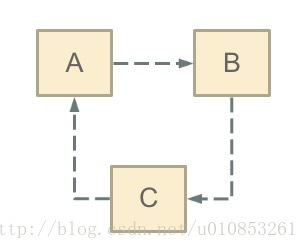
注意,这里不是函数的循环调用,是对象的相互依赖关系。循环调用其实就是一个死循环,除非有终结条件。
循环依赖就是N个类中循环嵌套引用,如果在日常开发中我们用new 对象的方式发生这种循环依赖的话程序会在运行时一直循环调用,直至内存溢出报错。
2. Spring循环依赖的场景
常规Java的循环依赖有两个场景:
- 构造器的循环依赖。
- field属性的循环依赖。
如果是Spring的依赖注入场景的话,field属性的循环依赖还可以分为
- 单例bean的循环依赖(scope=singleton)
- 非单例bean的循环依赖(scope=prototype)。
2.1 构造器的循环依赖
构造器的循环依赖代码如下:
1 |
|
我们如果启动Spring的初始化流程,最后执行得到的报错是:
1 | Caused by: org.springframework.beans.factory.BeanCurrentlyInCreationException: |
2.2 属性的循环依赖
属性的依赖,我们都知道是Spring利用反射,调用了对应属性的setter方式进行注入的。
2.2.1 单例属性的循环依赖
我们知道,Spring中@Service和@Autowired注解都是默认的单例模式,即scope=singleton。
1 |
|
结果:项目启动成功。
2.2.1 原型属性的循环依赖
ok,单例属性的循环依赖是被允许的,那么原型模式呢?我们添加一个scope=prototype的注解:
1 |
|
结果:项目启动失败,发现了一个cycle:
1 | Caused by: org.springframework.beans.factory.BeanCurrentlyInCreationException: |
3 原因分析
3.1 bean的初始化
在Spring中,同样对于循环依赖的场景,构造器注入和prototype类型的属性注入都会初始化Bean失败。只有单例的属性注入是可以成功的,这是为什么呢?
原因就藏在Spring IOC的源码中。
我们知道Bean的初始化流程如下图所示:
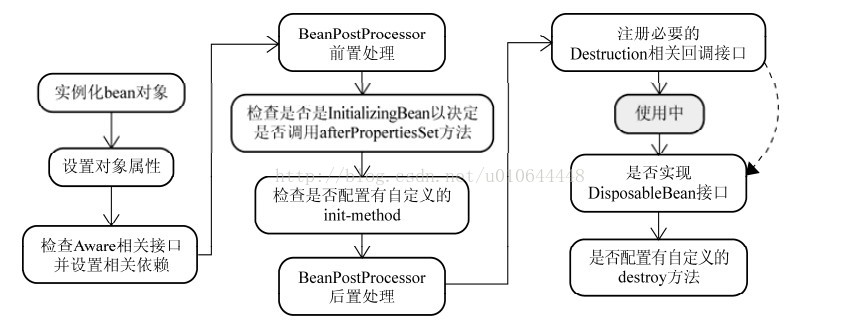
这里面最重要的是如下三步:
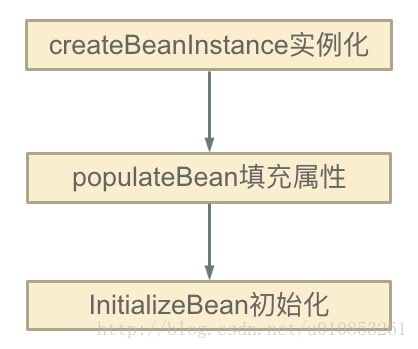
分别对应Spring源码中的这三个方法:
createBeanInstance()方法:实例化,其实也就是调用对象的构造方法实例化对象,或者说Spring利用反射,new了一个对象。
populateBean()方法:填充属性,这一步主要是多bean的依赖属性进行填充。
initializeBean()方法:调用spring xml中的init方法,不过这个和循环依赖无关,我们不多解释。
可以看到,Spring是先将Bean对象实例化之后再设置对象属性的。
3.2 三级缓存
我们知道了在Spring中对象实例化和对象属性填充是分成两步来操作的,为了解决循环依赖,Spring内部维护了三个Map,也就是我们通常说的三级缓存。
笔者翻阅Spring文档倒是没有找到三级缓存的概念,可能也是本土为了方便理解的词汇。
三级缓存在DefaultListableBeanFactory类中(继承自其父类DefaultSingletonBeanRegistry):
1 | /** Cache of singleton objects: bean name --> bean instance(缓存单例实例化对象的Map集合) 一级缓存*/ |
因为在Spring中,对象实例化和对象属性填充是分成两步来操作的,那么很显然,一个bean可以被分成两个阶段,名字是我自己取的:
- 胚胎阶段:即已经new出了一个对象,但是还没完成populateBean()方法,依赖的属性还未填充完毕的阶段。
- 成熟阶段:即完成populateBean()方法,依赖的属性已经填充完毕的阶段,此时对象就已经是一个成熟的对象了。
所以对应的,不同阶段的bean,会被存放在不同级别的缓存中,三级缓存因此而来:
- singletonFactories:三级缓存,保存胚胎阶段对象的工厂类。
- earlySingletonObjects:二级缓存,保存胚胎阶段的对象。
- singletonObjects:一级缓存,俗称单例池或者容器。构造完成的成熟阶段的单例对象都在里面。
这三个缓存中,三级缓存和循环依赖息息相关,那么Spring如何利用三级缓存来解决循环依赖呢?我们来理一下整个初始化bean的全过程。
Spring初始化容器对象的代码在org.springframework.context.support.AbstractApplicationContext#refresh()中方法,它调用finishBeanFactoryInitialization(beanFactory)方法,进而调用了org.springframework.beans.factory.support.DefaultListableBeanFactory#preInstantiateSingletons()方法,该方法顾名思义,负责遍历注册的beanName,依次初始化所有非懒加载的单例bean。
1 | public void preInstantiateSingletons() throws BeansException { |
AbstractBeanFactory.getBean(beanName)是核心方法,它调用的是AbstractBeanFactory.doGetBean(beanName)方法,初始化bean的逻辑就在其中。
1 | ("unchecked") |
其中,重点的方法DefaultSingletonBeanRegistry.getSingleton(beanName),我们可以看下逻辑:
1 | protected Object getSingleton(String beanName, boolean allowEarlyReference) { |
doGetBean()方法里面逻辑很多,我们简单描述其调用堆栈(只列出和循环依赖相关的堆栈):
- 1 DefaultSingletonBeanRegistry.getSingleton(beanName)
- 1.1【尝试从一级缓存取中bean,如果取到就返回】
- 1.2【如果取不到,就加锁,从二级缓存取,如果取到就返回】
- 1.3【如果取不到,再从三级缓存中取到ObjectFactory对象,如果取到了】
- 1.3.1 ObjectFactory.getObject() // 通过factory类获取bean对象
- 1.3.2【从三级缓存中删除该bean的工厂类,并将得到的bean对象加入二级缓存】
- 1.4【如果取不到ObjectFactory对象,返回null】
- 2 【如果getSingleton(beanName)返回的null】
- 【如果该bean是单例】
- DefaultSingletonBeanRegistry.getSingleton(beanName,factory) // 该方法负责实例化bean。factory的getObject()调用createBean
- ①【将当前bean放入singletonsCurrentlyInCreation这个Set中,表示该bean正在创建】
- ② ObjectFactory.getObject() // 调用工厂方法,获取bean对象
- AbstractAutowireCapableBeanFactory.createBean() // 创建对象
- AbstractAutowireCapableBeanFactory.doCreateBean() // 实际方法
- ⑴ AbstractAutowireCapableBeanFactory.createBeanInstance()
- AbstractAutowireCapableBeanFactory.instantiateBean() // 实例化bean
- ⑵ 【如果当前bean是创建中的(当前bean是否在singletonsCurrentlyInCreation中来判断)单例bean,且Spring配置支持循环依赖】
- DefaultSingletonBeanRegistry.addSingletonFactory() // 将bean加入三级缓存。factory的getObject()调用getEarlyBeanReference
- ⑶ AbstractAutowireCapableBeanFactory.populateBean() // 填充依赖的属性
- AutowiredAnnotationBeanPostProcessor.postProcessPropertyValues() // 对属性进行赋值
- AutowiredAnnotationBeanPostProcessor.AutowiredFieldElement.inject() // 依赖注入
- AbstractBeanFactory.getBean(B)
- …
- …
- …
- AbstractBeanFactory.getBean(B)
- AutowiredAnnotationBeanPostProcessor.AutowiredFieldElement.inject() // 依赖注入
- AutowiredAnnotationBeanPostProcessor.postProcessPropertyValues() // 对属性进行赋值
- ⑴ AbstractAutowireCapableBeanFactory.createBeanInstance()
- AbstractAutowireCapableBeanFactory.doCreateBean() // 实际方法
- AbstractAutowireCapableBeanFactory.createBean() // 创建对象
- ③【将当前bean从singletonsCurrentlyInCreation这个Set中删除,表示该bean完成创建】
- ④【将当前bean加入一级缓存中,并且在二级三级缓存中删除该bean】
- DefaultSingletonBeanRegistry.getSingleton(beanName,factory) // 该方法负责实例化bean。factory的getObject()调用createBean
- 【如果该bean是单例】
如果populateBean()方法中A bean依赖了B bean,那么就会进入AbstractBeanFactory.getBean(B)的逻辑,于是,整个流程如下图:

3.3 三种循环依赖的总结
所以我们可以看到,单例的属性注入流程中有两个重点,就是这两个点,解决了循环依赖:
提前曝光,如果用c语言的说法就是将指针曝光出去,用java就是将引用对象曝光出去。也就是说即便a对象还未创建完成,但是在实例化过程中new A()动作完成后,A bean就已经被放进了缓存之中,接下来B bean就可以引用的到。
已经了解了提前曝光的作用,而相比而言曝光的时机也非常的重要,该时机发生在实例化之后,填充属性初始化之前。
正是因为属性注入(或者说set方法注入)时,实例化和初始化是分开的两步,所以才能让Spring有可乘之机,在这两个步骤之间做提前曝光,这才有了Spring能够支持set方法注入时循环依赖的结论。
而构造器的循环依赖Spring之所以不支持,也正是因为此时实例化和初始化是原子的一个步骤,没有办法在中间插入提前曝光的机会。
构造器注入的报错如下图:
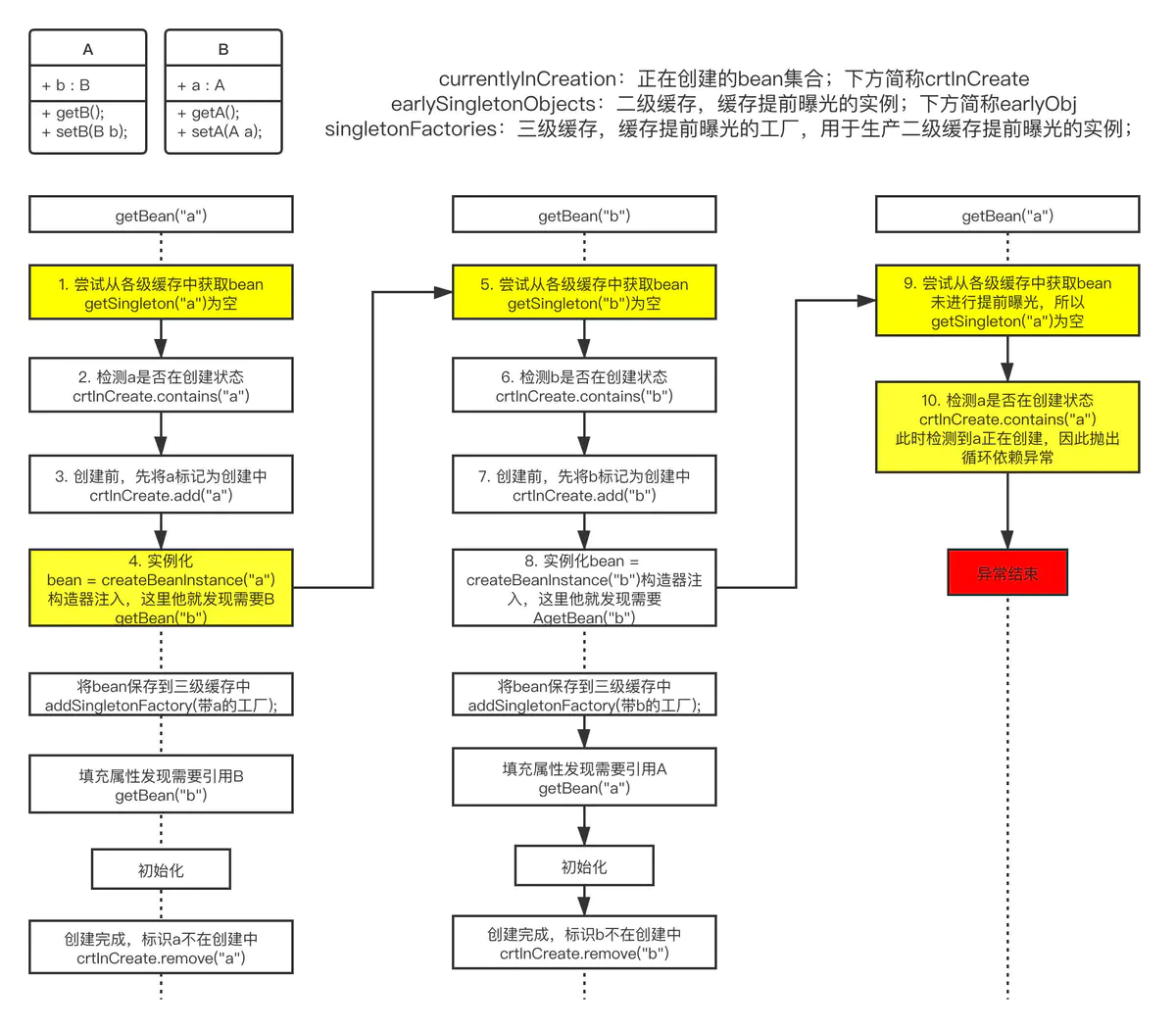
至于原型模式下的循环依赖,其实很好理解,因为原型模式每次都是重新生成一个全新的bean,根本没有缓存一说。这将导致实例化A完,填充发现需要B,实例化B完又发现需要A,而每次的A又都要不一样,所以死循环的依赖下去。
唯一的做法就是利用循环依赖检测,发现原型模式下存在循环依赖并抛出异常。
AbstractBeanFactory工厂类有个Set,叫做prototypesCurrentlyInCreation,它和前文中描述的singletonsCurrentlyInCreation一样,用来存放正在创建中的bean对象,只不过前者存的是原型模式的bean,后者存的是单例模式的bean。
Spring会在实例化prototype bean后将其放入prototypesCurrentlyInCreation中,如果有循环依赖,就会检查被依赖的bean是否也在prototypesCurrentlyInCreation中,如果是,那就表示依赖的bean和被依赖的bean同时在创建中,那就发生了循环依赖,这是不允许的。
1 | if (isPrototypeCurrentlyInCreation(beanName)) { |
3.4 为什么要有三级缓存
经过前文的叙述,我们貌似发现,三级缓存和二级缓存,貌似作用有点重复,两级缓存不够吗,一级缓存不够吗?为什么要用三级缓存?
只用一级缓存肯定不行,这很好理解,一级缓存的问题在于,就一个map,里面既有完整的bean,也有不完整的,尚未设置属性的bean。如果这时候,有其他线程获取到了不完整的bean,并且对还是null的属性做操作,那就直接空指针了。
那么两级缓存够吗?其实是够的,IoC循环依赖,两级缓存就够用了。
但是,如果参与循环依赖的A和B中,至少有一个对象有AOP切面呢?(AOP切面会动态生成一个代理对象,依赖注入的实际上得是代理对象才行)
在考虑有AOP动态代理对象存在的情况下,两级缓存就不够用了,假设我们给A加了个切面,Spring给A生成了一个动态代理对象A_Proxy。
如果只有两级缓存,一级缓存放完成初始化的bean,二级缓存放提前曝光的早期bean。那么
- A完成实例化之后将引用提前曝光至二级缓存,并开始初始化B,
- B发现要依赖A,就会从二级缓存中取出A对象,注入属性。此时B就会错误的引用了A,而不是Spring希望的引用A_Proxy。
那三级缓存就能解决这个问题么?可以的,还记得我们的第三级缓存存放的是工厂类ObjectFactory。当三级缓存命中的时候,我们是调用ObjectFactory.getObject()来获取对象的,而getObject()实际调用的又是各个beanPostProcessor的getEarlyBeanReference()方法:
1 | addSingletonFactory(beanName, new ObjectFactory() { |
其中,主要就是AOP的主力beanPostProcessor,AbstractAutoProxyCreator#getEarlyBeanReference:
1 | protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) { |
在看SmartInstantiationAwareBeanPostProcessor的getEarlyBeanReference():
1 | public Object getEarlyBeanReference(Object bean, String beanName) throws BeansException { |
这就能保证如果有动态代理的情况,那么从三级缓存取出来的对象,就会是代理对象A_Proxy。
我们把doCreateBean的流程串起来走一下,只列出相关的代码,并假设A和B循环依赖,且A有AOP切面,我们称原始的A为A_Origin,A的代理对象为A_Proxy:
1 | protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final Object[] args) { |
读到这里,也许有人会问,就算只使用两级缓存,我如果在A实例化后,紧接着就调用getEarlyBeanReference()方法去创建切面,然后将生成的A_Proxy放入二级缓存行不行?这不是又可以避免代理对象的问题,又只需要两级缓存吗?
答案是:理论上,是的,可以,但性能不好。
因为Spring中循环依赖出现场景很少,我们没有必要为了解决系统中那1%可能出现的循环依赖问题,而让99%的bean在创建时都去调用getEarlyBeanReference()走上这么一圈。大部分bean调用getEarlyBeanReference(),只会徒增判断逻辑,而没有实质的作用,他们既没有切面,也没有配置相关的BeanPostProcessor类。
使用三级缓存,就可以让确实有循环依赖场景的bean才会去调用getEarlyBeanReference()。因为只有有循环依赖场景的bean,才会用到二三级缓存。
而正常的bean都是
实例化——加入三级缓存——注入属性——执行init方法——执行BeanPostProcessor的方法——加入一级缓存——删除三级缓存——完成初始化
这样的流程。三级缓存的增删,只是一个以防万一而已。